
Is a Knowledge Graph a Graph Database?



10 min read

If you work with data, you’ve likely come across the terms knowledge graph and graph database. Though often used interchangeably, they’re not quite the same thing.
A knowledge graph is a design pattern for storing, organizing, and querying entities and relationships. A graph database is a great place to store your knowledge graph.
Put another way, graph databases store graphs. And a knowledge graph is a type of graph.
You’ve come to the right place if you’re graph-curious or unfamiliar with graphs. Data modeling problems can be frustrating until you realize your data may be a graph. Modeling graph data in non-graph ways (e.g., in a relational database) leads to complex development cycles, design and code workarounds, and ultimately, degraded application performance.
So, how do you know whether your data is best organized as a graph? And when should you consider using a graph database? Let’s dive in with the basics: what’s a graph, a graph database, and a knowledge graph — and how should you use them?
More in this guide:
What Is a Graph?
Graph theory defines a graph as a set of objects, where some pairs of objects are “related” to each other in some way. You’ll often see a graph depicted visually, with circles for the objects joined by lines for the relationships:

In computer science, a graph is a data structure that stores objects and their relationships. Anytime you have data that connects to other data, that’s a graph, and graphs are most easily managed in a graph database. Relational databases (arguably the most popular type of database for structured data) do not capture the connections and relationships between bits of data — they force you to use joins to reconstitute them.
What Is a Graph Database?
A graph database is a type of database that’s specifically designed to store data with relationships. There are several types of graph databases, but the most popular type (known as a labeled property graph) is the one in which data is organized as nodes, relationships, and properties, rather than in tables or documents.
In a graph database, you can model data the way you think about it, just like you would sketch it out on a whiteboard. Imagine the graph data model of a social network: nodes connected to multiple other nodes through different types of relationships.

Characteristics of Graph Databases
Graph databases use nodes and relationships — a surprisingly simple and intuitive structure if you’re used to relational or document models.
Nodes are entities in the graph that can:
- Hold properties (as key-value pairs) that describe them (e.g., name, date of birth, etc.)
- Have a label that signifies their role in the domain (e.g., Person, Account, Device, etc.)
- Be connected to other nodes through relationships (they can even be connected to themselves)
Relationships link pairs of nodes to one another in a graph, and they:
- Describe the relationship of one node to another
- Always have a start node and an end node (relationships therefore have a direction)
- Have a type that indicates the nature of the relationship
- May hold properties, which provide additional information about the relationship
Structuring, storing, and querying data in this way makes it efficient to traverse relationships and query at scale even as data volume expands over time.
Advantages of Graph Databases
A graph database is ideal for managing connected data. The more complicated or numerous the relationships in a dataset, the more valuable the graph database becomes. For example, if you’re working with nested, hierarchical, or otherwise highly connected data sets, a graph database is the best way to ensure good application performance. The major advantages of using a graph database in Neo4j include:
- A flexible data model that evolves with the changing requirements of your data (no schema redesign)
- Easy to scale to billions of nodes and relationships across cloud platforms (AWS, Azure, GCP)
- Quick to develop applications, with a concise yet powerful query language
- Purpose-built for use cases involving data relationships, like GenAI, customer 360, fraud, supply chain, and metadata management
What Is a Knowledge Graph?
A knowledge graph maps raw connected data into a meaningful representation of the real world. Its entities can represent objects, events, situations, or concepts. The purpose of a knowledge graph is to organize data so that you can surface knowledge for the user or business.
For example, a knowledge graph behind a fraud application might store data with the actors/institutions and the transactions between them as nodes connected by relationships indicating the parties to the transaction. Organizing the behavioral patterns as relationships in a knowledge graph enables you to discover suspicious patterns, such as circular payments, easily.
Knowledge Graphs 101
Want to try your hand at building a knowledge graph? This quick-and-dirty guide walks you through your first implementation.
Characteristics of a Knowledge Graph
A knowledge graph is typically (and ideally) built and stored in a graph database. The knowledge graph organizes entities and their relationships using a framework called organizing principles. Organizing principles capture business rules or categories for the data, serving as a flexible conceptual structure that helps you surface deeper data insights. You can apply multiple organizing principles to the same data in a knowledge graph.
The organizing principles themselves are stored the same way as the data is stored — as nodes and relationships in the graph, as pictured here:

Because the organizing principles are stored as nodes and relationships, you can query across both instance-level data and the organizing principles in the same query. For example, a query could fetch all customer transactions and group those transactions according to the organizing principles (such as risk categories or customer segments).
Why Use a Knowledge Graph
A well-designed knowledge graph doesn’t simply answer the question, “What data do we have?” It goes further by answering questions like, “What does this data mean?” and “What can we learn from these connections?”
The deeper meanings found in connections across data make knowledge graphs useful for intelligent applications such as recommendation engines, fraud detection, and AI systems.
Graph Database vs. Relational Database for a Knowledge Graph
You could build a knowledge graph without a graph database, but using another database will present challenges. For example, if you were to use a relational database to build your knowledge graph, you’d have to create lengthy workarounds:
| Relational Database | Graph Database |
|---|---|
| Requires join tables to represent many-to-many relationships | Supports many-to-many relationships in the data model itself |
| Relationships must be reconstituted in the query code with joins. The code must be kept up to date as relationships change over time. | Defines the relationships in the database, reducing the chance of errors in the code (and bugs). |
| Complex queries with multiple cascading joins (join bombs) degrade database performance as data grows. | Native graph databases do not need joins; they simply traverse the relationships in the graph, giving superior runtime performance even as data volumes grow. |
Relational databases are not designed to support the interconnected nature of a knowledge graph. Using one as your foundation will likely make design and maintenance more difficult and lead to runtime performance issues.
When to Use a Graph Database vs. a Knowledge Graph
When you consider whether it might make sense to use a graph database or a knowledge graph for your application, remember that it’s not an either-or situation. Think of a knowledge graph as the organizer of your data/relationships, and the graph database as the storage of that data/relationships and their organizing principles.
While a knowledge graph could be built on another database, a graph database offers a data model closely aligned with the natural structure of a knowledge graph. This makes sense — a knowledge graph is a graph, after all, and graph databases are purpose-built for storing and using graphs.
The key thing to remember is that a graph database provides the native data structure required for an efficient and flexible knowledge graph implementation. Building a knowledge graph on other database technologies typically involves more time, effort, and workarounds that ultimately limit scalability and performance.
Use Cases
A knowledge graph stored in a graph database supports use cases like fraud, customer 360, generative AI, and others that rely on connected data (e.g., supply chain, digital twin, and drug discovery). Let’s dive in and look at why a knowledge graph offers a strong, flexible foundation for these use cases:
Fraud Detection
Fraud detection involves monitoring patterns, behaviors, and relationships to spot potentially fraudulent actions.
A knowledge graph built on a graph database allows you to model accounts, people, transactions, devices, etc., as a graph to quickly uncover hidden suspicious patterns that may indicate fraud.

Essential ways that knowledge graphs enhance fraud detection include:
- Pattern matching: Graph databases excel at storing and querying across relationships between accounts, individuals, and transactions. When structured as a knowledge graph, these relationships reveal behavioral patterns that would otherwise remain hidden or difficult to find in time to detect and prevent financial crime.
- Real-time analysis: Native graph databases can traverse the relationships in a knowledge graph without needing performance-killing joins, enabling you to find the complex patterns of fraud quickly.
- Flexibility: Fraudsters constantly evolve and improve their operations to evade detection. A graph database can help you stay ahead with a flexible schema that enables you to change quickly without redesigning the data model and reworking the application code to accommodate the redesign.
The result is a fraud detection pipeline that catches more sophisticated schemes while reducing customer friction caused by false alerts.
Customer 360
The goal of what is commonly referred to as Customer 360 is to create a comprehensive, unified view of each customer’s entire relationship with an organization, including every interaction, purchase, preference, and behavior across every touchpoint and channel. Done right, it provides a complete picture of the customer journey.
The connected nature of graph databases makes them ideal for bringing fragmented customer data together into a cohesive customer profile. Every time a customer makes a purchase, contacts support, or interacts with a marketing touchpoint (such as viewing an ad or loading a specific page on the company website), the interaction is added to the graph database and then linked to the customer’s existing profile data. Over time, this helps build a complete picture of each customer. Simple queries like “Who purchased Product X?” are just the starting point.
A few ways knowledge graphs and graph databases can help include:
- Connected customer profile: Graph databases can easily and naturally link purchases, interactions, and customer profiles, enabling useful queries like “What other products do purchasers of Product X typically buy?” or “What services does Customer Y use? This connected graph can be further enriched with entity resolution techniques to unify interactions across multiple channels, even when those interactions involve seemingly anonymous activities like guest browsing of a website.
- Journey mapping: When structured as a knowledge graph with the right organizing principles, a customer’s connected data can reveal patterns in how they interact with your brand across multiple channels and over time.
- Preference inference: The relationships stored in a graph database, in combination with the semantic context added by a knowledge graph, allow an organization to infer customer preferences based on their behavior patterns.
Organizations that use this approach can move beyond basic data storage to create dynamic customer insights that anticipate their customers’ needs.

Generative AI
Most enterprise generative AI (GenAI) applications use large language models (LLMs) enhanced with retrieval-augmented generation (RAG) techniques that pull factual information from databases to produce accurate, contextually relevant content. These applications generate text, answer questions, or create content based on learned patterns and retrieved facts.
RAG emerged as a response to the problem of hallucination, where LLMs generate responses with inaccurate information. RAG improves the trustworthiness of responses by providing an architecture that retrieves information from an external database.
However, without a knowledge graph, where important context is captured in relationships and organizing principles, RAG can still provide incomplete answers. Graph-based retrievers, a technique known as GraphRAG, combine the semantic similarity capabilities of vector-based approaches with the rich fidelity of knowledge graphs.
The explicit relationships captured in a knowledge graph ground AI outputs with verifiable information. When a user asks, “Who authored Book X?” the system doesn’t guess. Instead, it retrieves the precise relationship from its knowledge structure.
Knowledge graphs backed by graph databases can help GenAI applications in several ways:
- Factual retrieval: Graph databases store and retrieve explicit relationships needed for factual queries (e.g., “Who authored Book X?”), providing a reliable knowledge base for generative AI systems.
- Contextual understanding: A knowledge graph with domain-specific organizing principles and connected data helps AI systems understand query context and provide more relevant responses.
- Semantic disambiguation: The property graph model of graph databases, enhanced with knowledge graph semantics, helps AI systems distinguish between different meanings of the same term based on context.
- Reasoning support: The explicit relationships in a graph database and the semantic layers of knowledge graphs provide AI systems with the structured information needed for basic reasoning tasks.
- Hallucination prevention: By grounding generative AI in a knowledge graph built on a graph database, systems can verify facts before responding, thus reducing the possibility of fabricated information.
Generative AI, backed by knowledge graphs, delivers accurate, context-aware responses. This is a significant improvement over systems that produce plausible-sounding but potentially incorrect responses.

FAQ: Knowledge Graphs and Graph Databases
Here’s a quick overview of common knowledge graph and graph database questions:
No. A knowledge graph organizes and connects data using entities and relationships to represent real-world meaning. A graph database is where that connected data is stored. You build a knowledge graph on top of a graph database, which provides the structure and performance needed to manage relationships at scale.
Knowledge graphs rely on rich, dynamic relationships between data points. Graph databases are purpose-built to efficiently store and traverse these relationships, making them a natural and performant foundation for building knowledge graphs.
Yes, it’s possible to create a knowledge graph with other technologies such as RDF, but property graph databases are the most efficient, intuitive, and scalable infrastructure.
Building a Knowledge Graph on a Graph Database
A graph database stores connected data. A knowledge graph organizes that data, using entities and relationships to model the real world and surface insights. While the two are often mentioned together, their roles are distinct: the graph database provides the infrastructure, and the knowledge graph provides the structure and meaning.
If your data naturally connects — across systems, people, or concepts — a graph database is the foundation you need. And if you want to turn that connected data into context and insight, building a knowledge graph on top is the next step.
Ready to start building your own knowledge graph? Download our guide: How to Build a Knowledge Graph.
How to Build a Knowledge Graph
Learn the basics of graph data modeling, how to query, and top use cases that use highly interconnected data.
Share Article



Explore
Related Articles


From Data Chaos to Clarity: How Connected Data Can Improve US Government Decision-Making
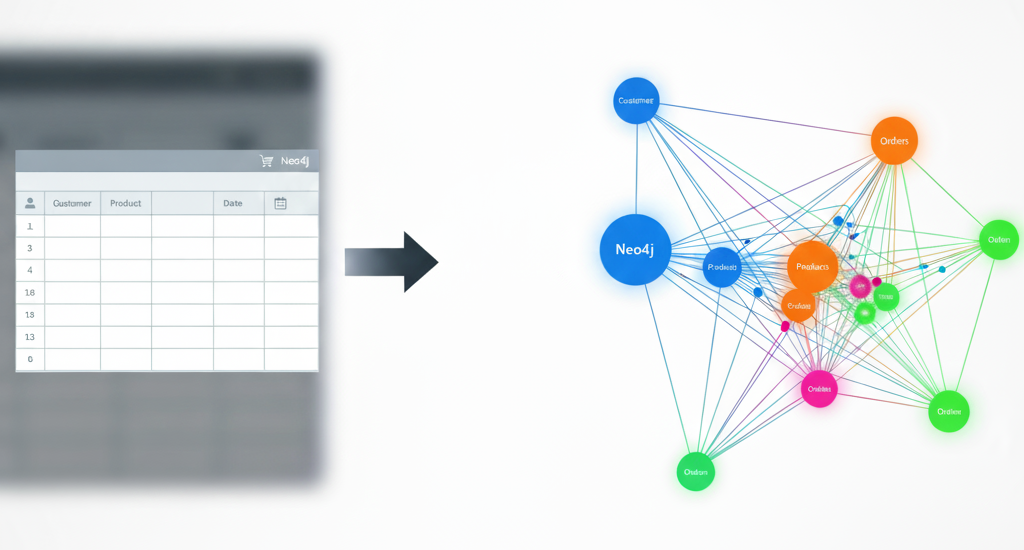
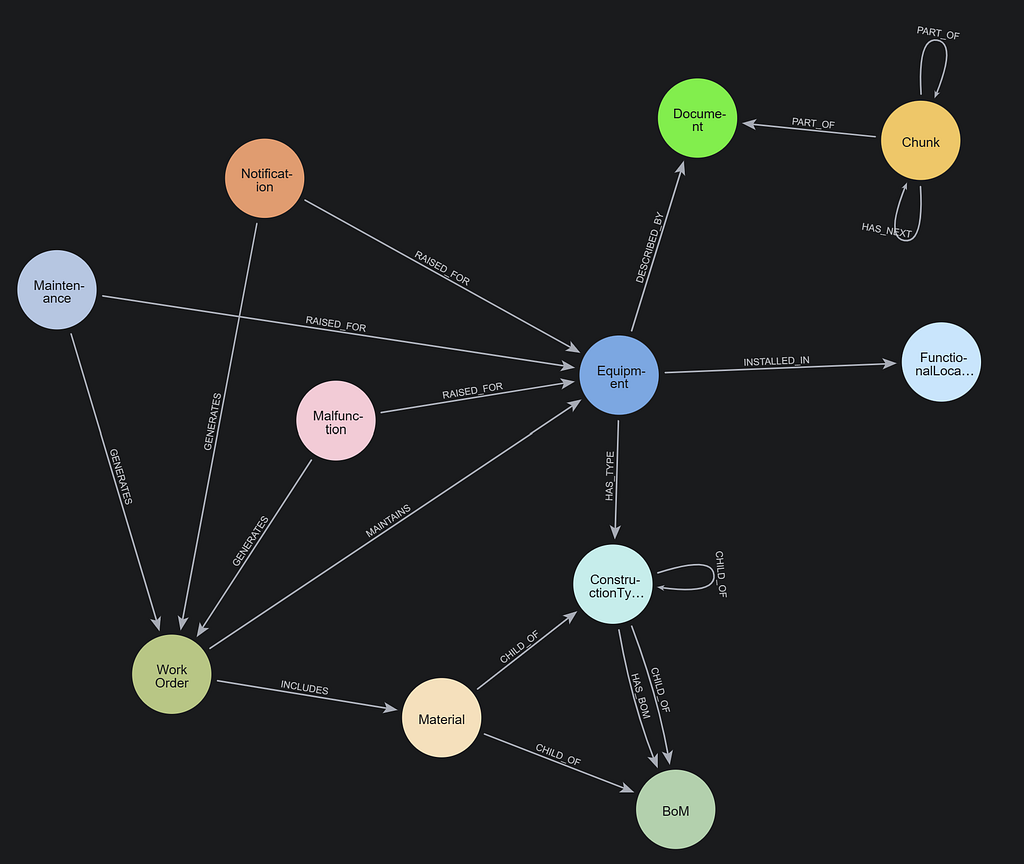
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It

