Better AI With Neo4j and Azure Machine Learning

Sr Cloud Partner Architect
4 min read

In a world of connected data, traditional machine learning techniques do not always tap relationships in and across data. Graphs are the ideal way to represent connected data. Graph data science got better and easier with Neo4j. It helps you unlock the insights trapped in rows and columns.
With more than 70 Data Science Algorithms in its toolbox, Neo4j makes it easier for Data Scientists to do machine learning In-Graph. With the Graph embeddings, connected data can be translated into predictive signals. Neo4j is a Microsoft Gold Partner listed on Azure Marketplace since 2017.
Azure machine learning (Azure ML) is a great platform to accelerate and manage machine learning product lifecycle. Graph Feature Engineering done inside Neo4j can be used to enhance a supervised learning model trained with Azure ML.
This blog post is about integrating Neo4j’s Graph Feature Engineering capabilities with Azure ML. The repository can be found here. The main intention of the post is on the integration aspects of Neo4j and Azure ML rather than model tuning and accuracy.
Why Graphs for Data Science?
Graphs are intuitive and the natural choice for connected data because they represent the way real-world data is. Due to the connected nature of these data, it is nearly impossible to completely represent them in traditional machine learning models. With Neo4j Graph Data Science, in-graph ML is getting a lot easier.
(neo4j)-[:PAIRS_WITH]->(azureML)
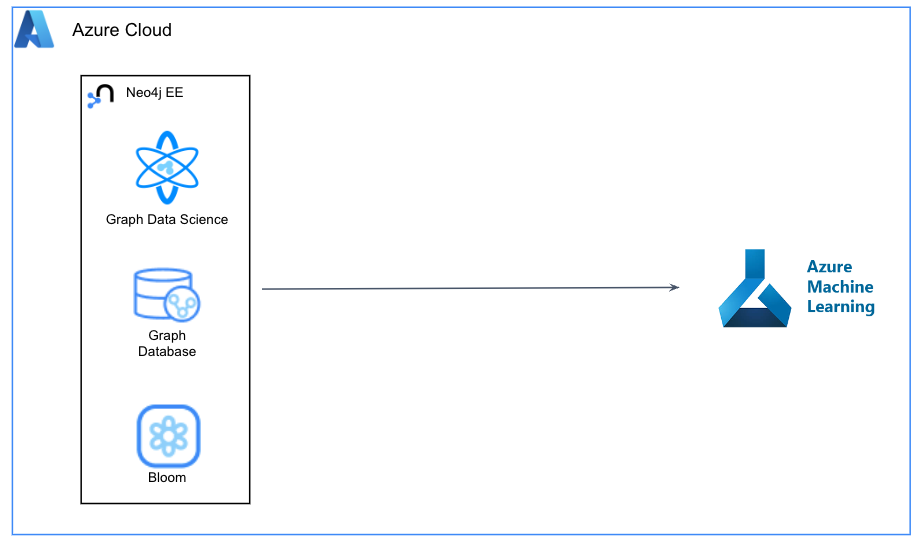
We are going to integrate Neo4j and Azure ML this way:
- From a notebook on Azure ML Studio workspace, connect to Neo4j using the GDS Python API
- Load CSV data into Neo4j using Cypher, Neo4j’s query language
- Create in-memory graph projections and node embeddings using Fast RP
- Export the embeddings to Azure ML and create an AutoML job for a supervised classifier model
Dataset
We will use a dataset on car insurance policies to detect potential fraudulent claims in the next 6 months. The dataset has more than 40 attributes like car specifications, policy holder’s age etc. The is_claim attribute denotes the target variable indicating whether the policyholder files a claim in the next 6 months or not.
Importing Data into Neo4j
Neo4j Enterprise Edition is available to install from within the Azure Marketplace. While installing, you need a blank target Resource Group. Also ensure that you select “True” for the “Install Graph Data Science” option. Rest of the values can be left to default.
We will be using a Notebook inside Azure ML Studio. You need to create a workspace inside Azure ML and attach a compute instance to it. Within the workspace, import the notebooks in this repository. Remember to change the Neo4j connection parameters before you load the data.
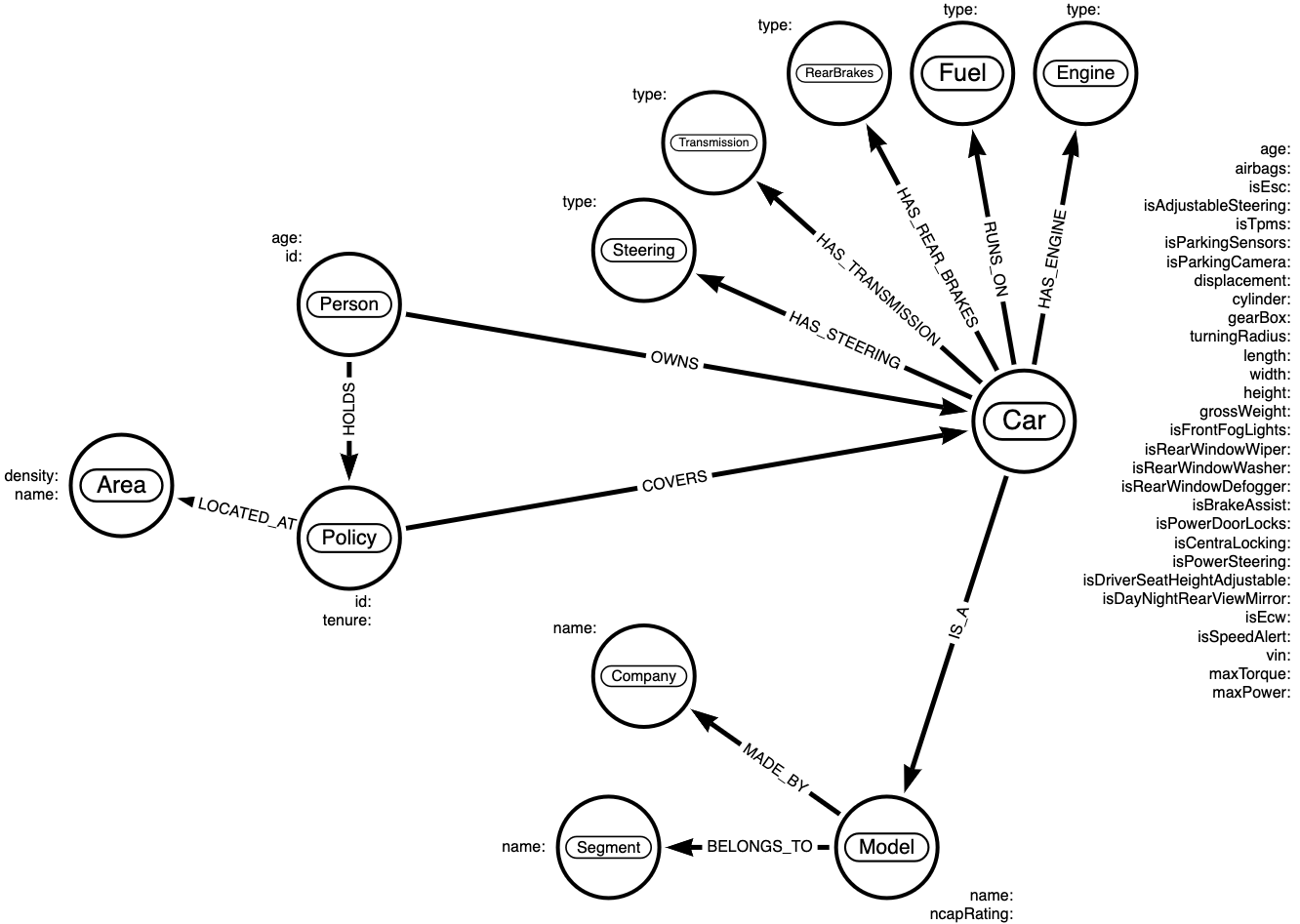
Data modeling is an important exercise before you create a graph. We will go with a simple model below for demonstrating purposes. In general, you should model your data based on the questions you ask.
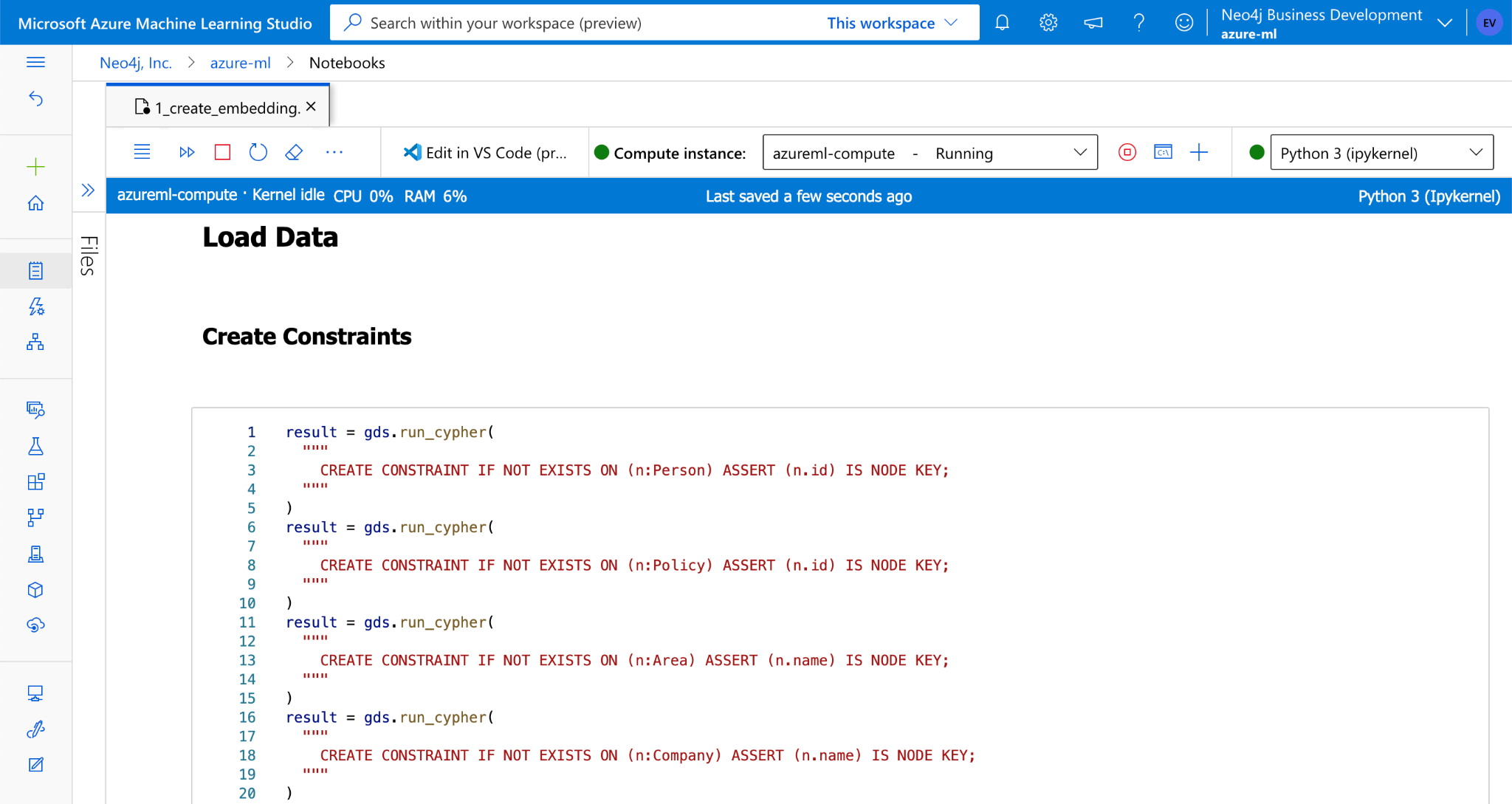
Creating constraints on your node will ensure that duplicate nodes are not created with the same node keys. We can use Cypher to create constraints and load the CSV data to Neo4j inside the notebook via the Python API.
Node Embeddings
Let’s now transform the graph into numbers using Neo4j Graph Data Science. Embeddings take all the information and translate it into a single vector that encodes the nodes, relationships and properties we choose. This is similar to a portrait that converts a three dimensional representation of a person to two dimensions. This way, we are adding contextual information for each node.
Firstly, we need to create a projection graph choosing the nodes and relationships. The algorithm we are using is FastRP, a random projection algorithm to create the embedding from this projection. Let’s create the embedding vector of size 16. If you prefer more precision over high operating cost, you can go for a higher dimension.
CALL gds.fastRP.mutate('projection',{
embeddingDimension: 16,
randomSeed: 1,
mutateProperty:'embedding'
})
Embeddings can then be persisted to the holding node in the database. In this case, let’s write them to the Policy nodes. Now, we are good to grab all the Policy nodes enriched with the embeddings and reformat as Pandas Dataframe
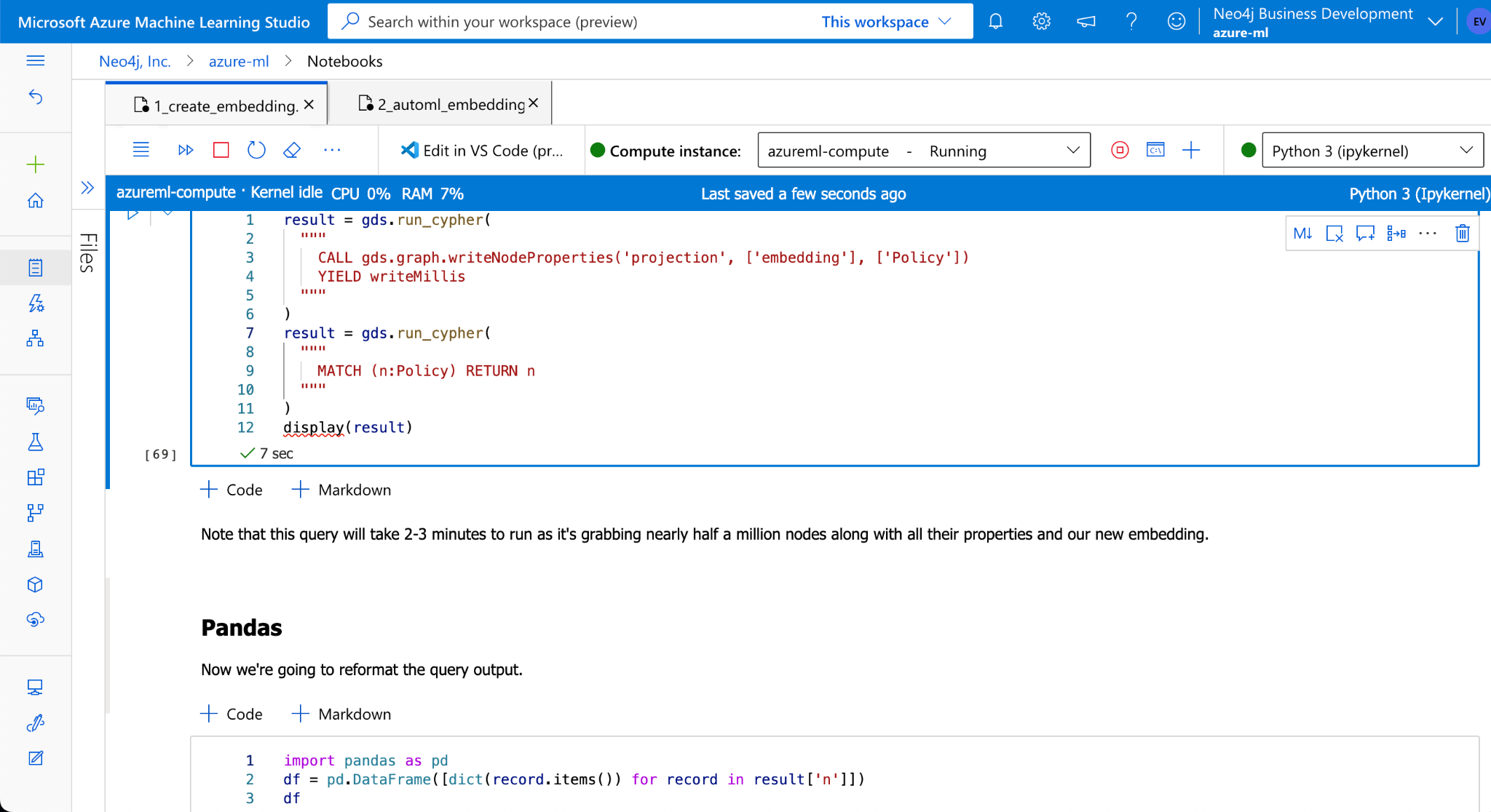
Integration With Azure ML
With enriched Policy data, we can further integrate to an existing pipeline by uploading to AzureML. We can create an AutoML job to create a best performing model to predict policy claims based on the enriched data. Azure ML provides an explain capability to give more insights on the model that AutoML considered for the supervised learning task. You can also see the top features by importance and can export them to a feature store.
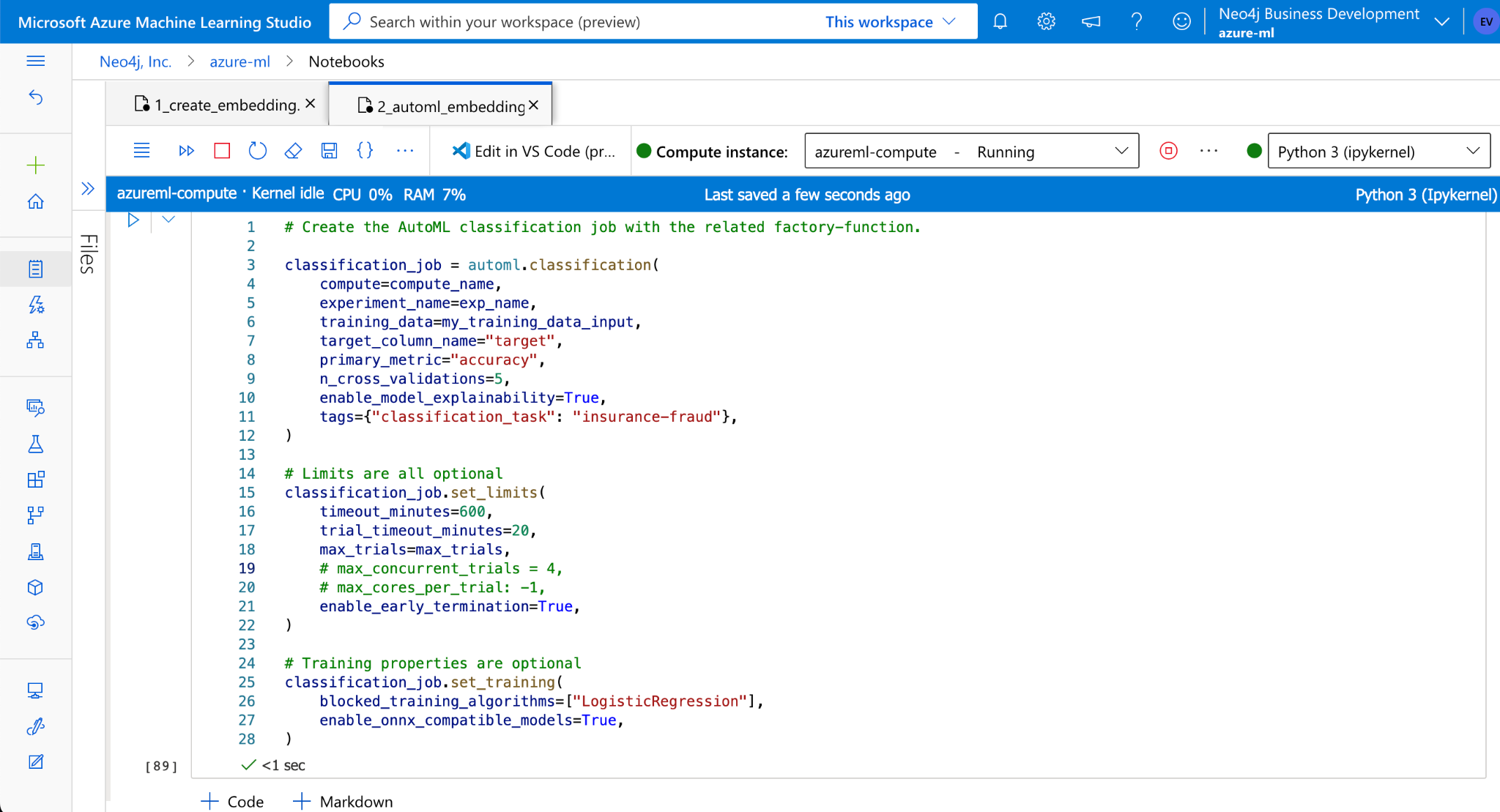
Conclusion
This post is more of an introduction to Neo4j integration with Azure ML. There are more than 70 Data Science Algorithms in Neo4j’s toolbox which can be used to solve a plethora of interesting graph problems across verticals from finance to gaming. Graphs are a perfect and natural way to represent your data as-is from your white boarding. Embeddings help to mathematically convert this representation and incorporate it into a traditional machine learning workflow.
Share Article