A Neo4j Birthday Gift to an Old-Timer
The Commodore 64 celebrates its 42nd anniversary in August. And being the answer to the Ultimate Question of Life, the Universe and Everything, I felt it was time to give it the ultimate birthday gift: A Neo4j client.
Haven’t you always wanted to run Neo4j on a Commodore 64?
No? Really? That is something that I have always wanted — well, for as long as I can remember, anyway (at least a couple days).

Anyway, that is exactly what we will do. I mean, we won’t run the full Neo4j server on a Commodore 64. It may be the best piece of silicon ever made, but it still doesn’t make a lot of sense to run a database server on 64K RAM (even with a 170K floppy disk attached). And though there are (limited) JVM implementations for the 6502 processor, getting Neo4j to run on it is not something I want to try. What I mean is that we will implement a Neo4j client for the C64 — sort of a Cypher Shell 64.

You may ask, “Why would one want to do that?” And I guess “because you can” or “because it’s fun” aren’t sufficient answers. I can think of a very practical reason: With 64KB of RAM (actually, only 4KB available for applications), the size of the games you could do on the C64 was limited, but imagine if you had the entire game world stored in Aura and you could make a huge adventure game on this old machine. Pretty cool, right?
However, the reason I did it might not have been with the goal of doing World of Warcraft C64 version, but rather that I wanted to familiarize myself with Neo4j’s Bolt protocol. At the university, we had a compiler course where we wrote our own compiler, and a classmate asked the teacher, “Why are we doing this? Very few of us, if any, will ever work on writing compilers.” What the teacher replied, and which I have experienced many times, is that when using technology that simplifies things, like a compiler or a device driver, it’s good to have an idea of how those work, at least when you start doing more advanced things. So doing a simple Bolt implementation is good for the understanding of the driver, and why not do it in a fun way rather than making yet another Java driver?
Tools
The first thing we need to do is to select what tools to use. And the first tool choice to make is what language to use.
At the time of the Commodore 64 (the mid-1980s), it seemed like there were only two choices for a home computer like this: BASIC or Machine code/Assembler. I wouldn’t attempt this in BASIC, so my first thought went to Assembler, but I fortunately gave up that idea quickly and instead decided to go with C.
Now we need a compiler, and there is one for the 6502 family called CC65. It has some limitations. There are missing functions — scanf(), for example, because they are complex and would alone consume most of the available memory. It also lacks support for floats and doubles. The 6502 doesn’t support floats natively, but there is also no software implementation in the compiler. This is good enough for us though, but we need to skip support for floats, and unfortunately, we had to implement our own input method due to the lack of scanf():
// scanf isn't implemented/working in CC65, so we have done our own simple input routine
void input(char* destination, int limit)
{
int c, i;
i = 0;
cursor(1);
while (i < limit)
{
c = cgetc();
if (c == 0x11 || c == 0x1D || c == 0x91 || c == 0x9D) // Arrows - disable
{
continue;
}
printf("%c", c);
if (c == 0x0D) // ENTER - accept
{
break;
}
else if (c == 0x14) // INST/DEL - special
{
if (i > 0)
{
i--;
}
}
else
{
destination[i++] = c;
}
}
destination[i] = 0;
cursor(0);
}
It should be noted that CC65 follows the C89 standard, with just some C99 features (plus some features of its own) added. For example, you can do // comments as in C99, but you still need to define variables at the start of the scope as in C89.
The Commodore 64 is an 8-bit computer, and thus endianness isn’t something we normally have to consider. But CC65 handles bigger datatypes, and those are little endian. But network protocols are usually big endian, like Bolt, so we need our own functions to create the bigger data types from a byte array:
// Parses a big-endian 16 bit integer from a byte array
uint16_t parseInt16(char* data)
{
return (uint16_t)data[0] << 8 | data[1];
}
// Parses a big-endian 32 bit integer from a byte array
uint32_t parseInt32(char* data)
{
return (uint32_t)data[0] << 24 | (uint32_t)data[1] << 16 | (uint32_t)data[2] << 8 | data[3];
}
Next thing we need is a TCP/IP stack. When the C64 came out in 1982, TCP/IP hadn’t even been made a standard yet (it was made a standard in 1985), so there is no support for it in the OS, and the C64 didn’t support upgrading the OS (it was on ROM). I found a TCP/IP implementation called IP65 for the CC65 compiler. It works well, but the API is very different from the traditional socket APIs.
We also need a network card. Of course there isn’t one embedded in the C64, nor were there any off-the-shelf variants at the time. There are some options now, though. I have gone with one called RRNet, which is supported by IP65 and is emulated by the VICE C64 emulator (it’s a bit tricky to get working in the emulator, though).

Design Decisions
I stand firm in my statement that this is the best computer ever made. Though I guess I have to admit that it had some limitations; the memory might — in some cases — be, well, somewhat limited.
Coding Restrictions
The first thing I decided was not to use malloc() at all. Dynamically allocating memory means less control, and we would likely quickly run out of the few bytes available. Instead, I allocated fixed-size buffers for the communication. That way we know what we have to play with.
I decided to have one buffer for bytes received and one for building messages to be sent (that one is also reused for unpacking incoming messages). I started by making them 256 bytes each, but I realized quickly that error messages often exceed that. So I made them 512 bytes, which worked better for a while until the program grew bigger, and suddenly I was out of memory. But I kept them at 512 bytes each (1KB total) and trimmed the program a bit instead. So as it is, we use all the RAM, and just adding another if-statement somewhere will break it:
#define BUFFER_SIZE 512
char send_buffer[BUFFER_SIZE]; // The send_buffer is also used to store the full message received
char receive_buffer[BUFFER_SIZE];
char* message_send = &send_buffer[2]; // A pointer to where to write the message to send
char* message_receive = &send_buffer[0]; // A pointer to where to find the message read
With 512 bytes, it works for most incoming messages. However, if we query a long list of items, it might blow up after a while anyway. Because even if each message is below 512 bytes, we can’t read them quick enough, which causes the buffer to overflow.
The other restriction I decided on was not to use recursive function calls. Those are also a bit hard to control and will quickly consume RAM for the call stack. This one made the parsing of incoming messages a bit harder, but we’ll get to that later.
Other Limitations
One unfortunate — but I think necessary — limitation was that I am only supporting unencrypted communication. I wouldn’t want to implement OpenSSL on a Commodore 64. This means we cannot use this client with Aura (which shoots down one of my rationales), but at least we can use it with our own hosted instance. To keep the program small, I am only supporting basic authentication here.
Another limitation, which we have already discussed, is that we don’t support FLOAT for incoming values. We also haven’t implemented INT 64.
There are certain characters, like curly braces, that you cannot type on the C64, and others that we just don’t handle, as we will see.
There is no support for parameters, so don’t run a Cypher injection PEN test on this one.
All transactions are run as auto-commit transactions, and all queries are specified as write queries, even if they actually only read data.
We only support getting an IP number through DHCP, so no static IP assignment.
The Neo4j server must be specified with an IP number (I haven’t implemented host name lookup).
Implementation
The entire C code of this C64 client can be found at the bottom of this article.
Character Sets
When I started to test the first implementation of the driver, I couldn’t get it to work. I got failure replies from the server that I couldn’t understand. It said it missed the user_agent field, but I could clearly see that I sent it. Then it occurred to me that the C64 doesn’t use ASCII. It uses a character set called PETSCII, named after the first Commodore computer: the PET 2001 (1977).

PETSCII has regular characters and special graphical characters to allow more elaborate ASCII-art (sorry, I mean PETSCII-art) for games. It also exists in a regular “unshifted” mode, with just uppercase characters and more graphical characters; and a “shifted” mode with upper- and lowercase, but fewer graphical characters. When starting a CC65-compiled program, it always changes to the shifted mode, and we need both upper- and lowercase, so that’s what we’ll use.

PETSCII is very similar to ASCII, but there are differences. For one, the upper- and lowercase letters are reversed. Many special characters are the same, but it lacks some characters like curly braces and underscore. Instead of underscore, the CC65 compiler uses a graphical character that looks like an underscore. So when I thought I sent user_agent, I did, in fact, send USER¤AGENT.
So we need a converter, which you can see in the petscii_ascii_convert() function in the code at the bottom of the article. This method only handles what we absolutely need: upper- and lowercase conversion, the underscore, and repeated space characters (PETSCII has space as 0x20 just as ASCII, but also has non-breaking space as 0xa0 and 0xe0).
To preserve space, we will leave the rest of PETSCII alone. This is enough for what we need for the protocol. The negative effect is that sometimes error messages look a bit weird (when they use curly braces or ticks, for example). And you can’t use certain characters in string variables for your Cypher statements, but you wouldn’t be able to type those on a C64 anyway.
IP65 Communication
As mentioned, the IP65 API is rather different from the socket APIs we’re used to these days. One difference is that since nothing is managed by the OS, we need to initialize the network stack and assign an IP number, etc. ourselves, which is simple if we use DHCP:
if (ip65_init(ETH_INIT_DEFAULT))
{
error_exit();
}
if (dhcp_init())
{
error_exit();
}
printf("Local IP Addr: %s\n", dotted_quad(cfg_ip));
And to connect to a server on a specific IP and port:
if (tcp_connect(parse_dotted_quad(ipaddress), port, &read_callback))
{
error_exit();
}
IP65 has a tcp_send() function that takes a byte array and a size, just like the send()/write() functions when using sockets. There is, however, no recv()/read() like with sockets. Instead, we register a callback that will be called with bytes read, as you can see with the read_callback function pointer above.
This is, however, not as asynchronous as it may look. The callback may be called when you do something else, like tcp_send(), if there is data available. Otherwise, you have to call to a function called ip65_process() to see if there is data available and, if so, have the callback called.
I like the more synchronous approach of a blocking tcp_read(), so I had the callback write the data into the read buffer, then I have my own tcp_read() that waits until enough is available (while calling ip65_process()). Before reading, it shifts the buffer down with what has already been read:
// The callback for tcp_connect() that handles incoming bytes and writes them to com_buffer
void read_callback(const char* data, int16_t len)
{
if (response_length < BUFFER_SIZE)
{
if (response_length + len > BUFFER_SIZE)
{
len = BUFFER_SIZE - response_length;
}
memcpy(receive_buffer + response_length, data, len);
response_length += len;
}
}
// Blocking read that reads len bytes into receive_buffer
void tcp_read(int16_t len)
{
// We don't have a check to see if len is too long, since we do that in bolt_receive()
// Shift the buffer down if we had already read part of it before
if (read_pointer > 0)
{
response_length -= read_pointer;
// memcpy of overlapping arrays is undefined behavior in C,
// but this complier handles backward overlaps well
memcpy(receive_buffer, &receive_buffer[read_pointer], response_length);
}
while (response_length < len)
{
ip65_process();
}
read_pointer = len;
}
// Clears the read buffer
void clear_buffer()
{
response_length = 0;
read_pointer = 0;
}
Bolt Protocol
Now it’s time to implement the Bolt protocol. You can find the protocol specification below.
Bolt Protocol documentation – Bolt Protocol
This is the fun part, and the actual reason for all of this: to learn and understand at least the basics of the Bolt protocol and how Neo4j drivers work.
The first part when connecting to a Bolt server is a handshake, used to negotiate what Bolt version to use. It starts with a fixed-byte signature to indicate that we are connecting with Bolt:
60 60 B0 17
This is followed by a list of four Bolt versions (32 bits each) that we as client support. The server will respond with the one version we will use, in case it supports at least one of those we provided.
In our case, we will only claim to support Bolt 5.0. Because we are very RAM-restricted, we don’t want to implement variants for other versions, and 5.0 is supported by all Neo4j 5.x versions. Also, the authentication process requires one fewer message in 5.0 than in 5.1, which reduces the amount of code we need. Every byte counts.
// This includes both the initial handshake and the version exchange
// (we only implement protocol version 5.0,
// which should be supported by all Neo4j 5.x versions)
char handshake[] = {0x60, 0x60, 0xB0, 0x17, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00};
// Send handshake
tcp_send(handshake, sizeof(handshake));
// Wait for the 4 byte reply and validate it
tcp_read(4);
if (receive_buffer[3] != 0x05)
{
message_exit("Server version not supported");
}
Once this is established, the Bolt protocol will use a message syntax called PackStream, so we need functions for sending and receiving PackStream Bolt messages.
Bolt messages are sent as chunks. A message can be sent in one chunk, but can also be split over several. A chunk starts with a 16-bit length of the chunk, and once the last chunk of a message is sent, you send 00 00 to indicate that the next chunk is empty, and thus that the message is done.
The maximum size of a chunk is based on the 16-bit length field (65,535 bytes), and since our message buffer is 512 bytes, we know that we will never have to use more than one chunk when sending a message. This allows us to simplify the send method quite a bit. We have a pointer called message_send that points to the third byte of send_buffer, and we simply write the message starting at that pointer. When it’s time to send, we simply write the length to the first two bytes, and 00 00 to the two bytes following the message:
// Packs a bolt message contained in message_buffer into a chunk and sends it
void bolt_send(int16_t len)
{
// Since our buffer is limited to 512 bytes, we know we never have to use
// more than one chunk, and we also know that the most significant byte of
// the length is always 0
if(len > BUFFER_SIZE - 4)
{
message_exit("Message too long");
}
// Header
send_buffer[0] = 0;
send_buffer[1] = len;
// Message end
send_buffer[len+2] = 0;
send_buffer[len+3] = 0;
// Send chunk
tcp_send(send_buffer, len+4);
}
When receiving, we need to handle a message spanning multiple chunks, because even if the theoretic limit is 65,535, the server is allowed to chunk smaller messages. This means we need another buffer from the receive_buffer to unpack the incoming chunks into. Fortunately, we’re never sending when it comes to unpacking, so we can reuse the send_buffer. Here, the messages are unpacked from the first byte, and so we have a message_receive pointer, just like message_send, but that points to the first byte instead:
// Reads back a bolt reply and returns the length of it
// The message read can be found at message_receive
int bolt_receive()
{
// Since we can't handle messages longer than 512 bytes we shouldn't have to care about
// chunking when receiving either, but theoretically the server could chunk a shorter message,
// so we will. And to manage that we reuse the send_buffer to unpack the received message into
int l;
int message_reply_length = 0;
while (true)
{
tcp_read(2);
l = parseInt16(receive_buffer);
if (l == 0)
{
break;
}
if((l + message_reply_length) > BUFFER_SIZE)
{
message_exit("Reply too long");
}
tcp_read(l);
memcpy(send_buffer + message_reply_length, receive_buffer, l);
message_reply_length += l;
}
return message_reply_length;
}
For convenience — and to save code length and thus precious bytes — we have a function that sends and receives:
// Packs a bolt message contained in message_buffer into a chunk and sends it,
// and then reads back a bolt reply and returns the length of it
// The message read can be found at message_receive
int bolt_send_receive(int16_t len)
{
clear_buffer();
bolt_send(len);
return bolt_receive();
}
Now we need functions to pack the PackStream data into the Bolt message. There are a couple of those (I only implemented those I needed). All of these take a pointer to where in the message we are and returns where the message pointer is after adding that data segment. This allows us to have a macro that calculates the size of the message when we have added the last element:
#define message_length(m) ((m)-message_send)
Another convenient macro I did for these functions was to write a byte to an address pointer and increase the address pointer in one go:
#define set_byte(m,b) ((*(m++))=(b))
As you can see, I don’t have any safety mechanism in these pack methods if they cause the message to grow too big (bigger than 508 bytes). Having those would have added a lot of code and, with the exception of the query itself, I know what I put into the messages, so instead I just check the size of the query string in the execute_query() method:
// Starts a struct with a defined number of fields
// You need to manually add each field after this call
char* start_struct(char* message, char signature, char fields)
{
set_byte(message, 0xB0 + fields);
set_byte(message, signature);
return message;
}
// Starts a dictionary for a certain number of fields
// You need to manually add each key pair after this call
// (currently doesn't support dictionaries with more than 15 fields)
char* start_dictionary(char* message, char fields)
{
set_byte(message, 0xA0 + fields);
return message;
}
// Adds an int to the message
// Currently we only support tiny ints (-16 - 127) because
// it is all we currenlty use
char* add_int(char* message, int value)
{
if (value >= -16 && value <= 127)
{
set_byte(message, (char)value);
}
return message;
}
// Adds a string to the message (currently only supports up to 255 character strings)
char* add_string(char* message, char* value)
{
// Bolt strings are not null-terminated, so we don't include the null terminator here
int len = strlen(value);
if (len < 16)
{
set_byte(message, 0x80 + len);
}
else
{
set_byte(message, 0xD0);
set_byte(message, len);
}
memcpy(message, value, len);
petscii_ascii_convert(message, len);
return message+len;
}
// Adds an int key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_int(char* message, char* key, int value)
{
message = add_string(message, key);
message = add_int(message, value);
return message;
}
// Adds a string key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_string(char* message, char* key, char* value)
{
message = add_string(message, key);
message = add_string(message, value);
return message;
}
// Adds a dictionary key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_dictionary(char* message, char* key, int value_fields)
{
message = add_string(message, key);
message = start_dictionary(message, value_fields);
return message;
}
The functions above are one place where you really miss object orientation. For a struct or dictionary, we could simply pass an object of that sort, and we would know what length to write to the stream, then we would write those objects. Instead, we need to have a start_struct() and start_dictionary() to pass the number of elements, and then we need to make sure that we call the add_* functions exactly that many times. This gets a bit complex when we have nested structs and dictionaries.
Now we can implement the three messages we need: send_hello(), which is the first message we send and that handles authentication (up until Bolt version 5.0), execute_query(), and send_reset() (needed if there had been a failure reply to another message):
// Sends a Reset message (needed when the server is in a failed state)
int send_reset()
{
char* message = message_send;
message = start_struct(message, MESSAGE_RESET, 0);
bolt_send_receive(message_length(message));
return message_receive[0] == 0xB1 && message_receive[1] == MESSAGE_SUCCESS;
}
// Send the Hello message.
void send_hello(char* user_name, char* password)
{
int len;
char* message = message_send;
message = start_struct(message, MESSAGE_HELLO, 1);
message = start_dictionary(message, 4); // The main ("extra") dictionary
message = add_keypair_string(message, "scheme", "basic"); // Part of extra
message = add_keypair_string(message, "principal", user_name); // Part of extra
message = add_keypair_string(message, "credentials", password); // Part of extra
message = add_keypair_string(message, "user_agent", "C64/1.0.0"); // Part of extra
len = bolt_send_receive(message_length(message));
if (message_receive[0] != 0xB1 || message_receive[1] != MESSAGE_SUCCESS)
{
print_record(len);
message_exit("Authentication failure\n");
}
}
// Executes an auto-commit query (currently doesn't support parameters)
// Result is printed on standard out
void execute_query(char* query)
{
int len;
char* message = message_send;
if (strlen(query) > BUFFER_SIZE - 8)
{
printf("Query too long, cannot be sent\n");
return;
}
message = start_struct(message, MESSAGE_RUN, 3);
message = add_string(message, query);
message = start_dictionary(message, 0); // The "parameters" dictionary
message = start_dictionary(message, 0); // The "extra" dictionary
len = bolt_send_receive(message_length(message));
if (message_receive[0] != 0xB1 || message_receive[1] != MESSAGE_SUCCESS)
{
printf("Query execution failure\n");
print_record(len);
while (!send_reset())
{
printf("Retrying reset...");
}
return;
}
message = message_send;
message = start_struct(message, MESSAGE_PULL, 1);
message = start_dictionary(message, 1); // The main ("extra") dictionary
message = add_keypair_int(message, "n", -1); // Part of extra
len = bolt_send_receive(message_length(message));
while (message_receive[0] == 0xB1 && message_receive[1] == MESSAGE_RECORD)
{
print_record(len);
len = bolt_receive();
}
}
The final part we need in the Bolt implementation is the parsing of incoming messages. Apart from simply checking the status of incoming messages, which you can see done in each method above, where they are checked for MESSAGE_SUCCESS and MESSAGE_RECORD, the only parsing we do is to print the content of the messages. We don’t do any more advanced parsing of the content of the replies.
This is done in a function called print_record(), which is used in the above functions. This is a rather long method that handles all the data types of PackStream, so I won’t include it here again, but you can see it in the full code below. And since we aren’t using recursive function calls, we aren’t doing any fancy formatting of structs, dictionaries, and lists, like placing the elements within parentheses or something. Instead, it prints D(2), for example, to indicate that the next two items printed are part of that dictionary, which can be confusing with nested elements.
Cypher Shell C64 in Action
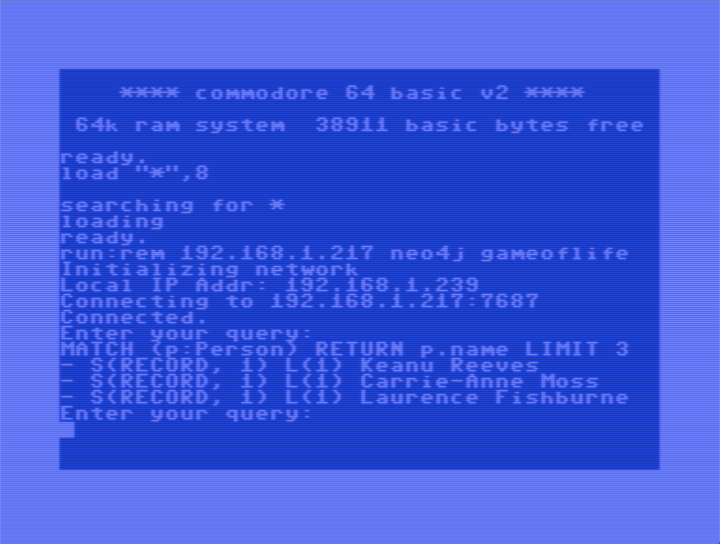
That’s it! We have our Commodore 64 Neo4j shell client. The program takes three or four arguments, the IP number of the server, the user name, the password and (optionally) the port number (defaulted to 7687).
One issue is that the C64 didn’t support command-line arguments. All you had to launch a program was the RUN command. But CC65 solves that in a clever way by adding a REM statement (i.e., a comment in BASIC) with the arguments after the RUN, so we run it with:
RUN:REM 192.168.1.217 neo4j gameoflife
Darn. Now I revealed my secret password. I guess I will have to switch back to 1234 now. Conway’s Game of Life was the first Neo4j program I wrote, and that’s why I had that as password for my local test server.
Once successfully connected, we can just start to type in Cypher commands that it will try to execute, and the result (or failure message) will simply be printed with the crude print_record() format we implemented, one row at a time.

Summary
I don’t know about you, but I feel I have a better grasp of Bolt now, and when asking the regular Java driver for a million records, I now know what happens behind the curtains. I have also gained a renewed appreciation for those who developed the games for the C64 back in the day — 64KB is, after all, less than 40 pages in a regular book (and 4KB is less than 2½).
Here is the full code of this Neo4j client, using only the CC65 compiler (with libraries) and the IP65 library:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <conio.h>
#include "../ip65-c64/ip65.h"
#define BUFFER_SIZE 512
#define MESSAGE_HELLO 0x01
#define MESSAGE_RESET 0x0F
#define MESSAGE_RUN 0x10
#define MESSAGE_PULL 0x3F
#define MESSAGE_SUCCESS 0x70
#define MESSAGE_RECORD 0x71
#define min(a,b) (((a)<(b))?(a):(b))
#define set_byte(m,b) ((*(m++))=(b))
#define message_length(m) ((m)-message_send)
char send_buffer[BUFFER_SIZE]; // The send_buffer is also used to store the full message received
char receive_buffer[BUFFER_SIZE];
char* message_send = &send_buffer[2]; // A pointer to where to write the message to send
char* message_receive = &send_buffer[0]; // A pointer to where to find the message read
int response_length = 0;
int read_pointer = 0;
// Converts between PETSCII and ASCII character sets
// Since the C programs always runs in shifted mode we only care about the shifted PETSCII
// This converter isn't complete, but it covers most of what we need
void petscii_ascii_convert(char* string, int len)
{
int i;
for (i = 0; i < len; i++)
{
// 0x20 - 0x40 are the same between the character sets, so we can skip those
// All upper and lower case is reversed between PETSCII and ASCII, so let's switch
if (string[i] > 0x40 && string[i] < 0x5b)
{
string[i] += 0x20;
}
else if (string[i] > 0x60 && string[i] < 0x7b)
{
string[i] -= 0x20;
}
// PETSCII also has a repeated set of upper case between 0xc1 and 0xda
else if (string[i] > 0xc0 && string[i] < 0xdb)
{
string[i] -= 0x80;
}
// PETSCII has space as both 0x20, 0xa0 and 0xe0 and it seems a bit random which
// one you get. We only ever want to use 0x20
else if (string[i] == 0xa0 || string[i] == 0xe0)
{
string[i] = 0x20;
}
// This covers most our use cases, but there is one more character we need
// to handle and that is the underscore
else if (string[i] == 0xa4)
{
string[i] = 0x5f;
}
else if (string[i] == 0x5f)
{
string[i] = 0xa4;
}
}
}
// Outputs an error code and exits
void message_exit(char* msg)
{
printf("- %s\n", msg);
exit(EXIT_FAILURE);
}
// Exit due to a com failure
void error_exit()
{
message_exit(ip65_strerror(ip65_error));
}
// The callback for tcp_connect() that handles incoming bytes and writes them to com_buffer
void read_callback(const char* data, int16_t len)
{
if (response_length < BUFFER_SIZE)
{
if (response_length + len > BUFFER_SIZE)
{
len = BUFFER_SIZE - response_length;
}
memcpy(receive_buffer + response_length, data, len);
response_length += len;
}
}
// Blocking read that reads len bytes into receive_buffer
void tcp_read(int16_t len)
{
// We don't have a check to see if len is too long, since we do that in bolt_receive()
// Shift the buffer down if we had already read part of it before
if (read_pointer > 0)
{
response_length -= read_pointer;
// memcpy of overlapping arrays is undefined behavior in C,
// but this complier handles backward overlaps well
memcpy(receive_buffer, &receive_buffer[read_pointer], response_length);
}
while (response_length < len)
{
ip65_process();
}
read_pointer = len;
}
// Clears the read buffer
void clear_buffer()
{
response_length = 0;
read_pointer = 0;
}
// Parses a big-endian 16 bit integer from a byte array
uint16_t parseInt16(char* data)
{
return (uint16_t)data[0] << 8 | data[1];
}
// Parses a big-endian 32 bit integer from a byte array
uint32_t parseInt32(char* data)
{
return (uint32_t)data[0] << 24 | (uint32_t)data[1] << 16 | (uint32_t)data[2] << 8 | data[3];
}
// Prints the content of a record on standard out
void print_record(int len)
{
int l, i;
char memory, t;
char* structure;
char* message = message_receive;
printf("-");
while (message < message_receive + len)
{
char marker = *(message++);
// NULL
if (marker == 0xC0)
{
printf(" NULL");
}
// TINY INT
else if (marker >= 0xF0 || marker <= 0x7F)
{
printf(" %d", (int)marker);
}
// INT 8
else if (marker == 0xC8)
{
printf(" %d", (int)(*(message++)));
}
// INT 16
else if (marker == 0xC9)
{
printf(" %d", (int16_t*)parseInt16(message));
message += sizeof(uint16_t);
}
// INT 32
else if (marker == 0xCA)
{
printf(" %d", (int32_t*)parseInt32(message));
message += sizeof(int32_t);
}
// INT 64
else if (marker == 0xCB)
{
// Not supported
printf(" INT64");
message += 8;
}
// FLOAT
else if (marker == 0xC1)
{
// Not supported
printf(" FLOAT");
message += 8;
}
// BYTE ARRAY
else if (marker >= 0xCC && marker <= 0xCE)
{
if (marker == 0xCC)
{
l = (int)(*(message++));
}
else if (marker == 0xCD)
{
l = parseInt16(message);
message += sizeof(uint16_t);
}
else
{
l = parseInt32(message);
message += sizeof(uint32_t);
}
printf(" [");
for(i = 0; i < l; i++)
{
if (i > 0)
{
printf(",");
}
printf("%02X", (*(message++)));
}
printf("]");
}
// STRING
else if ((marker >= 0x80 && marker <= 0x8F) || (marker >= 0xD0 && marker <= 0xD2))
{
if (marker >= 0x80 && marker <= 0x8F)
{
l = marker - 0x80;
}
else if (marker == 0xD0)
{
l = (int)(*(message++));
}
else if (marker == 0xD1)
{
l = parseInt16(message);
message += sizeof(uint16_t);
}
else
{
l = parseInt32(message);
message += sizeof(uint32_t);
}
memory = message[l];
// This could fall beyond the message length, but we assume that the whole
// message buffer isn't used
message[l] = '\0';
petscii_ascii_convert(message, l);
printf(" %s", message);
message[l] = memory;
message += l;
}
// LIST
else if ((marker >= 0x90 && marker <= 0x9F) || (marker >= 0xD4 && marker <= 0xD6))
{
if (marker >= 0x90 && marker <= 0x9F)
{
l = marker - 0x90;
}
else if (marker == 0xD4)
{
l = (int)(*(message++));
}
else if (marker == 0xD5)
{
l = parseInt16(message);
message += sizeof(uint16_t);
}
else
{
l = parseInt32(message);
message += sizeof(uint32_t);
}
// In our crude parsing we don't format the lists as lists, instead we write that
// a list is started, and then the elements are printed as base values
printf(" L(%d)", l);
}
// DICTIONARY
else if ((marker >= 0xA0 && marker <= 0xAF) || (marker >= 0xD8 && marker <= 0xDA))
{
if (marker >= 0xA0 && marker <= 0xAF)
{
l = marker - 0xA0;
}
else if (marker == 0xD8)
{
l = (int)(*(message++));
}
else if (marker == 0xD9)
{
l = parseInt16(message);
message += sizeof(uint16_t);
}
else
{
l = parseInt32(message);
message += sizeof(uint32_t);
}
// In our crude parsing we don't format the dictionaries as dictionaries, instead we write that
// a dictionary is started, and then the keys and values are printed as base values
printf(" D(%d)", l);
}
// STRUCTURE
else if (marker >= 0xB0 && marker <= 0xBF)
{
l = marker - 0xB0;
t = (*(message++));
structure = 0;
switch (t)
{
case 0x4E: structure = "Node"; break;
case 0x52: structure = "Relationship"; break;
case 0x72: structure = "UnboundRelationship"; break;
case 0x50: structure = "Path"; break;
case 0x44: structure = "Date"; break;
case 0x54: structure = "Time"; break;
case 0x74: structure = "LocalTime"; break;
case 0x49: structure = "DateTime"; break;
case 0x69: structure = "DateTimeZoneId"; break;
case 0x64: structure = "LocalDateTime"; break;
case 0x45: structure = "Duration"; break;
case 0x58: structure = "Point2D"; break;
case 0x59: structure = "Point3D"; break;
case 0x70: structure = "SUCCESS"; break;
case 0x7E: structure = "IGNORED"; break;
case 0x7F: structure = "FAILURE"; break;
case 0x71: structure = "RECORD"; break;
}
if (structure == 0)
{
printf(" S(%02X, %d)", t, l);
}
else
{
printf(" S(%s, %d)", structure, l);
}
}
}
printf("\n");
}
// Packs a bolt message contained in message_buffer into a chunk and sends it
void bolt_send(int16_t len)
{
// Since our buffer is limited to 512 bytes, we know we never have to use
// more than one chunk, and we also know that the most significant byte of
// the length is always 0
if(len > BUFFER_SIZE - 4)
{
message_exit("Message too long");
}
// Header
send_buffer[0] = 0;
send_buffer[1] = len;
// Message end
send_buffer[len+2] = 0;
send_buffer[len+3] = 0;
// Send chunk
tcp_send(send_buffer, len+4);
}
// Reads back a bolt reply and returns the length of it
// The message read can be found at message_receive
int bolt_receive()
{
// Since we can't handle messages longer than 512 bytes we shouldn't have to care about
// chunking when receiving either, but theoretically the server could chunk a shorter message,
// so we will. And to manage that we reuse the send_buffer to unpack the received message into
int l;
int message_reply_length = 0;
while (true)
{
tcp_read(2);
l = parseInt16(receive_buffer);
if (l == 0)
{
break;
}
if((l + message_reply_length) > BUFFER_SIZE)
{
message_exit("Reply too long");
}
tcp_read(l);
memcpy(send_buffer + message_reply_length, receive_buffer, l);
message_reply_length += l;
}
return message_reply_length;
}
// Packs a bolt message contained in message_buffer into a chunk and sends it,
// and then reads back a bolt reply and returns the length of it
// The message read can be found at message_receive
int bolt_send_receive(int16_t len)
{
clear_buffer();
bolt_send(len);
return bolt_receive();
}
// Note that the functions below doesn't have any check to avoid the message growing
// to big and spanning beyond the buffer. That has to be managed by the caller.
// Starts a struct with a defined number of fields
// You need to manually add each field after this call
char* start_struct(char* message, char signature, char fields)
{
set_byte(message, 0xB0 + fields);
set_byte(message, signature);
return message;
}
// Starts a dictionary for a certain number of fields
// You need to manually add each key pair after this call
// (currently doesn't support dictionaries with more than 15 fields)
char* start_dictionary(char* message, char fields)
{
set_byte(message, 0xA0 + fields);
return message;
}
// Adds an int to the message
// Currently we only support tiny ints (-16 - 127) because
// it is all we currenlty use
char* add_int(char* message, int value)
{
if (value >= -16 && value <= 127)
{
set_byte(message, (char)value);
}
return message;
}
// Adds a string to the message (currently only supports up to 255 character strings)
char* add_string(char* message, char* value)
{
// Bolt strings are not null-terminated, so we don't include the null terminator here
int len = strlen(value);
if (len < 16)
{
set_byte(message, 0x80 + len);
}
else
{
set_byte(message, 0xD0);
set_byte(message, len);
}
memcpy(message, value, len);
petscii_ascii_convert(message, len);
return message+len;
}
// Adds an int key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_int(char* message, char* key, int value)
{
message = add_string(message, key);
message = add_int(message, value);
return message;
}
// Adds a string key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_string(char* message, char* key, char* value)
{
message = add_string(message, key);
message = add_string(message, value);
return message;
}
// Adds a dictionary key pair to a dictionary
// You first have to call start_dictionary()
char* add_keypair_dictionary(char* message, char* key, int value_fields)
{
message = add_string(message, key);
message = start_dictionary(message, value_fields);
return message;
}
// Sends a Reset message (needed when the server is in a failed state)
int send_reset()
{
char* message = message_send;
message = start_struct(message, MESSAGE_RESET, 0);
bolt_send_receive(message_length(message));
return message_receive[0] == 0xB1 && message_receive[1] == MESSAGE_SUCCESS;
}
// Send the Hello message.
void send_hello(char* user_name, char* password)
{
int len;
char* message = message_send;
message = start_struct(message, MESSAGE_HELLO, 1);
message = start_dictionary(message, 4); // The main ("extra") dictionary
message = add_keypair_string(message, "scheme", "basic"); // Part of extra
message = add_keypair_string(message, "principal", user_name); // Part of extra
message = add_keypair_string(message, "credentials", password); // Part of extra
message = add_keypair_string(message, "user_agent", "C64/1.0.0"); // Part of extra
len = bolt_send_receive(message_length(message));
if (message_receive[0] != 0xB1 || message_receive[1] != MESSAGE_SUCCESS)
{
print_record(len);
message_exit("Authentication failure\n");
}
}
// Executes an auto-commit query (currently doesn't support parameters)
// Result is printed on standard out
void execute_query(char* query)
{
int len;
char* message = message_send;
if (strlen(query) > BUFFER_SIZE - 8)
{
printf("Query too long, cannot be sent\n");
return;
}
message = start_struct(message, MESSAGE_RUN, 3);
message = add_string(message, query);
message = start_dictionary(message, 0); // The "parameters" dictionary
message = start_dictionary(message, 0); // The "extra" dictionary
len = bolt_send_receive(message_length(message));
if (message_receive[0] != 0xB1 || message_receive[1] != MESSAGE_SUCCESS)
{
printf("Query execution failure\n");
print_record(len);
while (!send_reset())
{
printf("Retrying reset...");
}
return;
}
message = message_send;
message = start_struct(message, MESSAGE_PULL, 1);
message = start_dictionary(message, 1); // The main ("extra") dictionary
message = add_keypair_int(message, "n", -1); // Part of extra
len = bolt_send_receive(message_length(message));
while (message_receive[0] == 0xB1 && message_receive[1] == MESSAGE_RECORD)
{
print_record(len);
len = bolt_receive();
}
}
// scanf isn't implemented/working in CC65, so we have done our own simple input routine
void input(char* destination, int limit)
{
int c, i;
i = 0;
cursor(1);
while (i < limit)
{
c = cgetc();
if (c == 0x11 || c == 0x1D || c == 0x91 || c == 0x9D) // Arrows - disable
{
continue;
}
printf("%c", c);
if (c == 0x0D) // ENTER - accept
{
break;
}
else if (c == 0x14) // INST/DEL - special
{
if (i > 0)
{
i--;
}
}
else
{
destination[i++] = c;
}
}
destination[i] = 0;
cursor(0);
}
// Main routine
void main(int argc, char* argv[])
{
// This includes both the initial handshake and the version exchange
// (we only implement protocol version 5.0,
// which should be supported by all Neo4j 5.x versions)
char handshake[] = {0x60, 0x60, 0xB0, 0x17, 0x00, 0x00, 0x00, 0x05, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00};
// The command we are executing
char command[64];
// Server details
char* ipaddress;
char* user;
char* password;
int port = 7687;
if (argc < 4)
{
message_exit("Too few arguments! Usage: run:rem <ipaddress> <user> <password> [port]");
}
ipaddress = argv[1];
user = argv[2];
password = argv[3];
if (argc > 4)
{
port = atoi(argv[4]);
}
// Connect
printf("Initializing network\n");
if (ip65_init(ETH_INIT_DEFAULT))
{
error_exit();
}
if (dhcp_init())
{
error_exit();
}
printf("Local IP Addr: %s\n", dotted_quad(cfg_ip));
printf("Connecting to %s:%d\n", ipaddress, port);
if (tcp_connect(parse_dotted_quad(ipaddress), port, &read_callback))
{
error_exit();
}
// Send handshake
tcp_send(handshake, sizeof(handshake));
// Wait for the 4 byte reply and validate it
tcp_read(4);
if (receive_buffer[3] != 0x05)
{
message_exit("Server version not supported");
}
// Authenticate with the hello command
send_hello(user, password);
// Main loop of user entering queries that we execute
printf("Connected.\n");
while (true)
{
printf("Enter your query:\n");
input(command,63);
execute_query(command);
}
// Currently we never get here since the program is stopped with RUN/STOP+RESTORE
tcp_close();
}
Running Neo4j on a Commodore 64 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.