




Cypher Just Got More Dynamic
Dynamic labels, types, and properties in Cypher are finally here. These highly requested features are a significant step forward in mitigating Cypher injection risks while promoting more concise, readable, and maintainable code. In Cypher 5.26 and beyond, dynamic labels and types will help you CREATE, MATCH, and MERGE nodes and relationships without having to statically know their values beforehand, and dynamic properties are a new way of setting properties using dynamic keys.
Note: MATCH and MERGE implementation uses a scan and filter in the initial implementation, they are not optimized yet.
Setting and Removing Node Labels
SET n:$(expression)
REMOVE n:$(expression)
To SET or REMOVE a node label dynamically, add any expression that evaluates to a non-null STRING or LIST<STRING> in the place of `expression`. Because relationships always need exactly one type, it is not possible to SET or REMOVE them.
Setting and Removing Properties
SET n[key] = expression
REMOVE n[key]
To SET or REMOVE a property with a dynamic key, add any expression that evaluates a STRING as the key.
Creating, Matching, and Merging With Dynamic Labels and Types
CREATE (:$(expression))-[:$(expression)]->(:$(expression))
MATCH (:$(expression))-[:$(expression)]->(:$(expression))
MATCH (:$all(expression))-[:$all(expression)]->(:$all(expression))
MATCH (:$any(expression))-[:$any(expression)]->(:$any(expression))
MERGE (:$(expression))-[:$(expression)]->(:$(expression))
Creating, matching, and merging can now take dynamic node labels and relationship types by adding any expression that evaluates to a non-null STRING or LIST<STRING> in the place of `expression`.
How to Write More Secure Code
One of the first things an inspiring programmer learns about database security is that they should avoid code injection at all costs, and the way they’re told to do this easily is to avoid string concatenation. Simple: Just parameterize all the variable data in your query and problem solved — right?
This advice is valid for a lot of use cases, and will solve many headaches. For example, let’s meet the cousin of the classic example, little Robby Labels (see Protecting against Cypher Injection to learn more).
Let’s say Robby is enrolling at a new school and has thus sent in his full name:
"Robby' WITH DISTINCT true as haxxored MATCH (s:Student) DETACH DELETE s //"
This is an attempt at Cypher injection with the goal of deleting all Student nodes in the schools database. The WITH clause in the middle is to ensure that the result set is reduced to a single row before deleting all students.
If Robby’s school used string concatenation to build its queries, this attack might succeed:
String queryString = "CREATE (s:Student) SET s.name = '" + studentName + "'";
Result result = session.run(queryString);
The query that will be run is:
CREATE (s:Student) SET s.name = 'Robby'
WITH DISTINCT true as haxxored
MATCH (s:Student)
DETACH DELETE s //;
After the Robby node is created, all Student nodes are then found and subsequently deleted.
This is mitigated quite simply in Cypher by using parameters. The following example illustrates how to set parameters in browser, for more on setting query parameters see the Neo4j Browser Manual.
:param studentName => "Robby' WITH DISTINCT true as haxxored MATCH (s:Student) DETACH DELETE s //"
The parameterized query would look like this:
CREATE (s:Student)
SET s.name = $studentName
This looks great — problem solved! But what happens when the query we want to run has a node label we don’t know statically beforehand?
Let’s continue our example. The school that little Robby Tables goes to has fixed its student naming issue, and due to this, staff have decided that the school’s database application is so good that they want to share it with other schools.
To allow for this, they need to add a new tenant label alongside the student label, which matches the school name. As any school can now use the system, they allow for both the school name and student name to be sent in with free text and, since labels cannot be parameterized, they end up with a query as follows:
"CREATE (s:STUDENT:" + schoolName + ") SET s.name = $studentName"
Oh no! More string concatenation! 😦
The only way around this previously would be to either sanitize the information as it comes in (which is prone to bugs), have it checked against an enum before submitting it (which means the application must know all possible labels allowed), or try to use a library to help, such as APOC (but beware: Cypher injection is still possible with APOC). That was, until now. 😎 With the introduction of dynamic labels, types, and properties, even these queries can be easily parameterized.
Note: Sanitization would require wrapping those labels in backticks and removing all backticks from the passed-in label.
The school has updated its Neo4j instance and can now fix its vulnerable query:
:param schoolName => "CYPHER_SCHOOL"
CREATE (s:STUDENT:$($schoolName)) SET s.name = $studentName
Voila! No more Cypher injection! 🎉
Load CSV
With dynamic labels, types, and properties, it’s now even easier to load data into your database. Take the following CSV file:
:Person:Student,id->1,name->Kate,age->27
:Person:Programmer,id->2,name->Sara,age->29
:Cat,id->2,name->Montana,age->4,likes->lasagne
The first column is labels, separated by colons `:`. The remaining columns are property keys to their value, separated by arrows `->`.
Previously, creating these nodes with the given labels required either knowledge inside the query about the existing labels or the use of a library like APOC. But now, the query is quite straightforward:
LOAD CSV FROM "file:///test.csv" AS row
CREATE (n:$(split(ltrim(row[0], ":"), ":")))
WITH n, row
UNWIND range(1, size(row) - 1) as property
WITH n, split(row[property], "->") AS prop
SET n.$(prop[0]) = prop[1]
Migrating Away From APOC
The popular plugin APOC has for years offered some workarounds for creating, updating, deleting, and searching on data that is not statically known beforehand. However, we recommend using pure Cypher as much as possible, so here are some examples of how to migrate your APOC queries into Cypher ones.
These queries show how to turn a node property into a node label. The first query shows how one would do it using APOC’s apoc.create.addLabels procedure.
With apoc.create.addLabels:
MATCH (n:Movie)
CALL apoc.create.addLabels( n, [ n.genre ] )
YIELD node
REMOVE node.genre
RETURN node;
This second query shows the exact same behavior, except now simplified using pure Cypher:
MATCH (n:Movie)
SET n:$(n.genre)
REMOVE n.genre
RETURN n;
These queries show how to remove all the labels of a node other than `Person`. This could be done using the APOC procedure apoc.create.removeLabels:
CALL db.labels()
YIELD label WHERE label <> "Person"
WITH collect(label) AS labels
MATCH (p:Person)
CALL apoc.create.removeLabels(p, labels)
YIELD node
RETURN node, labels(node) AS labels;
To get the same behavior in pure Cypher:
CALL db.labels()
YIELD label WHERE label <> "Person"
WITH collect(label) AS labels
MATCH (p:Person)
REMOVE p:$(labels)
RETURN p, labels(p) AS labels;
To update how labels are named — capitalizing the first letter of the label only, for example — then using APOC, it was possible to use string concatenation like the following.
With apoc.cypher.doIt (a way to execute dynamic Cypher as write operation):
MATCH (node)
WITH node, labels(node)[0] AS label
CALL apoc.cypher.doIt(
"WITH $node AS node
REMOVE node:`" + label + "`\n" +
"SET node:`" + apoc.text.capitalize(toLower(label)) + "`\n" +
"RETURN node", {node: node})
YIELD value
RETURN value;
This is now much easier to do (and not vulnerable to Cypher injection!) in pure Cypher:
MATCH (node)
WITH node, labels(node)[0] AS label
REMOVE node:$(label)
SET node:$(apoc.text.capitalize(toLower(label)))
RETURN node;
Caveats
Dynamic labels, types, and properties offer better security, simpler queries, and are fun to use, but there’s a caveat to keep in mind:
When using dynamic values, Cypher cannot plan to the same extent the most efficient way to execute the query. This is because the Cypher Planner only uses statically available information at compilation time, when figuring out if it should use an index or constraint.
This means that certain queries, especially MATCH and MERGE, will not be planned as efficiently as the same query when dynamic labels aren’t being used.
For example, using the Movie sample database, doing a simple MATCH on the label Movie will result in the following plan:
EXPLAIN MATCH (m:Movie)
RETURN m

If we instead reference the label dynamically, we get the following:
EXPLAIN MATCH (m:$(ltrim(" Movie")))
RETURN m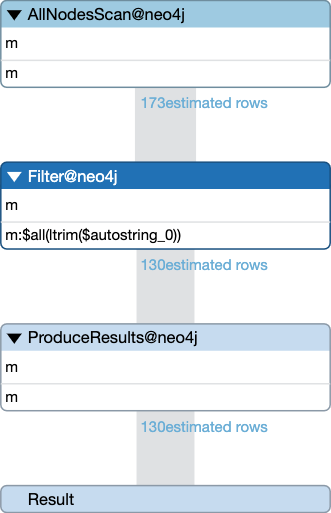
These queries may look similar, but under the hood, the plans are very different. The difference between the two plans can be seen by the types of node scans done. In the static example, the Cypher Planner chooses a NodeByLabelScan, whereas the dynamic case uses an expensive AllNodesScan followed by a Filter. An AllNodesScan will do more work and can cause performance issues on a non-trivial database, which means on a large graph, this can have a significant impact on the speed of the query.
This is something the Cypher engineering team will continue to work on, and as time goes on, we will close the gap in performance. But for now it’s important to keep in mind that if a query doesn’t need dynamic labels, types, and properties, it’s better to use regular static syntax to help the planner to build efficient query plans.
Next Steps
For more information, check the Cypher Manual for documentation on this exciting feature. You’ll find documentation on how to dynamically reference node labels and relationship types in MATCH, CREATE, and MERGE clauses, as well as the ability to dynamically reference labels in SET and REMOVE clauses, and property keys in SET and REMOVE clauses.
Please let us know what you think and if those changes are helpful, and share feedback here or as GitHub issues.
Cypher Dynamism: A Step Toward Simpler and More Secure Queries was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





