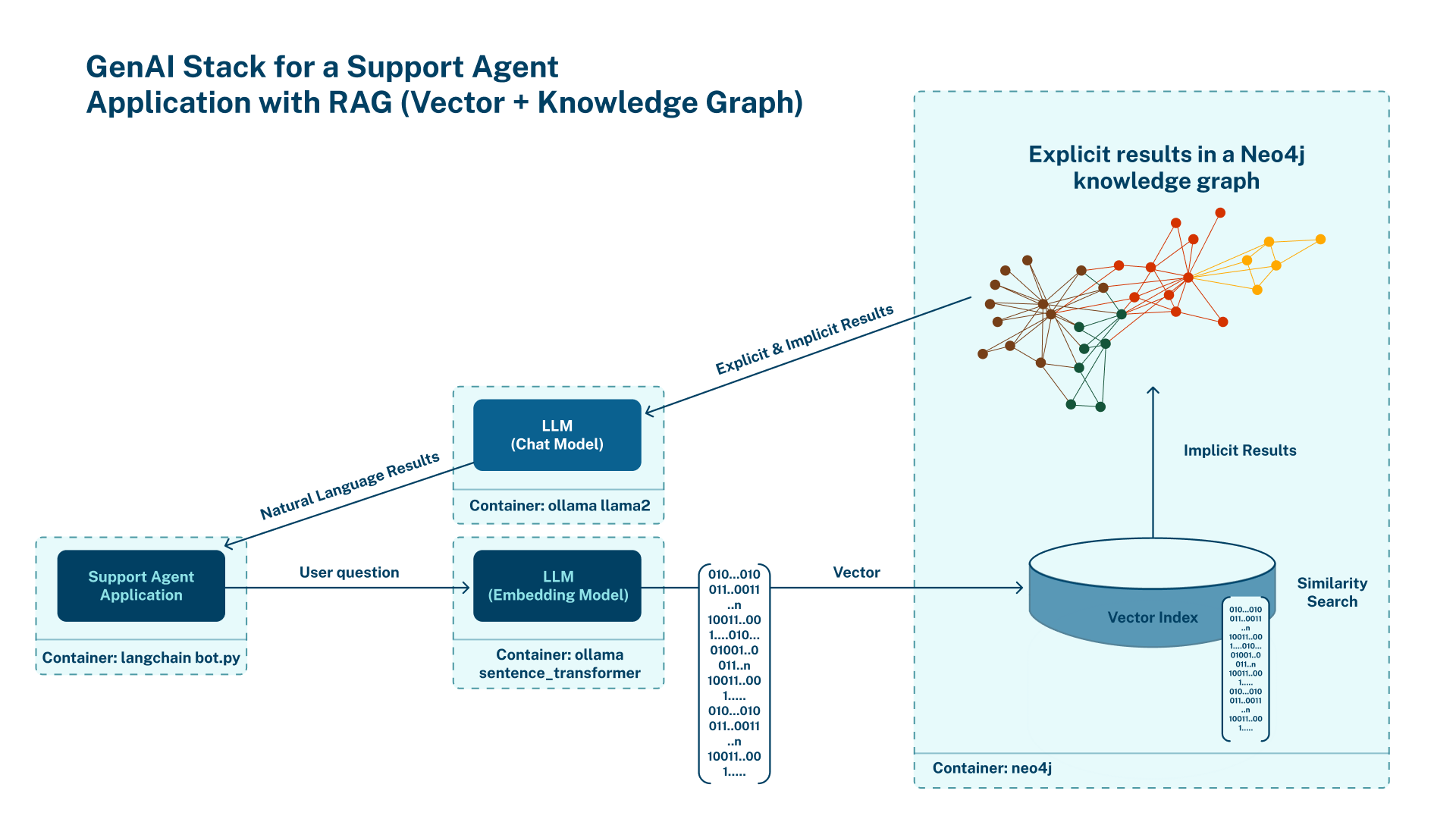
Experiment on PDF Document Ingestion Pipeline

In this article, I will demonstrate and share the procedures to use unstructured.io for PDF document parsing, extracting, and ingestion into the Neo4j graph database for GenAI applications.
The code is available in my GitHub repo.
Overview of unstructured.io
In my previous article, I demonstrated how to use LLMSherpa for PDF document parsing, extraction, and Python code to ingest results into Neo4j graph database.
Building A Graph+LLM Powered RAG Application from PDF Documents
This time, let’s take a look at another powerful tool: unstructured.io.
unstructured.io specializes in providing open-source libraries and APIs to build custom preprocessing pipelines, particularly for labeling, training, or production of unstructured data in machine learning projects.
unstructured.io has extensive file type support and precise extraction capabilities through its integrated inference pipeline. The inference pipeline operates by finding text elements in a document page using a detection model, then extracting the contents of the elements using direct extraction (if available), OCR, and, optionally, table inference models. Detection models that come with the default package include Detectron2 and YOLOX.
Data Processing Functions
unstructured.io provides a suite of core functionalities critical for efficient data processing:
- Partitioning — The partitioning capabilities are designed to extract structured information from raw, unstructured text documents effectively. This functionality is key in converting disorganized data into a format that’s ready for use, facilitating more efficient data handling and analysis processes.
- Cleaning — These functions significantly enhance the efficiency of NLP models. Ensuring data cleanliness is vital for preserving the accuracy and reliability of the data as it moves through subsequent stages of processing and application.
- Extracting — This feature is designed to pinpoint and extract specific entities from documents, streamlining the process of identifying and separating essential information. It simplifies the task for users, allowing them to concentrate on the most relevant data within their documents.
- Staging — Staging functions help prepare data for ingestion into downstream systems (e.g., a knowledge graph).
- Chunking — Unlike traditional methods, which solely focus on textual characteristics to create chunks, chunking leverages a comprehensive understanding of document structures. This method enables the partitioning of documents into meaningful segments or document elements, enhancing the semantic understanding of the content.
- Embedding — In unstructured.io, the embedding encoder classes use the document elements identified during partitioning or grouped through chunking to generate embeddings for each element.
Now let’s walk through more details of steps 1–3.
Preparation
1. Install unstructured.io
The sample project deployed the unstructured.io package locally by following the instructions. For a quicker start, you may choose to use the API Services instead.
2. Neo4j AuraDB for Knowledge Store
Neo4j AuraDB is a fully managed cloud service provided by Neo4j, offering the popular graph database as a cloud-based solution. It’s designed to provide the powerful capabilities of the Neo4j graph database without the complexity of managing the infrastructure. AuraDB has a free tier to experiment and try out its features. For detailed steps to create your own instance, check out the documentation.
KGLoader for unstructured.io
Partition
Partitioning functions are the core to extracting structured content from a raw, unstructured document. These functions break a document down into elements such as Title, NarrativeText, and ListItem. To partition a PDF document, it just requires one line of code:
elements = partition_pdf(filename=doc_location+"/"+doc_file_name,
infer_table_structure=True
)By default, infer_table_structure is False so that the process runs much faster. When set to True, the hi_res (high-resolution) strategy will be used to analyze document layout using the Detectron2 package.
Mapping Elements to Graph
Below are the mappings implemented. On the left is the element type returned in the Partition process, and on the right is the Node label in Neo4j.
Title -> Section
NarrativeText or ListItem or UncategorizedText or Header -> Chunk
Table -> Table
Image -> Image
For the sample PDF file, LayoutParser: A Unified Toolkit for Deep
Learning Based Document Image Analysis, below is its layout of the first page.

And below is what’s loaded into Neo4j (Table 1).
╒═══════════════════╤══════════╤═══════════╤══════════════════════════════════════════════════════════════════════╕
│tag │x.page_idx│x.block_idx│text │
╞═══════════════════╪══════════╪═══════════╪══════════════════════════════════════════════════════════════════════╡
│"Header" │1 │0 │"1 2 0 2 n u J 1 2 ] V C . s c [" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"UncategorizedText"│1 │1 │"2 v 8 4 3 5 1 . 3 0 1 2 : v i X r a" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"Title" │1 │2 │"LayoutParser: A Unified Toolkit for Deep Learning Based Document Image│
│ │ │ │ Analysis" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"NarrativeText" │1 │3 │"Zejiang Shen! (4), Ruochen Zhang”, Melissa Dell?, Benjamin Charles Ge│
│ │ │ │rmain Lee*, Jacob Carlson’, and Weining Li>" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"NarrativeText" │1 │4 │"1 Allen Institute for AI shannons@allenai.org 2 Brown University ruoc│
│ │ │ │hen zhang@brown.edu 3 Harvard University {melissadell,jacob carlson}@f│
│ │ │ │as.harvard.edu 4 University of Washington bcgl@cs.washington.edu 5 Uni│
│ │ │ │versity of Waterloo w422li@uwaterloo.ca" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"NarrativeText" │1 │5 │"Abstract. Recent advances in document image analysis (DIA) have been │
│ │ │ │primarily driven by the application of neural networks. Ideally, resea│
│ │ │ │rch outcomes could be easily deployed in production and extended for f│
│ │ │ │urther investigation. However, various factors like loosely organized │
│ │ │ │codebases and sophisticated model configurations complicate the easy re│
│ │ │ │use of im- portant innovations by a wide audience. Though there have b│
│ │ │ │een on-going efforts to improve reusability and simplify deep learning │
│ │ │ │(DL) model development in disciplines like natural language processing│
│ │ │ │ and computer vision, none of them are optimized for challenges in the│
│ │ │ │ domain of DIA. This represents a major gap in the existing toolkit, a│
│ │ │ │s DIA is central to academic research across a wide range of disciplin│
│ │ │ │es in the social sciences and humanities. This paper introduces Layout│
│ │ │ │Parser, an open-source library for streamlining the usage of DL in DIA│
│ │ │ │ research and applica- tions. The core LayoutParser library comes with│
│ │ │ │ a set of simple and intuitive interfaces for applying and customizing│
│ │ │ │ DL models for layout de- tection, character recognition, and many oth│
│ │ │ │er document processing tasks. To promote extensibility, LayoutParser a│
│ │ │ │lso incorporates a community platform for sharing both pre-trained mod│
│ │ │ │els and full document digiti- zation pipelines. We demonstrate that La│
│ │ │ │youtParser is helpful for both lightweight and large-scale digitizatio│
│ │ │ │n pipelines in real-word use cases. The library is publicly available │
│ │ │ │at https://layout-parser.github.io." │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"NarrativeText" │1 │6 │"Keywords: Document Image Analysis · Deep Learning · Layout Analysis ·│
│ │ │ │ Character Recognition · Open Source library · Toolkit." │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"Title" │1 │7 │"Introduction" │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
│"NarrativeText" │1 │8 │"Deep Learning(DL)-based approaches are the state-of-the-art for a wid│
│ │ │ │e range of document image analysis (DIA) tasks including document imag│
│ │ │ │e classification [11," │
├───────────────────┼──────────┼───────────┼──────────────────────────────────────────────────────────────────────┤
... ... ... ...The document graph schema is shown below.
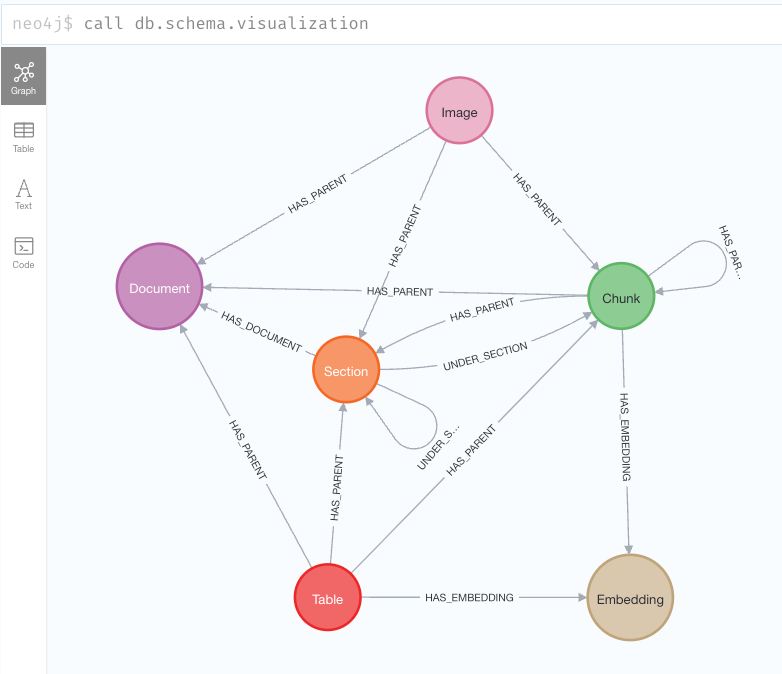
Some findings to summarize:
- The Partition process will return all recognizable elements in the PDF doc and suggest a category for each of them (e.g., NarrativeText or Title).
- Different for LLMSherpa, discussed in the last article, the Partition process doesn’t always put Section at the direct child level of Document. In fact, any element can be the direct child of Document. Meanwhile, Section can be direct child of another section, as well as a Chunk too. However, for this PDF file, LLMSherpa failed to extract complete contents.
- Sentence is broken into two chunks if it is across the pages. This will cause an issue for embedding and search.
- Page header, page number, and other unwanted contents are not recognized consistently.
- The same text seen in the page header was recognized sometimes as the same element and other times as separate elements.
Traversing Document Graph
Even though the Partition process has produced a document graph of a much more freestyle structure, thanks to the highly flexible schema of property graph and powerful traversal capability of Cypher, Neo4j’s graph query language, we can still bring up all contents ingested (as seen in Table 1) using the following query:
MATCH (d:Document)
WITH d
CALL apoc.path.subgraphNodes(d,{
relationshipFilter:'<HAS_DOCUMENT|<HAS_PARENT|<UNDER_SECTION'
,bfs:FALSE
}
) YIELD node
WITH node AS x
RETURN coalesce(x.tag, labels(x)[1]) AS tag, x.page_idx, x.block_idx, coalesce(x.title, x.sentences) AS text
ORDER BY x.page_idx ASC, x.block_idx ASC;Here, I used a procedure in the APOC library, subgraphNodes(), to traverse all child nodes of a document by specifying the following rules:
- Depth-first order: bfs:FALSE. By default, Cypher query traverse graph in the breadth-first Order.
- For HAS_DOCUMENT, HAS_PARENT, or UNDER_SECTION relationships only, and always traverse when relationship direction is incoming (annotated using <).
- Only return nodes to save I/O resources and time.
- Order results by page number and block_idx.
Further Discussion
With both textual and structural data ingested into a knowledge graph using unstructred.io, it can enhance the efficiency, accuracy, and contextual relevance of Retrieval-Augmented Generation (RAG) systems, making them more effective in processing and generating information based on large and complex text sources.
If you’d like to explore this idea further, check out the following articles.
Integrating unstructured.io with Neo4j AuraDB to Build a Document Knowledge Graph was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.