
Combating Money Laundering: AML Graph Algorithms

Enterprise Account Manager
3 min read

Money laundering is among the hardest activities to detect in the world of financial crime. Funds move in plain sight through standard financial instruments, transactions, intermediaries, legal entities and institutions – avoiding detection by banks and law enforcement. The costs in regulatory fines and damaged reputation for financial institutions are all too real. Neo4j provides an advanced, extensible foundation for fighting money laundering, reducing compliance costs and protecting brand value.
In this fifth blog in our six-part series on using graph technology to fight money laundering, we discuss using graph algorithms for investigating entities and identifying high-risk payment chains.
Graph Algorithms to Resolve Entities
Graph algorithms dramatically increase the accuracy of entity resolution by providing
information regarding relationships at the network level rather than at the individual entity
level. Graph algorithms are applied globally across graphs or sub-graphs and leverage the
information inherent in relationships. Those scores are then used to support tailored pattern
matching that in turn feeds into machine learning pipelines for more accurate predictions.
The entity resolution process follows these steps:
- A linear combination of string and shared-attributes similarity scores are used to create
pairwise-weighted relationships across a graph of similar entities such as individuals and
corporations - The Weakly Connected Components algorithm segments the graph into clusters
- The Label Propagation graph algorithm determines within each cluster which entity best
represents the other entities in the cluster
The first step of creating pairwise-weighted relationships uses Cypher queries to create a
weighted ENTITY_RESOLUTION relationship. The Cypher queries utilize stored procedures for
Jaro-Wrinkler, Levenshtein and Sorensen-Dice algorithms along with graph attributes such as
current residence distance.
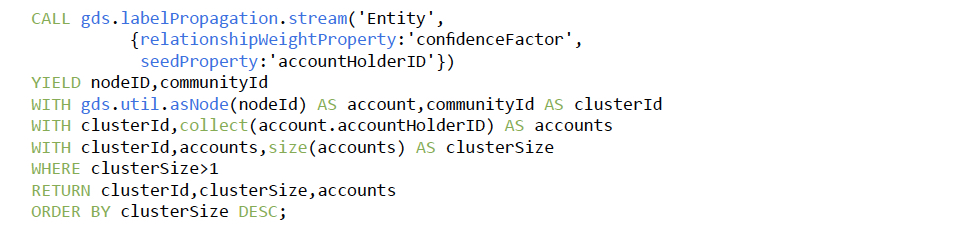
The following script creates an in-memory graph named Entity of the account holders
nodes that uses the ENTITY_RESOLUTION as relationships among these nodes and the
confidenceFactor property as weights for these relationships.

The Label Propagation algorithm is executed on this in-memory graph – using the
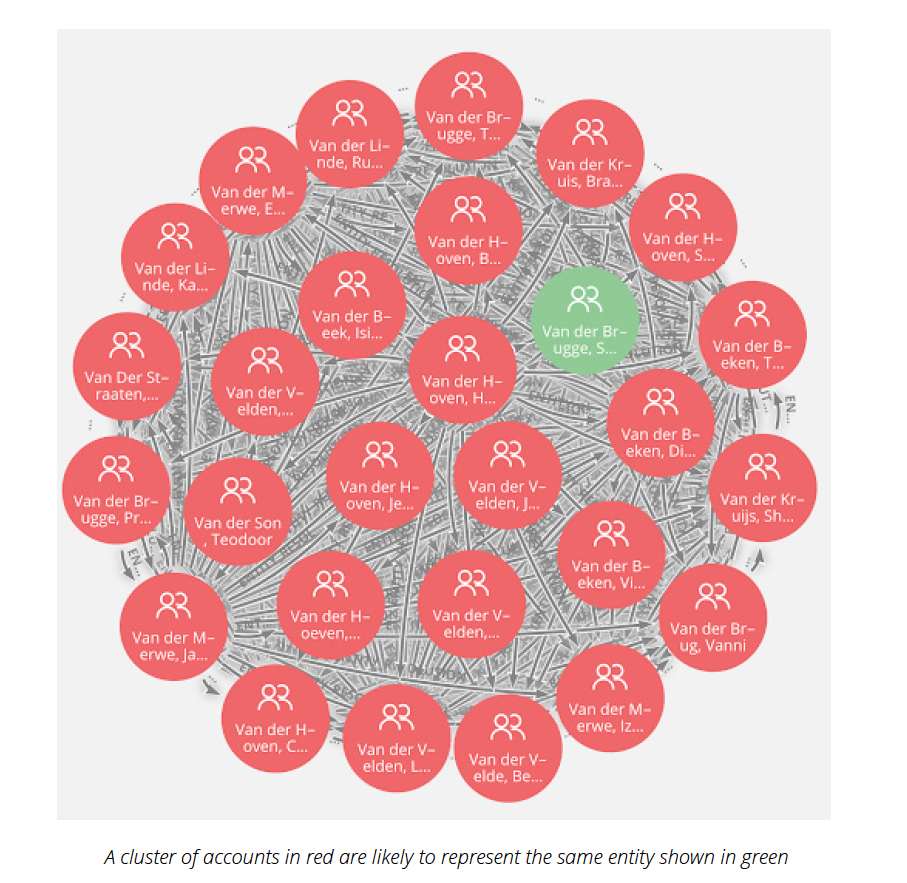
accountHolderID as seeds – to identify clusters of account holders that potentially represent
the same entity. Since the ID of account holders are seeds, the clusterID represents the
most likely identity represented by the accounts in the cluster.

Graph Algorithms to Identify Payment Chains
To identify money laundering networks potentially being used by high-risk accounts, create
a property named highRisk. This property identifies account holders in a high-risk watch
list. These accounts potentially use the networks of money transfers identified by Weakly
Connected Components to conduct money laundering. Centrality algorithms detect liaisons,
central and more relevant players in these money transfer networks. Clustering algorithms,
Louvain Modularity and Strongly Connected Components can be used to identify subnetworks
and high-risk rings, respectively.
If there is a path between a customer and a high-risk end point, then Jaccard, Cosine or
Overlap Similarity algorithms indicate how similar each path is to other paths from that
specific customer to those high-risk endpoints. Then create a subgraph of paths and
have weighted relationships representing similarities among the paths. Pathfinding and
search algorithms identify payment chains and third parties layered between customers or
transactions and other endpoints.
To illustrate, the following script loads an in-memory graph of money transfers between
account holders.

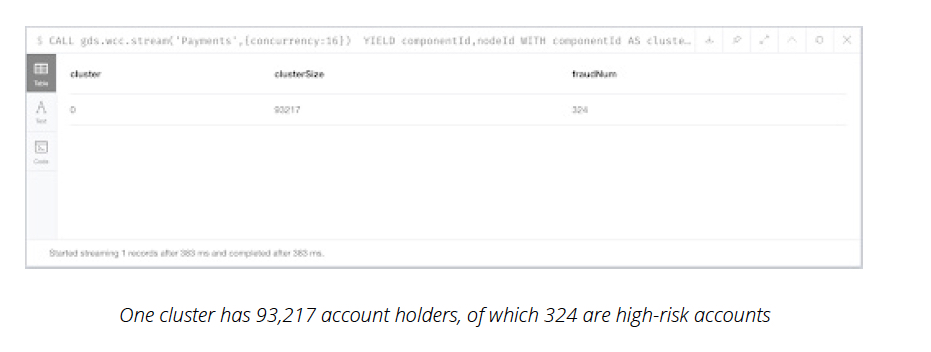
On this in-memory graph, the following script executes Weakly Connected Components (WCC)
to identify a cluster of account holders in a payment chain that high-risk accounts use to
conduct money laundering.

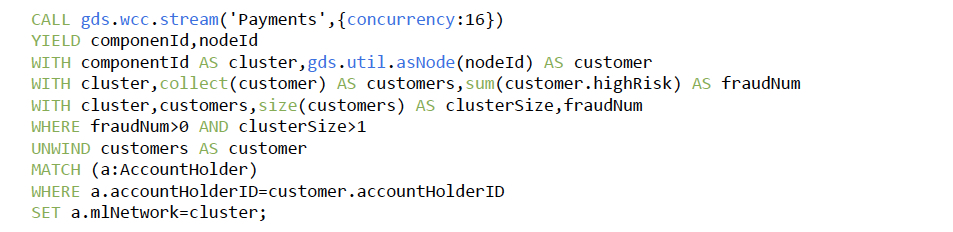
Each customer has a property called amlNetwork. The WCC algorithm updates this property
for every customer in the cluster.
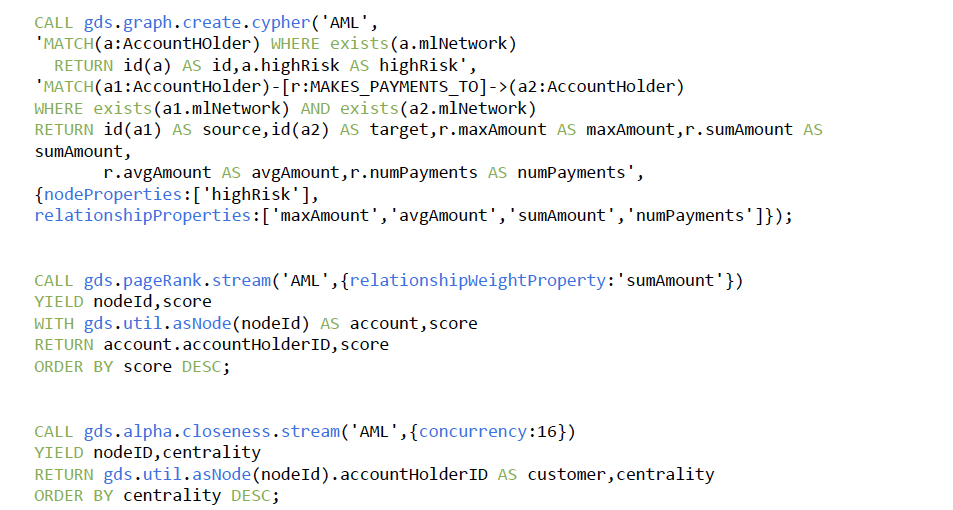
The following scripts create an in-memory graph named AML and execute three more algorithms:
- PageRank detects the most relevant players in the network
- Closeness detects the accounts that are closer to any other account (by number of hubs)
- Louvain identifies subnetworks. Each of these subnetworks can be used to prioritize the anti-money laundering investigation based on the size of the clusters and the relevance (PageRank score) of the accounts contained in each cluster


Conclusion
As we’ve seen, graph algorithms streamline important AML tasks such as entity resolution, the process of gathering a complete body of data about a particular item or object, and identifying high-risk payment chains.
Next week, in our final blog in this series, we’ll look at the exciting area of graph data visualization, showing views of money queries targeted to audiences from executives to analysts to data scientists and power users. We’ll also highlight the benefits compliance teams reap when using Neo4j.
Stop money laundering in its tracks. Click below to get your copy of How to Combat Money Laundering Using Graph Technology.
Share Article



Explore
Related Articles

Optimize Weakly Connected Component Projections

Use Weakly Connected Components to Avoid Cypher Query Crashing
GraphRAG in Action: A Simple Agent for Know-Your-Customer Investigations

Mastering Fraud Detection With Temporal Graph Modeling
