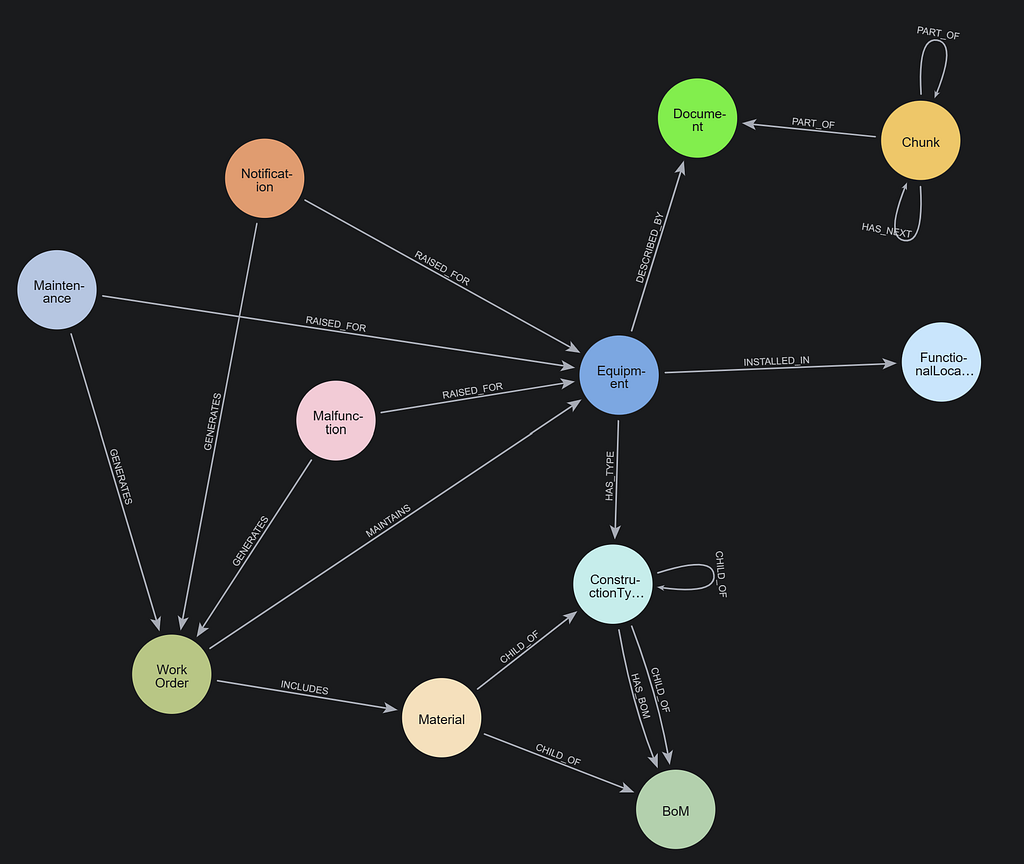
What Is GraphRAG?

Head of Product Innovation & Developer Strategy, Neo4j
13 min read

GraphRAG is a powerful retrieval mechanism that improves GenAI applications by taking advantage of the rich context in graph data structures.
Enterprise GenAI systems face a critical challenge: the need for trustworthy and reliable results. Pure large language model (LLM)-based solutions often fall short in this regard. These models are trained to prioritize helpfulness over factuality, and their pre-training data usually lacks crucial recent and relevant information. Consequently, they are prone to generating hallucinations of facts and explanations, which is particularly damaging in high-value business domains and use cases.
To address these issues, Retrieval-Augmented Generation (RAG) architectures have emerged as a solution. RAG improves the reliability of GenAI components by ensuring that LLM answers are based only on accurate information from existing knowledge sources.
Basic RAG systems rely solely on semantic search in vector databases to retrieve and rank sets of isolated text fragments. While this approach can surface some relevant information, it fails to capture the context connecting these pieces. For this reason, basic RAG systems are ill-equipped to answer complex, multi-hop questions.
This is where GraphRAG comes in. It uses knowledge graphs to represent and connect information to capture not only more data points but also their relationships. Thus, graph-based retrievers can provide more accurate and relevant results by uncovering hidden connections that aren’t often obvious but are crucial for correlating information.
In this blog post, we’ll dive into how GraphRAG works, explore its advantages over other RAG architectures in improving answer quality and explainability, and demonstrate its practical application using a Neo4j example.
Introduction to Retrieval-Augmented Generation (RAG)
Before diving into the specifics of GraphRAG, it’s essential to understand the basic concepts of RAG. Let’s take a closer look at the three key phases of RAG:
Retrieval: In this phase, the RAG system retrieves relevant information from external data sources, such as documents or databases, based on the user’s query. The retrieval process can use different techniques to identify the most pertinent data, such as similarity searches or database queries. The results are then ranked and scored based on their relevance to the query.
Augmentation: During the augmentation phase, the retrieved information is combined with the original user question, along with any additional instructions or context. This augmented prompt provides a richer context for the language model to generate a response. The goal is to force the model to only use this relevant information to produce an accurate and useful output.
Generation: In the final phase, the augmented prompt is processed by an LLM, which generates an answer in a requested format using only the provided context rather than relying on its pre-trained knowledge. The response can also link source information and additional metadata.
By augmenting the language model with external knowledge and using the model’s natural language understanding capabilities to retrieve and process this information, RAG systems can produce more accurate and informative responses compared to standalone language models that rely solely on their pre-trained knowledge.
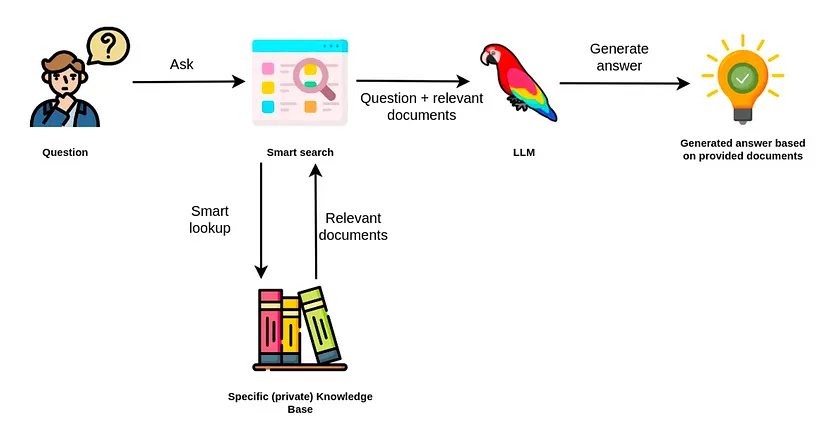
Limitations of Vector-Only RAG
Many baseline RAG systems rely solely on vector search over text embeddings (numerical vector representations) for information retrieval. To accurately capture the cohesive semantic meaning of a piece of text, the source documents are often chunked into smaller fragments, which are then embedded, indexed, and stored for retrieval.
However, this approach has its limitations. By relying solely on vector search, the response’s content is confined to the text fragments in the retrieved chunks. This can lead to incomplete or fragmented answers.
For example, if a user asks a question about a specific product feature, a vector-only RAG system might retrieve chunks that mention the product but fail to include relevant information from other parts of the documentation that provide a more comprehensive answer.
Moreover, due to the black-box nature of vector representations and vector search, such methods cannot explain the sources of the gathered information. This means that users and developers have limited visibility into why certain chunks were retrieved and how they contribute to the generated response. This lack of explainability can be a significant drawback, particularly in domains where transparency and accountability are crucial, such as healthcare or finance.
To address these shortcomings, new techniques are emerging to improve different phases of the RAG process (retrieval, augmentation, and generation).
Since the information provided to the LLM is crucial to answer quality, improving the retrieval mechanism often has the most significant impact. GraphRAG is a common approach to enhance retrieval by incorporating structured domain knowledge stored in a knowledge graph. By tapping into the rich connections and semantic relationships in a knowledge graph, GraphRAG aims to overcome the limitations of vector-only RAG and provide more accurate and explainable responses.
Knowledge Graph for Data Representation
A knowledge graph model is especially suitable for representing structured and unstructured data with connected elements. Unlike traditional databases, they don’t require a rigid schema but are more flexible in the data model. The graph model allows efficient storage, management, querying, and processing of the richness of real-world information. In a RAG system, the knowledge graph serves as the flexible memory companion to the language skills of LLMs, such as summarization, translation, and extraction.

In a knowledge graph, facts and entities are represented as nodes with attributes connected with typed relationships, which also carry attributes for qualification. This graph model can scale from a simple family tree to the complete digital twin of a company encompassing employees, customers, processes, products, partnerships, and resources, with millions or billions of connections.
Graph structures can originate from various sources, from a structured business domain, (hierarchical) document representations, and signals computed by graph algorithms.
Read a Complimentary Gartner® Report on Knowledge Graphs for AI
Graph Querying for GraphRAG Retrievers
Graphs can be navigated (traversed) by following simple patterns like (node:Type)-[relationship:TYPE]->(node:Type) or more complex variants expressed in Graph query languages like Cypher or GQL. Pattern matching results in paths whose nodes, relationships, and attributes can be filtered, aggregated, and sorted like in other query languages like SQL. Here is an example of a graph query that returns neighborhood information from a vector embedding search:
CALL db.index.vector.queryNodes(docs, 5, $embedding) yield node as doc, score
RETURN score, doc, COLLECT {
MATCH path = (doc)-[rel]-(neighbor)
RETURN path
} as paths
ORDER BY score DESC LIMIT 10
How GraphRAG Improves Retrieval
A GraphRAG retrieval can find starting points in this network of data via vector, fulltext, spatial, or other searches and then follow relevant relationships to gather additional information to satisfy the user queries. The context of the user and task is considered to increase relevance. All captured nodes, relationships and their attributes can be filtered and ranked before being returned as context in the augmentation phase.

This approach offers several advantages over vector-only RAG systems:
- By navigating the graph structure and following relevant relationships, GraphRAG can retrieve information that may not be directly mentioned in the initial set of retrieved chunks, providing a more comprehensive and contextually relevant response.
- The ability to filter and rank the retrieved information based on the user’s context and task allows GraphRAG to prioritize the most pertinent information, improving the overall quality of the generated response.
- GraphRAG enables better explainability by capturing the relationships between the retrieved information, making it easier to trace the sources and reasoning behind the generated response.
- By using the knowledge graph’s ability to integrate structured and unstructured data, as well as computed signals, GraphRAG can provide more informed and nuanced responses that draw from a wider range of information sources.
These improvements in the retrieval phase contribute to GraphRAG’s ability to generate more accurate, relevant, and traceable responses compared to vector-only RAG systems.
Types of GraphRAG Retrievers
The actual graph retrieval depends on the use case and domain. Different types of retrievers can be combined, and their results ranked, combined, or sequenced. In an agentic setup, retrievers can become tools that the LLM selects and runs iteratively, passing parameters and results until the necessary information to answer the question is collected.
Examples of GraphRAG retriever types include:
- Vector (Embedding), Fulltext, Spatial, or other Search Indexes: Using index searches with information from the user question to determine starting points in the graph for further exploration.
- Neighborhood Traversal: Access direct or indirect neighbors of a node to put a piece of information into context.
- Path Traversals: Find paths between starting entities, expand relationships to their neighborhood, and retrieve additional related documents, claims, and other entities.
- Global Queries: Using pre-computed, cross-topic summarization and other global representations of insights to answer general questions (see Microsoft’s GraphRAG with Query Focused Summarization).
- Query Templates: Use case-specific queries for categories of questions are provided by a domain expert, can have the same starting points but explore different sub-graphs, and can be selected by categorizing questions.
- Dynamic Cypher Generation (Text2Cypher): A (fine-tuned) LLM generates a Cypher query from the user question and the graph schema description to answer specific and structural questions.
- Agentic Traversal: Using different retrievers, an LLM selects and executes them in a planned sequence to collect all information to answer the question.
- Graph Embedding Retrievers: Using embeddings to represent the “essence” of a node’s neighborhood and allow fuzzy topological search by matching candidate embeddings.
You can find more examples in the GraphRAG Pattern Catalog on graphrag.com.
Knowledge Graph Construction
For GraphRAG to work well, we need to ensure that our data has a shape that accurately represents the highly relevant, connected pieces of information. To create this knowledge graph, we need to follow two steps, which can be repeated for refinement:
- Model the relevant nodes and relationships to represent our domain data.
- Import, create, or compute the graph structures to fit this graph model.

We can combine different sources of data:
- Import existing structured data from databases, files or APIs.
- Turn unstructured data (text, audio, video) into a graph representation of document structures/hierarchies and add vector embeddings and full-text indexes for chunks.
- Construct or connect structured entities (with optional embeddings) and their relationships from textual information.
- Enhance existing graphs with additional computation or algorithms, such as topic-clustering summaries (like in Microsoft Query Focused Summarization), similarity relationships, and personalized page rank (PPR) scores.
These graph models and sources are also described in more detail in the GraphRAG pattern catalog.
A GraphRAG Example With Neo4j
A frequent use case for GraphRAG is analyzing research information in more detail than just “chatting with your PDF.” In a vector-only semantic search approach, the data returned from the retrievers are just scored chunks of text with little or no information on how they relate to concepts from the domain or each other.
In contrast, a GraphRAG approach allows us to extract entities such as Person, Organization, Article, Paper, BiologicalProcess, Condition, Disease, Drug, Gene, Expression, Exposure, and Pathway that appear in our documents and create a rich network of information.
To demonstrate this, let’s walk through an example of constructing a knowledge graph using the open source neo4j-graphrag package. You can also use LangChain, LlamaIndex, or other integrations.
In this example, we use the SimpleKGPipeline, which comes with a number of defaults and executes the steps depicted below:
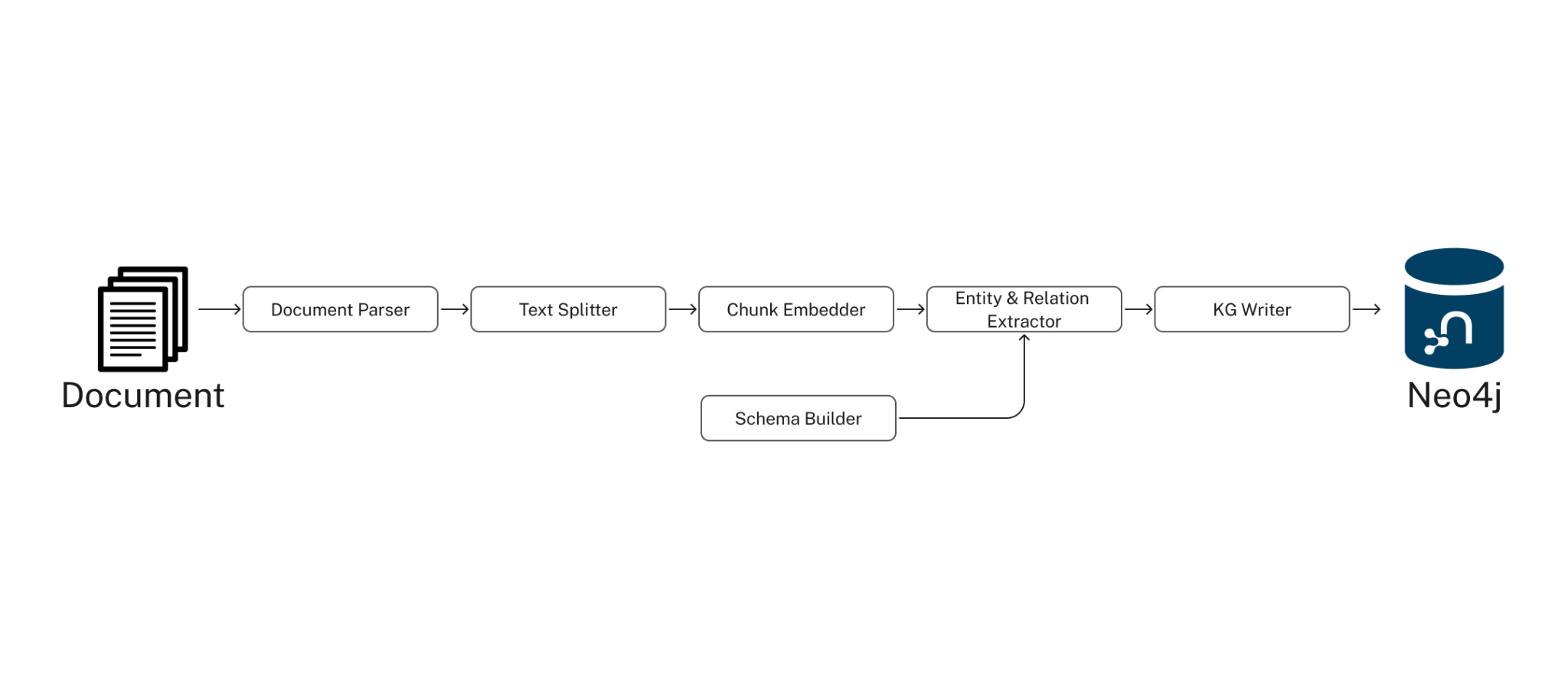
To run this extraction, we configure the Pipeline with the following components:
- LLM (e.g., gpt-4o-mini from OpenAI)
- Embedding model
- Document splitter
- Graph schema
Once configured, we can execute the pipeline on our dataset of biomedical research papers:
driver = neo4j.GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
ex_llm=OpenAILLM(
model_name="gpt-4o-mini",
model_params={
"response_format": {"type": "json_object"},
"temperature": 0
}
)
embedder = OpenAIEmbeddings()
node_labels = ["Anatomy", "BiologicalProcess", ...]
rel_types = ["ACTIVATES", "AFFECTS", "ASSESSES",..."TREATS", "USED_FOR"]
kg_builder_pdf = SimpleKGPipeline(
llm=ex_llm,
driver=driver,
text_splitter=FixedSizeSplitter(chunk_size=500, chunk_overlap=100),
embedder=embedder,
entities=node_labels,
relations=rel_types,
prompt_template=prompt_template,
from_pdf=True
)
pdf_file_paths = ['biomolecules-11-00928-v2.pdf', 'GAP-between-patients-and-clinicians_2023_Best-Practice.pdf','pgpm-13-39.pdf']
for path in pdf_file_paths:
graph_data = await kg_builder_pdf.run_async(file_path=path)
After storing the chunked document data and graph data in Neo4j, we can visualize it using our Query tool.

Now, we can execute a GraphRAG retriever and compare its results with a vector RAG retriever.
This retriever first executes a vector search for the indexed text chunks and then follows non-chunk relationships up to 2 hops out, retrieving not only the directly extracted entities but also their first- and second-degree neighbors. It returns the chunk texts and entity-relationship-entity pairs as context for use in the final phases of prompt augmentation and answer generation.
from neo4j_graphrag.retrievers import VectorCypherRetriever
graph_retriever = VectorCypherRetriever(
driver,
index_name="text_embeddings",
embedder=embedder,
retrieval_query="""
//1) Go out 2-3 hops in the entity graph and get relationships
WITH node AS chunk
MATCH (chunk)<-[:FROM_CHUNK]-(entity)-[relList:!FROM_CHUNK]-{1,2}(nb)
UNWIND relList AS rel
//2) collect relationships and text chunks
WITH collect(DISTINCT chunk) AS chunks, collect(DISTINCT rel) AS rels
//3) format and return context
RETURN apoc.text.join([c in chunks | c.text], '\n') +
apoc.text.join([r in rels |
startNode(r).name+' - '+type(r)+' '+r.details+' -> '+endNode(r).name],
'\n') AS info
"""
)
Next, we build the vector and GraphRAG pipelines using each retriever with a suitable LLM (here, using the better OpenAI gpt-4o) and prompt for question answering:
llm = LLM(model_name="gpt-4o", model_params={"temperature": 0.0})
rag_template = RagTemplate(template='''Answer the Question using the following Context. Only respond with information mentioned in the Context. Do not inject any speculative information not mentioned.
# Question:
{query_text}
# Context:
{context}
# Answer:
''', expected_inputs=['query_text', 'context'])
vector_rag = GraphRAG(llm=llm, retriever=vector_retriever, prompt_template=rag_template)
graph_rag = GraphRAG(llm=llm, retriever=graph_retriever, prompt_template=rag_template)
q = "Can you summarize systemic lupus erythematosus (SLE)? including common effects, biomarkers, and treatments? Provide in detailed list format."
vector_rag.search(q, retriever_config={'top_k':5}).answer
graph_rag.search(q, retriever_config={'top_k':5}).answer
The comparison of answers shows that the GraphRAG response is much more comprehensive and covers more of the relevant context.

For more details, see GraphRAG Python Package: Accelerating GenAI With Knowledge Graphs and check out the resources section.
Common GraphRAG Use Cases
GraphRAG is used in applications and domains that require a higher level of trust, as their outputs are used for critical business decision-making. Some examples include:
- Legal and Compliance: Reviewing and analyzing contracts, cases, laws, and regulations.
- Investment Research: Investigating organizations, people, competitors, markets, and trends.
- Biotech: Accessing knowledge graphs for drug discovery and repurposing, clinical trials, and research.
- Business Process Support: Integrating various business data sources into a cohesive view of an organization.
- Supply Chain: Conducting investigations for risk assessment, compliance, and sustainability of products and production processes.
- Fraud Detection: Identifying and preventing money laundering (AML), insurance fraud, and other fraudulent activities.
- Investigative Journalism: Uncovering connections and patterns in large datasets for news stories and investigations.
- Natural Language Search and Chatbots: Democratizing access to pre-existing knowledge bases through user-friendly interfaces.
GraphRAG: Enabling Enterprise-Grade AI Apps
RAG architectures are currently the most effective way to provide reliable content for GenAI business applications by using data from trusted data sources. GraphRAG takes this a step further, improving upon basic vector-based RAG in both quality and explainability.
By considering more relevant context and using a variety of retrievers that navigate document, domain, and computed graph structures, GraphRAG delivers more accurate, trustworthy, and traceable results. The combination of knowledge graphs, with their rich representation of real-world information, and LLMs, with their advanced language skills, creates a robust and reliable solution for enterprise use cases.
As more organizations adopt GenAI, GraphRAG will be essential in ensuring the accuracy, reliability, and transparency of these systems, paving the way for better decision-making and improved business outcomes.
Essential GraphRAG
Unlock the full potential of RAG with knowledge graphs. Get the definitive guide from Manning, free for a limited time.

Additional Resources
If you want to learn more about GraphRAG, check out these resources:
Overviews
Technical
- GraphRAG Pattern Catalog
- Online Neo4j LLM Knowledge Graph Builder (using LangChain)
- Neo4j GraphRAG Python Package
Courses
Share Article



Explore
Related Articles