It’s All in the Relationships: 15 Rules of a Native Graph Database

Senior Manager, Content, Neo4j
4 min read

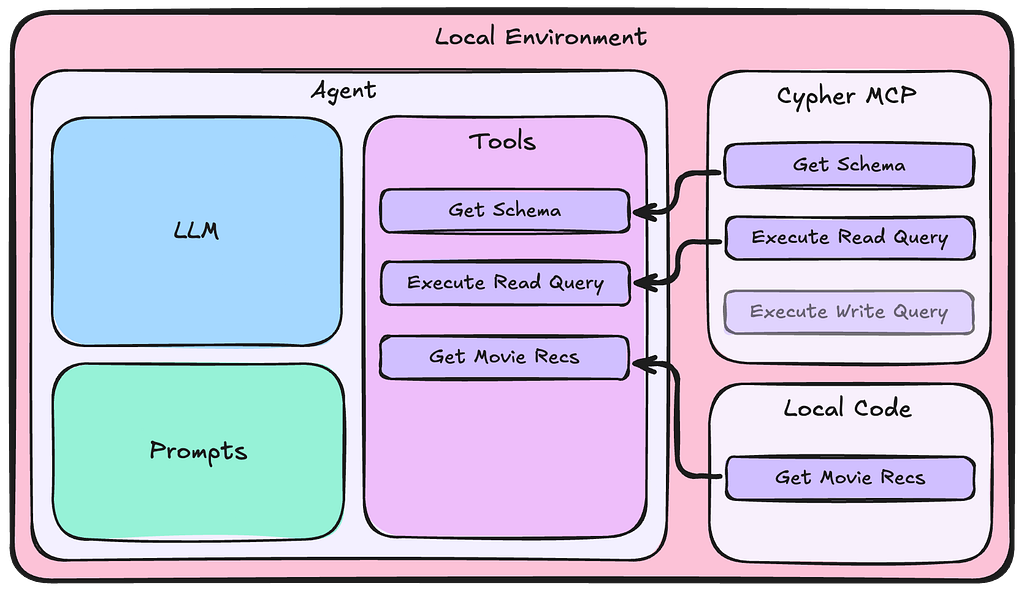
Like a complex system grid or an air-traffic-control map, a graph database is represented as a network of nodes and connections called a labeled property graph. The nodes, which appear as circles or squares, represent entities such as people, products, companies or orders.
In Neo4j, the connections between database nodes are called relationships, and those relationships are as important as the nodes they connect.
Each relationship is directional and knows its beginning and ending node, and each node knows about all other nodes with which it has an inbound or outbound relationship – an advantage known as index-free adjacency.
Native Graph Storage and Processing
But a property graph model is a lot more than a picture. It actually describes how you access and query information in the database.
To maximize efficiency and performance, a graph database platform must store and access data as it appears in the database’s property graph. A database platform that employs such an approach is known as a native graph database.
Graph Imposters Pay the Price
For datasets that are connected, complex or changing, non-native graph database approaches are inherently flawed with performance, integrity, ease-of-use and scalability risks.
Relational databases bolt on extra processing layers that translate graph queries into relational-table-based storage and processing models used by the underlying database technologies. The result is considerably slower performance and application responsiveness that often renders graph applications completely unusable.
Most NoSQL database technologies add similar translation layers and inefficiencies to create graph applications, again resulting in sluggish performance and even risking corrupt or unsuccessful graph query results.
15 Rules of the Native Graph Database
Graph database management systems must model, manage and access data and their relationships entirely through native data storage and graph processing methods. To be a native graph DBMS, a technology must conform with these basic rules.
Relational and NoSQL databases break the rules by layering graph capabilities atop non-graph data and are plagued by performance, latency, consistency and data-corruption problems.
- Native Storage and Modeling
Store and model data as a graph of relationships instead of in rows and columns, indexed records, or in any other structure. - Native Graph Management
Manage data and relationships entirely through native graph capabilities, and not through a graph-logic layer that sits atop a non-graph storage or processing foundation. - First-Class Relationships
Treat relationships among graph data elements as first-class database elements, complete with directional and quantifying properties used by the graph database engine. - Real-Time Availability
Query data in real time regardless of the volume or complexity of its underlying relationships. - Index-Free Adjacency
Link every data element directly to its incoming and outgoing relationships, making it possible to traverse millions of records per second. - Comprehensive Data Management
Fully handle the retrieval, insertion, modification and deletion of data and underlying relationships. - Discrete Management
Add and modify data and relationships without having to make changes to the existing database schema, data or relationships. - Cypher Support
Fully support Cypher, the open-standard query language embraced by industry leaders. - Nonsubversion
Prohibit attempts to access or modify data via bypassing openCypher or subverting integrity rules and constraints enforced by the graph database. - ACID Transactions
Ensure that all transactions are ACID – i.e., follow the rules of Atomicity, Consistency, Isolation and Durability – to guarantee graph and data consistency. - Consistent Reads
Ensure that users who read and re-read data always see the same data unless others perform intervening updates. - Consistent Writes
Ensure that users who write and update data always see the latest data unless others perform intervening updates. - Integrity Independence
Store data-integrity constraints in the graph data catalog, not in application programs. - Data independence
Applications are logically unaffected when underlying graph data storage representations or access methods change. - Seamless Presentation
Store and display data relationship graphs in a unified manner to provide users a seamless view of the entire graph model of the database, regardless of where the data is stored.
Is Relational Technology Dead?
Does all this mean that the days of relational database technology are coming to a close? Certainly not.
Relational approaches are appropriate for tabular data with static schemas, but not for the demands of highly connected or changing datasets. And for queries that traverse multiple levels through graph data – such as friends-of-friends-of-friends queries – the resulting swarm of table index lookups relegates relational performance to unacceptable levels.
In stark contrast, graph databases use index-free adjacency to traverse millions of data records with sub-second response times, even when those queries mine data several layers deep.
Want to learn more on how relational databases compare to their graph counterparts? Get The Definitive Guide to Graph Databases for the RDBMS Developer, and discover when and how to use graphs in conjunction with your relational database.
Share Article



Explore
Related Articles
Optimize Weakly Connected Component Projections


Use Weakly Connected Components to Avoid Cypher Query Crashing