8 Solid Tips for Succeeding with Neo4j

Executive Manager Engineer Services, Neo Technology
10 min read

Editor’s Note: Last October at GraphConnect San Francisco, Chris Leishman – Executive Manager at Neo Technology – delivered this presentation on how to achieve optimal performance with Neo4j.
For more videos from GraphConnect SF and to register for GraphConnect Europe, check out graphconnect.com..
My name is Chris Leishman, and I’ve been with Neo Technology for about four years. Throughout this period, I’ve come to understand the successes and challenges customers have faced in their journeys to graph databases.
[NOTE: This post is a great complement to the blog post by Stefan Ambruster, which goes over Neo4j worst practices.]
The Origins of Neo4j
So — why do customers choose Neo4j? The first question you should really ask is — why did we create Neo4j in the first place?
Because we fundamentally believe that there is a better way to work with data. The best way to do this is by focusing on the relationships that exist in that data because it’s not enough to just have data; we want insight into our data.
With relational databases we have divided datasets stored in tabular structures. Consider the following example with flights, airports and cities:

To find out how the data is connected, we have to rely on a variety of foreign keys:
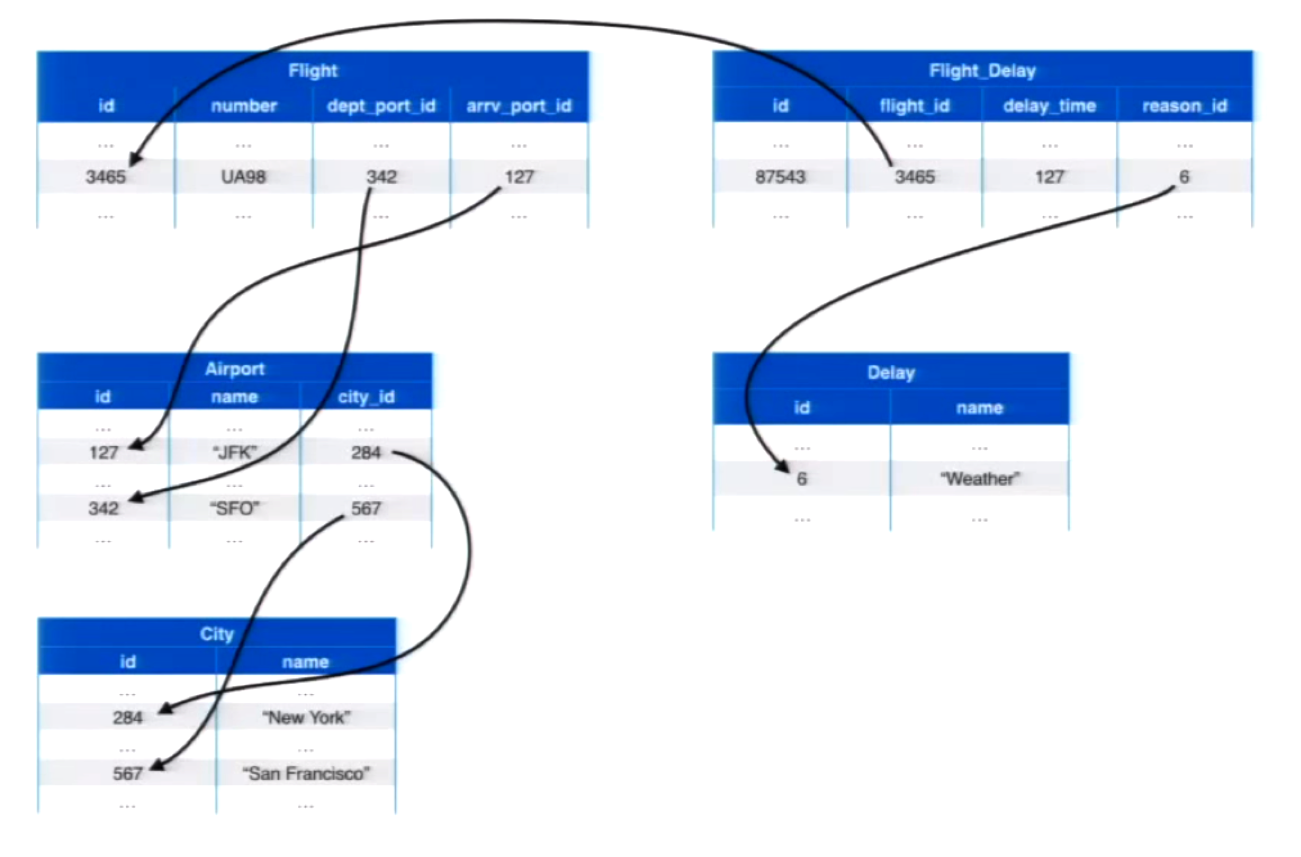
Below is exactly the same data drawn in a graph structure, which shows us much more quickly how the different data points are related:
Before graphs, we were almost entirely focused on how we store and retrieve data. Below is a model developed by one of my colleagues, Alistair, called the relational crossroads:

On the Denormalise side we have NoSQL, relational databases and databases such as Mongo and React that try to simplify data storage. By dividing and spreading out the data, we perform more rapid retrievals and updates to make our database very MapReduce-friendly.
On the other side you have Richer Model, which includes a more connected understanding about structured data, expressive power and fast traversals. So while the NoSQL community is exploring this denormalization approach for storage simplification, Neo4j is going down the richer model path to simplify the understanding instead.
When Emil first started Neo4j, he wanted to find a better way to build software than the hierarchical model that he had at his disposal. And once he had found that experience, we wanted to enable others to do the same. And that’s ultimately how Neo4j got to be here.
Now that we understand the history of Neo4j and what we’re trying to achieve, let’s dive into the eight best practices for using Neo4j.
Number 8: Use a Rich Data Model
The first place to start in data modeling is to identify your domains, i.e. the data points in your database. Are they people, seeds, products or relationships? A good book for software engineers to reference is called Domain-Driven Design by Eric Evans. Interestingly, a lot of the concepts in the book about software design apply to graph databases as well. This means that the models designers use in software can also be used in databases, which is very powerful because simplifies the code and the understanding.
The best way to start data modeling is to draw out your domain on a whiteboard. You can give anyone a whiteboard and a pen, talk about the problem they are trying to solve and end up with a drawn-out graph.
For example, if I want to talk to you about the cancellation of my flight from New York to San Francisco, I’ll draw a graph:

We found that when given a whiteboard and pen, person after person will draw exactly the same thing. And with a graph database you can translate this drawing into a few expressions, add some conditions and constraints, and you’ve already started modeling a database:


The best way to get really good at modeling is to study. The following resources are a great place to start:
- The entire Neo4j developer section has a lot of good information.
- Another thing: Don’t start from scratch — copy as many people as you can. Look at other peoples’ projects.
Tip #7: Use Cypher — Carefully
The purpose behind building Neo4j is to give you a better way to work with data. And how do you do this? With Cypher, a declarative, pattern-matching language for connected data.
Declarative means it’s a language in which you describe what you want. Rather than telling the database to do something specific, you describe what you want the database to give you. Pattern matching means we describe patterns, ask the database to match those patterns and return them.
If we want to know all the possible reasons our flight the SFO to JFK was cancelled, written in Cypher it would look like the following:

It’s amazing how easy it is to get this kind of information out of your data once you have a language like Cypher at your disposal.
Below are some helpful tools for transitioning from SQL to Cypher:
- Even though Cypher was inspired by SQL, it’s helpful to learn the major differences between the languages. This guide will help you transition from SQL to Cypher.
- The Cypher Developer Guide provides examples of all the different ways you can use Cypher.
- This guide will help you understand how Cypher queries are evaluated.
- You can also learn more in the Cypher Query Language Documentation.
- And finally, there are details in the actual Neo4j product that show you how to go from SQL to Cypher. The application includes the NorthWind dataset — a sample database that is well-known in the relational database community — and allows you to work with it in Neo4j as an introduction.
Avoid Cartesian Products
While there are huge advantages to using Cypher, it does have its own quirks. One thing you will need to learn how to avoid is a Cartesian product.
In the following example, we are looking for two people in our database so we write the following query:

This could work, but only if you have two people in your database. Even then there are two different results that will be returned:
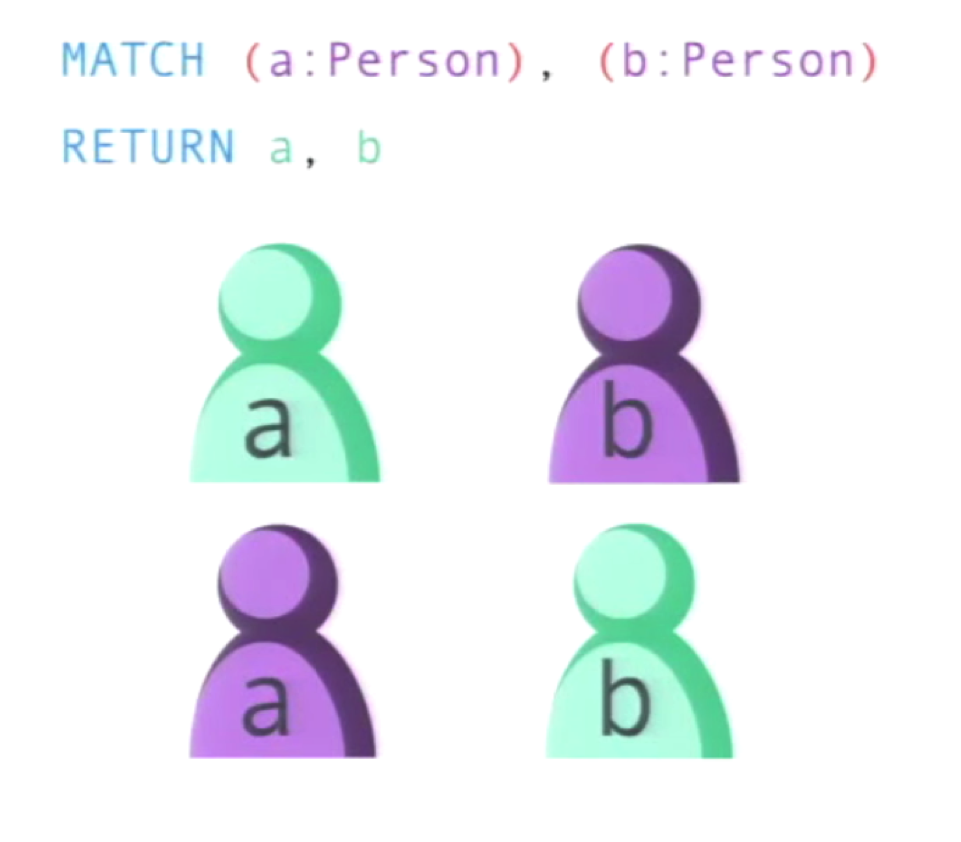
There are even more possibilities if you have three people in your database:

As you can see, you could very quickly end up with billions of results from what looks like a very simple query. Be sure to use the available query planners to help you avoid these types of queries.
Avoid Large Result Sets that Build Up Memory
Large result sets are the types of results returned from a Cartesian product, but can result from other types of queries as well. Large results will quickly fill up your memory storage, but there are tools available for streaming APIs that allow you to stream data rather than building up large result datasets.
Check Your Indexes and Use Labels
Make sure to use labels on your queries and nodes. When you’re writing multiple queries in Cypher, you can describe the corresponding labels for that query. Labels are a way of designating a node with a particular type, whether that be a person or a product (this will be specific to your own domain).
The only time you use an index is to find a specific node in a graph. Labeling your nodes prevents the index from searching through the entire database to find that one point you are looking for.
Let’s go back to my previous example with flights. I often want to look up airports by code or flights by name, so I add indexes for those in order to start my query at those types of nodes:

When the database performs the query, it will see that I’ve got an index on flight names, so it will start looking up data at the nodes labeled with flight. However, because we also created an airport code, it could start with a node labeled airport. The database will make a choice between the two indexes based on statistics along with a number of other factors that we won’t get into here.
Something to keep in mind with indexes is that each one needs to be maintained and stored on a disk. Query planning is a must when determining how to use indexes, because it will help you determine what types of questions you will ask, and therefore the types of indexes you’ll need.
Use Cypher PROFILE
To understand which index your database chose and whether or not it was the right one, you can use Cypher profiling. It’s a great tool to understand what your queries are doing and where the costs are:
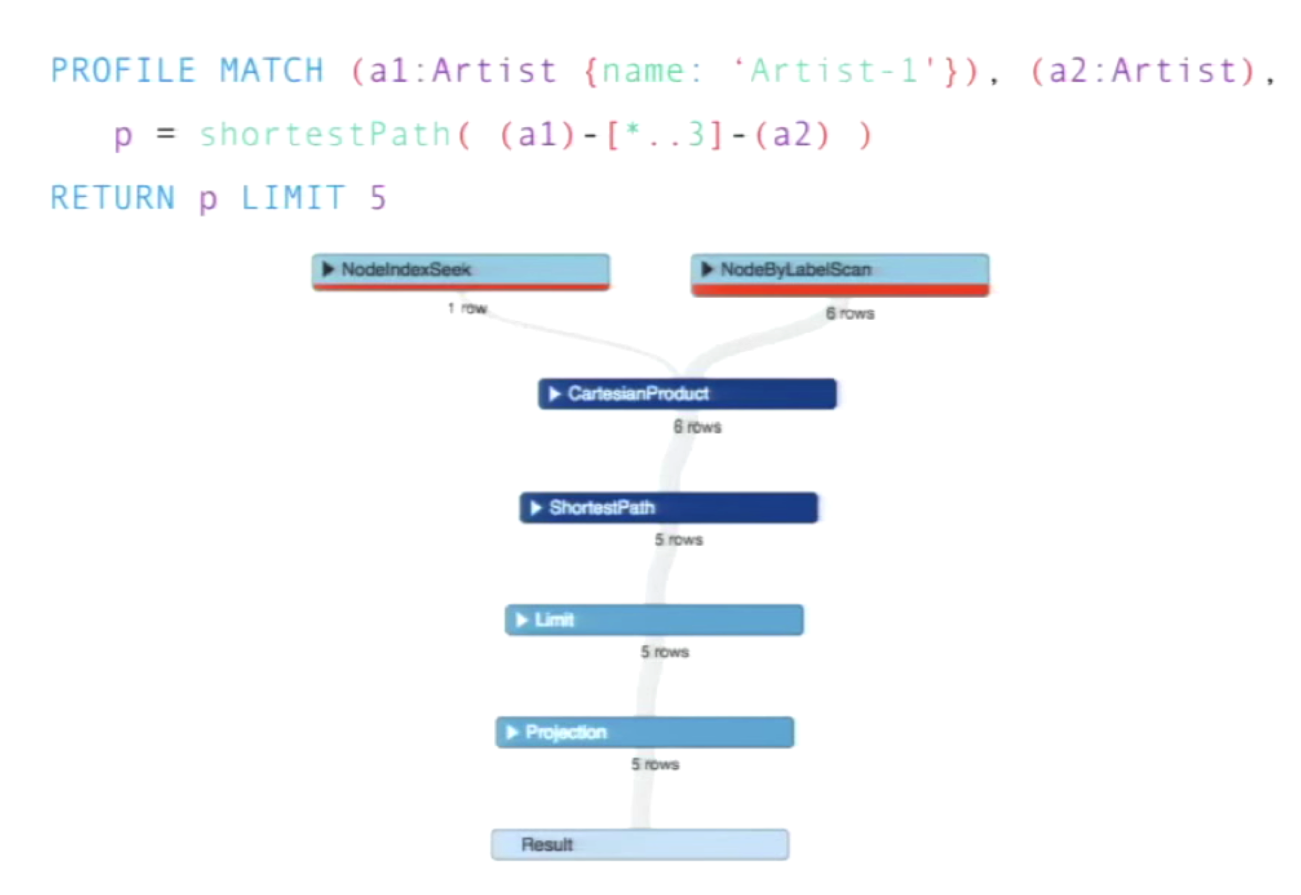
Based on this information, you can work with your team to figure out how to improve your queries.
Use Separate Queries
Cypher is a very powerful and expressive language that allows us to do much more than we could do in SQL. But just as in SQL, there are huge mistakes you can make in Cypher.
Don’t write extremely long, blocked queries. While Cypher can take many separate queries and chain them together in a dataflow using the WITH clause, you don’t have to do everything in one shot. You should never write code that looks like the below:

Tip #6: DON’T Use Cypher — Carefully
We think Cypher is fantastic, but we know it’s not for everything. Fortunately, we built Neo4j for developers, and it can be combined with a lot of other tools to be effective.
Neo4j was originally written as a driver, like an embedded database you could include into Java code for a developer to then build on top of:

Cypher is the very top surface of Neo4j. We have a REST API, and you can do a REST call to get back an individual node or an individual relationship.
A traversal API is built into the REST API and allows you to apply traversal descriptions written in JavaScript throughout the graph to retrieve information. The REST API also includes built-in graph algorithms such as shortest paths and A* algorithms. Java API gives you very specific low-level access to the graph.
Don’t Fear Server Extensions!
Java server extensions exist to solve a specific problem, and in some cases do so very well.
We’ve worked with many customers and taken queries that perform okay within Cypher, but their particular needs go above what Cypher can provide. The Java extensions can provide a vast increase in performance and provide very fine-grained control over how a query is run and allow you to optimize it far beyond anything a declarative language could do.
My colleague Max De Marzi is our guru of writing Java server extensions. He works with our customers and writes a lot of server extensions to solve of their problems. Max also runs a very prolific blog that includes posts on how to write server extensions and how to get the best possible performance out of Neo4j.
Below is a classic server extension written by Max, which is his warm-up routine:
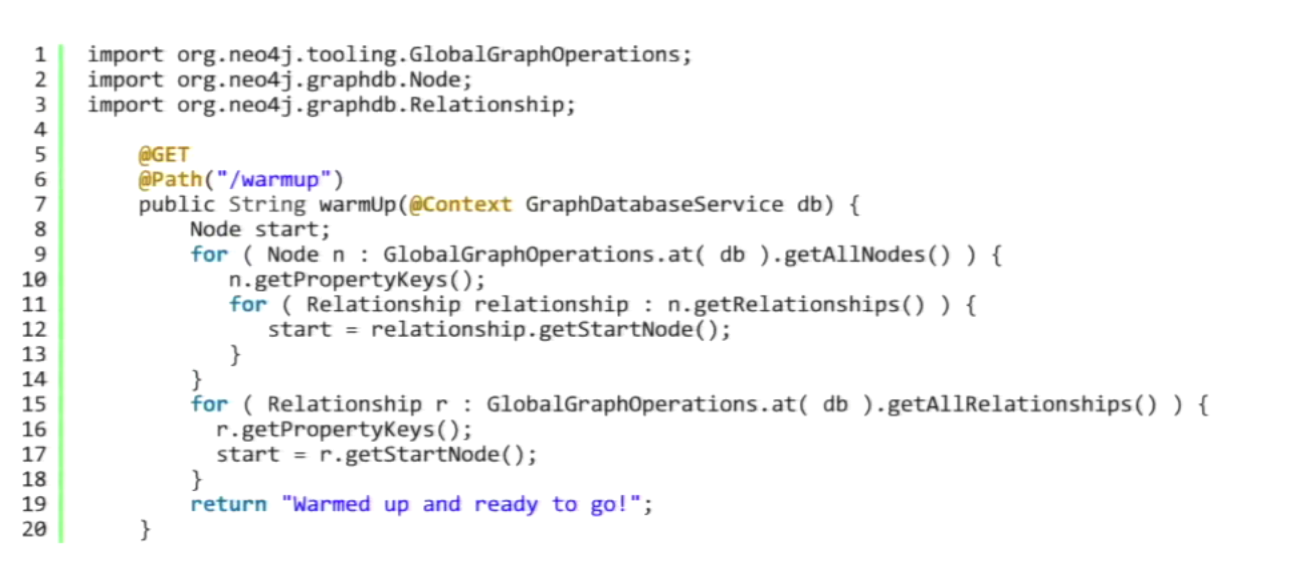
With this extension you hit the /warmup endpoint and it iterates through every node in the graph, loads it into memory and lets it go again. All it’s doing is bringing all those pages off disk into the page caches and warming everything up. At that point the system is warmed up and ready to go, giving the best performance possible.
Tip #5: Do Performance Testing
This is the number one thing people often miss. They’re excited to go into production and want to launch the product but end up having to stop everything at the last minute to try and figure out why something isn’t working properly. Max has written another great blog post on using Gatling with Neo4j for performance testing.
Tip #4: Tune the Server Configuration
Every server needs to be tuned for your environment. This will include configuring the page cache size which will allow you to use as much memory from the page as possible, preferably larger than the store file, while also allowing room for growth. And before you do anything else it’s important to turn on the GC logging, which will track your memory use. Keep in mind that it logs a lot of information so you do have to watch the size of the logs.
Monitoring GC pauses, which indicates pauses in the running of your application, is also important. In a production environment, this type of issue will cause you to run into trouble. So set your performance tests, run the tests, adjust your configuration, monitor and repeat either before every new release or after a significant growth in the size of your data.
Tip #3: Get a Cluster Running
A lot of people leave this until too late in their process of going live with Neo4j. Before deploying a cluster, they try and build everything on a single instance for as long as they can.
This can cause a lot of problems because the semantics are likely to change. Distributed systems are hard, but the best thing to do is embrace that pain as early as possible by using a cluster in your development/staging environment. There’s a lot of great information available on our website about how distributed databases work.
What you’re trying to learn with clustering is how data will move through your cluster. You write to a slave, it gets propagated to the master and the master propagates those out to all the slaves:

Another important tip: As early as possible in the application design process, figure out how to separate reads and writes. This will enable optimizations in terms of how you talk to Neo4j, as certain servers in the cluster will be better for accepting writes, while others are better for reads.
Tip #2: Pick an Awesome Driver
There are a number of great drivers available: Java drivers, .NET drivers, JavaScript drivers, Python drivers, Ruby drivers, PHP drivers and more. Get in touch with the driver authors to better understand their motivations and how they expect you to use their driver.
Tip #1: Have a Relationship with the Neo4j Team
Neo4j’s mission is to give people a better way to work with data. We want you to succeed, and having a relationship with us will make it much easier for you to achieve success. We’re very easy to get in touch with!
Inspired by Chris’ talk? Register for GraphConnect Europe on 26 April 2016 for more presentations, workshops and lightning talks on the evolving world of graph database technology.
Share Article



Explore
Related Articles
Optimize Weakly Connected Component Projections


Use Weakly Connected Components to Avoid Cypher Query Crashing
Property Sharding in Infinigraph: Smarter Scaling for Rich Graph Databases
Neo4j Launches Breakthrough Architecture to Unify Transactional and Operational Workloads