


We Just Closed the Largest Single Investment in the Graph Space. Now What?

CEO & Co-Founder, Neo4j, Inc.
4 min read
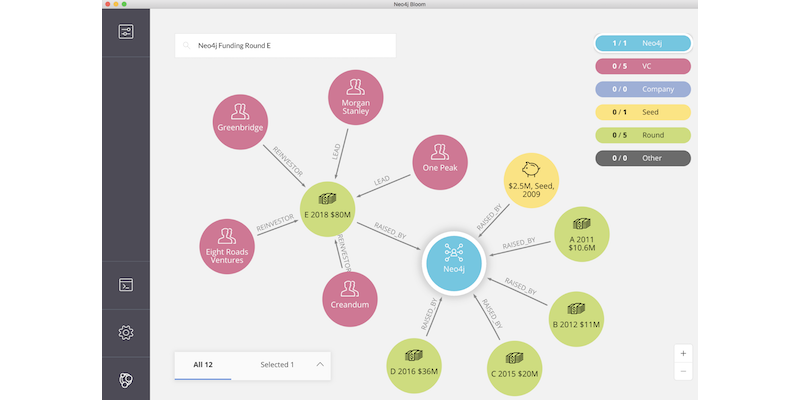
I’m thrilled to announce that Neo4j has just closed $80 million in a series E funding round.
We are happy to welcome One Peak Partners and Morgan Stanley Expansion Capital to the graph of Neo4j funders. I’d also like to thank all of our existing investors who participated in this round, including Creandum, Eight Roads and Greenbridge Partners. (Be sure to check out our official announcement with all the other details here.)
For those keeping track at home, Neo4j has now raised $160 million in growth funding, representing the largest cumulative investment in the graph technology category. I’m incredibly proud to be a part of that vote of confidence in the power of graphs.
So, where do we go from here?
A Quick Look Back at Our Series D
It’s been two years since we raised our series D round, and a lot has changed.
Two years ago, graph technology was just starting to go mainstream. For years before that, graph databases had been considered “boutique” or “niche” by analysts, journalists and development teams. But in late 2016, graphs hit an inflection point in enterprise adoption.
That inflection was due to the convergence of several factors: First, the maturity of our product made it possible for more and more enterprises to use Neo4j for mission-critical applications. At the same time, we’d reached a tipping point of awareness around specific use cases like fraud detection and real-time recommendation engines. This awareness was further reinforced by many of our enterprise deployments becoming publicly referenceable.
It was at this critical elbow of the adoption S-curve when we raised our Series D, perfectly positioning us to take advantage of the rapidly accelerating market.
Fast forward to today, and graphs are mainstream.
Connected data is an imperative for large organizations, and graph technology is on every enterprise shopping list. Businesses that don’t have a graph-powered solution are looking to get one, and those that already use graph technology are developing their second, third or fourth(!) application. Adoption is exploding and far past “going mainstream.”
I think this slide from my GraphConnect keynote says it best:

Why Fundraise, Why Now
So, why did we fundraise now?
One word: Adoption.
The graph paradigm shift is fully underway, and the demand for graph technology is accelerating faster than ever before. Our customers are pushing the envelope on the what, where and how of graphs. They’re asking for more, more, more of everything.
Raising this round is about meeting that demand. With our Series E, we’ll maintain our leadership in the space by continuing to build out the vision of our graph platform. Since day one, we’ve been singularly focused on making connected data accessible to developers through the Neo4j database. Now as we transition into a platform company, we retain that focus on accessible connected data but with an entire stack of native graph technologies.
But let’s double click on one particular factor that doesn’t just loom largest on the horizon of the graph space, but on the horizon of the entire tech space: artificial intelligence.
On the Near Horizon: Graphs and AI
Artificial intelligence and graph technology are at a critical crossroads. Graphs and AI have a symbiotic relationship that further strengthens and accelerates one another.
To prove to you, dear reader, that this isn’t just “AI washing” (!), let me take you back six years ago to GraphConnect 2012. We had maybe 150 people in the room (my six-month-old daughter was one of them), and our keynote speaker was Dr. James Fowler from UCSD.

At the risk of simplifying his research so much that I misrepresent it, here’s the crux of his presentation: Imagine two parallel universes. In the first universe, I know everything about you. I know your name, your gender, your height, your weight, your genes, your medical history, your diet, your schedule, your breakfast choices, etc. Everything.
In the second universe, I know nothing about you except that you exist. I don’t even know your gender, for example. But, in this universe I know just a bit about your friends and your friends of friends (your graph!). I don’t know them intimately – it’s sufficient to know whether they smoke or whether they plan on voting or whatnot.
Which universe do you think gives me the best information at predicting your behavior?
To a lot of people’s surprise, in the second universe – driven by connections – I can more accurately predict an individual’s behavior than in the first. Dr. Fowler proved this scientifically in his research, as chronicled in his book Connected.
In other words, predictions are best driven not by discrete, individual records but by relationships.
Let’s look at how that plays out in machine learning. Most machine learning pipelines look something like this:
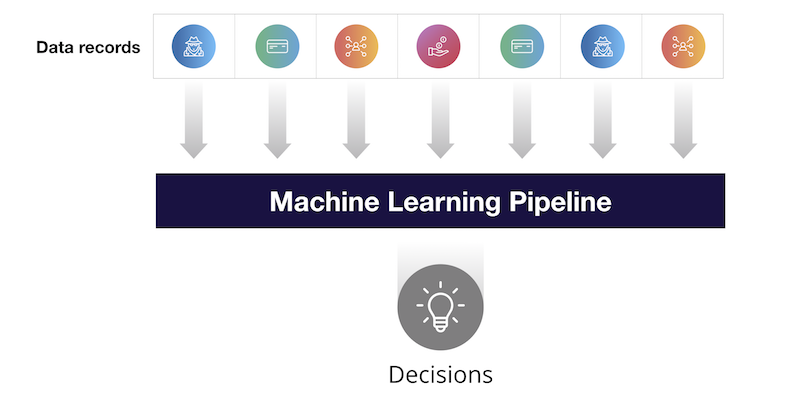
When we train our ML models, we use a sequence of discrete data records, almost like a row in an RDBMS. Each data point is identified and processed discretely. This is an example our first universe where we only know data about the individual.
What would machine learning look like in our second universe? It would use not just the individual data records, but how those records are connected (i.e., the graph) to train our ML models. Our new machine learning pipeline would look something like this:
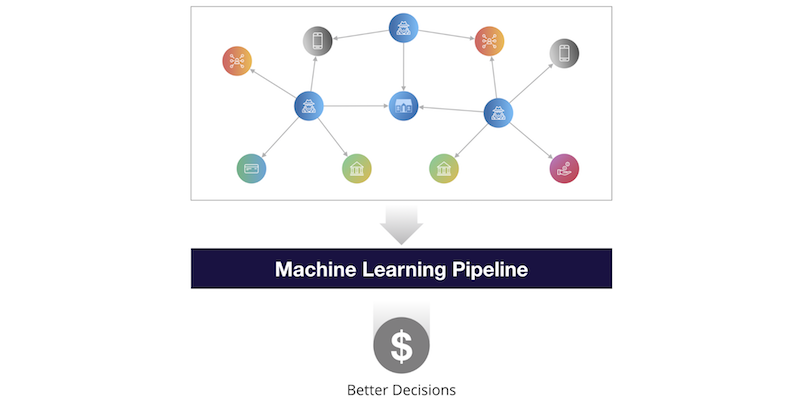
On the near horizon, I believe we’ll see the majority of machine learning shift from analyzing individual rows of data to also analyzing graphs of connected data. That shift will result in more accurate predictions and thus better decisions.
This change is happening already. Across every use case and industry, we’re seeing graph-and-AI deployments that feed one another with the much-needed context for each technology to grow to the next level, not just incrementally but exponentially.
We are on the cusp of a new Cambrian explosion of graph-powered artificial intelligence.
I believe it’s time to seize that opportunity.
Share Article


Explore
Related Articles




Neo4j Positioned as a Visionary in the 2024 Gartner® Magic Quadrant™ for Cloud Database Management Systems
6 min read
Neo4j Expands AWS Collaboration With New Competencies in Finance, Automotive, GenAI, and ML
5 min read