

Agentic AI With Java and Neo4j

Director of Engineering, Neo4j
19 min read

In my earlier GenAI blogs, we’ve looked at the basics of vector embeddings and vector search and how to apply it for GraphRAG.
Now we’ll take it one step further using agents to interact with our graph. And as the title suggests, we’ll do it with Java.
There’s a lot of support for writing agents in Python, but — at least when I started this post — there wasn’t as much for Java (*at least not that I found). Now someone may ask me, “Well, why would you want to do it in Java if it lacks good libraries?” And my answer would be, “Because there are no good libraries for C, either.”
*After finishing this post, I was pointed to the Embabel Java/Kotlin agent library by Rod Johnson that looks very powerful. So let’s consider my library a small lightweight option for learning the concepts.
All code in this blog post, as well as the full implementation of the library and the demo, is on GitHub.
But let’s start at the beginning.
What Is Agentic AI?
AI agents are LLM models, configured for a specific task and given a certain set of tools to perform that task. If you asked ChatGPT to make you a cup of coffee, it would semantically know what you’re asking for, but it wouldn’t be able to make the coffee. But if you gave it a coffee machine (or a digital connection to one) and told it how to operate it, it would be able to give you that coffee. The trick is to let the LLM plan how to achieve the task using (some of) the tools in a loop to get information or perform actions.
Agents allow you to do a variety of things, from programming to booking train tickets. But for the purpose of this blog, we’ll look at cases similar to those we had for GraphRAG (e.g., chatting with an LLM about information that resides in a graph).
In traditional GraphRAG, we take the question from the user, then combine vector search and graph traversal to figure out what parts of the graphs could be relevant to the LLM to answer the user’s question, and we provide that context to the LLM (and only that).
With agentic GraphRAG, we instead give the LLM the tools (means) it would need to traverse the graph itself. So it gets access to the entire graph and can determine what it wants to see, and it can decide what tools to use based on the question and the result of earlier tools used.
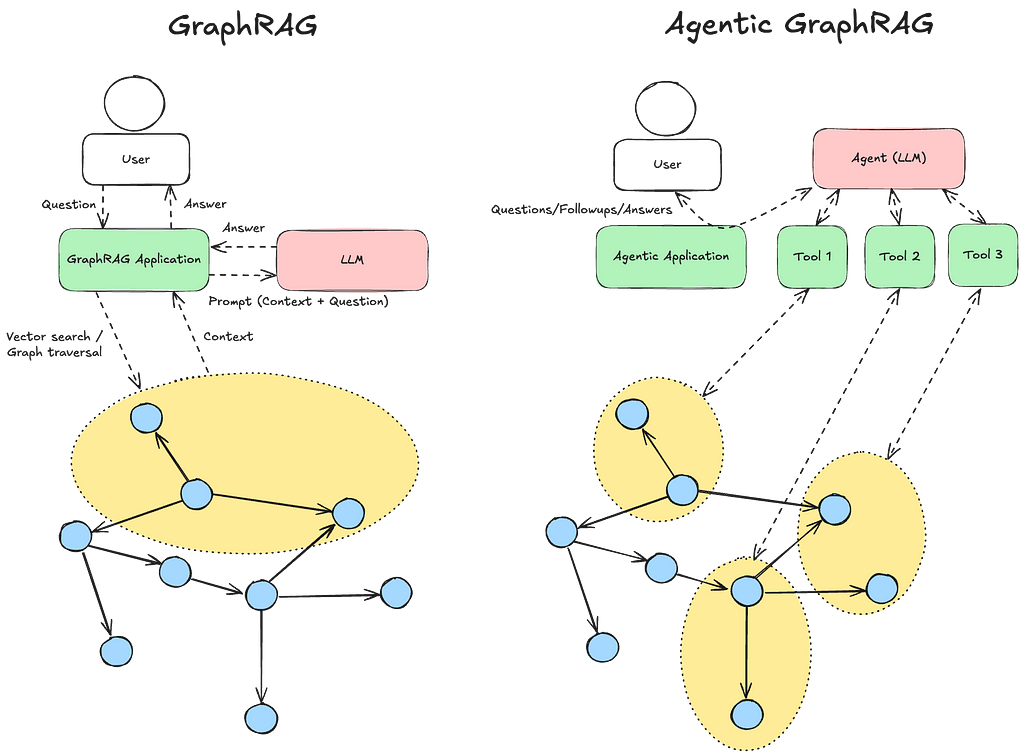
The challenge with traditional GraphRAG is that, depending on the application/data, it may be difficult to know how to traverse the graph to find the relevant information. It may depend on the question or the user’s environment.
In the example we had in GraphRAG in (Almost) Pure Cypher, the question was about Game of Thrones, and since we knew the question was about a TV series, we knew we should traverse the EPISODE_OF relationships.
But if the question had been about James Bond, we would probably have wanted to traverse via the author (Ian Fleming) instead. With agentic GraphRAG, we give the agent the tools to navigate and retrieve in different ways that we think may make sense and let it decide how to do it based on the question and prior information in the conversation.
The Use Case
Our use case for this article is a simple example I implemented with regular GraphRAG before.
Some of our development teams (the Neo4j Aura Cloud Service teams) use Stack Overflow for Teams as a forum for questions about the development environment and other programming questions related to our local development environment and processes. We exported all this knowledge to JSON files (see below), which we then imported into a Neo4j graph with a model that looks like this:
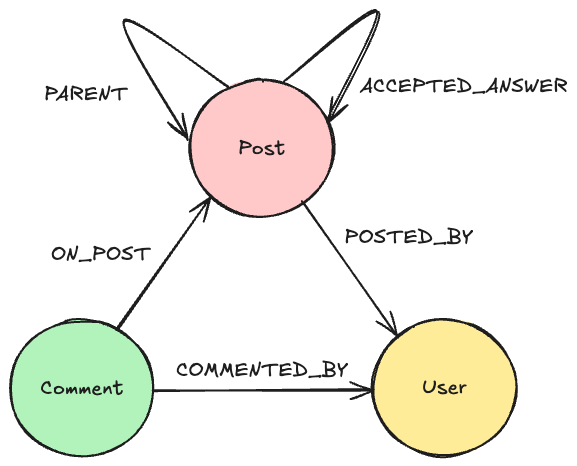
Every post has a body property, and the original question has a title. The comment has a text field. We added vector embeddings on both the title and the body of the posts, but not on comments or users.
To export the data from Stack Overflow for Teams, go to Admin settings > Account information and click Download data.
This is the Cypher used to import the Stack Overflow exported JSON files to a Neo4j instance (this works both on-prem and on Aura, but for Aura, you need to put the files somewhere that can be accessed by Aura):
// Clean up database
MATCH (n) DETACH DELETE n;
// Create indexes
CREATE INDEX post_id IF NOT EXISTS FOR (p:Post) ON (p.id);
CREATE INDEX comment_id IF NOT EXISTS FOR (c:Comment) ON (c.id);
CREATE INDEX user_id IF NOT EXISTS FOR (u:User) ON (u.id);
CREATE INDEX user_displayname IF NOT EXISTS FOR (u:User) ON (u.displayName);
CREATE VECTOR INDEX title_embeddings IF NOT EXISTS FOR (p:Post) ON (p.title_embedding);
CREATE VECTOR INDEX post_embeddings IF NOT EXISTS FOR (p:Post) ON (p.body_embedding);
// Import users
CALL apoc.load.json("users.json", null, {failOnError:false}) YIELD value
UNWIND value AS user
MERGE (u:User {id: toInteger(user['id'])})
SET u.created = datetime(user['creationDate']),
u.goldBadges = toInteger(user['goldBadges']),
u.silverBadges = toInteger(user['silverBadges']),
u.bronzeBadges = toInteger(user['bronzeBadges']),
u.reputation = toInteger(user['reputation']),
u.accountId = toInteger(user['accountId']),
u.userTypeId = user['userTypeId'],
u.realName = user['realName'],
u.displayName = user['displayName'];
// Import posts
CALL apoc.load.json("posts.json", null, {failOnError:false}) YIELD value
UNWIND value AS post
MERGE (p:Post {id: toInteger(post['id'])})
SET p.created = datetime(post['creationDate']),
p.score = toInteger(post['score']),
p.postType = post['postType'],
p.title = post['title'],
p.body = post['bodyMarkdown'],
p.acceptedAnswerId = post['acceptedAnswerId']
WITH post, p
OPTIONAL MATCH (u:User)
WHERE (u.id = toInteger(post['ownerUserId']) OR u.displayName = toInteger(post['ownerDisplayName']))
FOREACH (_ IN CASE WHEN u IS NOT NULL THEN [1] ELSE [] END | CREATE (p)-[:POSTED_BY]->(u))
WITH post, p
MATCH (parent:Post {id: toInteger(post['parentId'])})
CREATE (p)-[:PARENT]->(parent);
// Connect accepted answers
MATCH (p:Post)
WHERE p.acceptedAnswerId IS NOT NULL
MATCH (a:Post {id: p.acceptedAnswerId})
MERGE (p)-[:ACCEPTED_ANSWER]->(a)
REMOVE p.acceptedAnswerId;
// Import comments
CALL apoc.load.json("comments.json", null, {failOnError:false}) YIELD value
UNWIND value AS comment
MERGE (c:Comment {id: toInteger(comment['id'])})
SET c.created = datetime(comment['creationDate']),
c.text = comment['text']
WITH comment, c
OPTIONAL MATCH (u:User)
WHERE (u.id = toInteger(comment['userId']) OR u.displayName = toInteger(comment['userDisplayName']))
FOREACH (_ IN CASE WHEN u IS NOT NULL THEN [1] ELSE [] END | CREATE (c)-[:COMMENTED_BY]->(u))
WITH comment, c
MATCH (p:Post {id: toInteger(comment['postId'])})
CREATE (c)-[:ON_POST]->(p);And here’s the Cypher to create the vector embeddings:
MATCH (p:Post)
WHERE p.title IS NOT NULL
WITH collect(p.title) AS titles, collect(p) AS posts
CALL genai.vector.encodeBatch(titles, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(posts[index], "title_embedding", vector);
MATCH (p:Post)
WHERE p.body IS NOT NULL
WITH collect(p.body) AS body, collect(p) AS posts
CALL genai.vector.encodeBatch(body, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(posts[index], "body_embedding", vector);Now we built a simple GraphRAG application that allowed a user to ask a question that OpenAI would attempt to answer based on the information in this graph. The single Cypher query we had to fetch the context for the prompt looked like this:
WITH genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('post_embeddings', 2, embedding) YIELD node AS p, score AS pscore
MATCH (p)((:Post)-[:PARENT]->(:Post))*(parent)
WITH embedding, collect(parent) AS parents
CALL db.index.vector.queryNodes('title_embeddings', 2, embedding) YIELD node AS q, score AS qscore
WITH parents, collect(q) AS posts
WITH parents+posts AS questions
UNWIND questions AS question
MATCH path = (question)((:Post)<-[:PARENT]-(:Post))*
WITH question, nodes(path) AS posts
UNWIND posts AS post
OPTIONAL MATCH (post)<-[:ON_POST]-(comment:Comment)
WITH DISTINCT comment, post, question
WITH question, post, COLLECT(comment.text) AS comments
WITH
CASE
WHEN post = question THEN '***QUESTION***\nTitle: ' + post.title + '\nBody: ' + post.body
ELSE '***ANSWER***\nBody: ' + post.body
END
+
CASE
WHEN SIZE(comments) > 0 THEN '\n***COMMENT***\n' + apoc.text.join(comments, '\n***COMMENT***\n')
ELSE ''
END
AS postText
WITH DISTINCT postText
RETURN apoc.text.join(COLLECT(postText), '\n\n') AS contextAnd the prompt question looked like this:
Answer the following Question based on the Context only.
Only answer from the Context. If you don't know the answer,
say 'I don't know'. The context is a list of posts and comments,
separated by headers in the form of ***QUESTION***, ***ANSWER***
and ***COMMENT***.
Context: ${context}
Question: ${question}This works, and the bot often gives a relevant answer based on the knowledge base we provide. However, it seemed we could make it better. As you see, we aren’t using the ACCEPTED_ANSWER or the scores of the answers. And maybe the user objects could provide some guidance to the answer as well. So let’s build an agentic solution on top of the same source data.
The Implementation
An Agentic Framework in Java
Let’s start by writing our small library for AI agents in Java. I’ll focus on OpenAI here, but you could of course extend it for others as well. My goal was to make it as simple as possible to write/register an agent and define the tools.
Before starting on the implementation, let’s have a look at how agents work (and as I said, we’re only looking at OpenAI right now).
You can manually register your agent with OpenAI. When registering your agent, you give it a name and some system instructions that tells it its purpose (i.e., what to do when given prompts). For example, “You are a calculator and should perform computational operations as asked by the user.” You also register the tools you will provide it. You give this in JSON format, such as:
{
"name": "sum_integers",
"description": "Summarise two integer numbers",
"parameters": {
"type": "object",
"properties": {
"number1": {
"type": "integer",
"description": "The first number to sum"
},
"number2": {
"type": "integer",
"description": "The second number to sum"
}
},
"required": ["number1", "number2"]
}
}You may notice that you specify the parameters, not the return result. The return result is any JSON in any format you want, but it should be self-explanatory to the agent how to interpret it, and you can provide hints to it in the tool description.
When you’ve registered your agent, you’ll get an assistant ID in the format of “asst_***************” This is what you’ll use when communicating with your agent.
Now you need to write your application that communicates with the agent, which also executes the tools when the agent so wishes. The first thing that the application needs to do is to start a thread with the agent.
This should not be confused with a thread as in parallel processing (like the Java Thread class), but rather a thread of discussion as you will find in the sidebar of the ChatGPT UI.
Once you have a thread, you send the question to the thread and poll it for status to see if it wants to run a tool or if it has a response ready. When you have a response, you can proceed with a follow-up question if you want to.
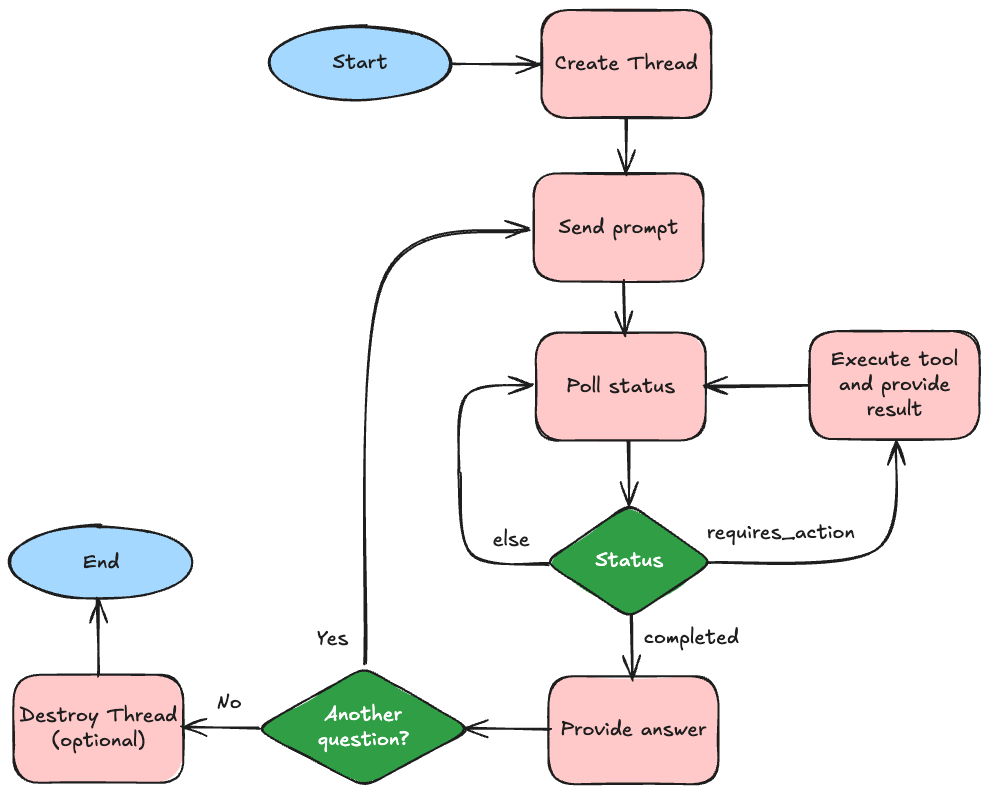
When it wants you to execute a tool, you get a JSON structure telling you what tool and the parameter values, and you have to perform the task and provide the result back.
And here comes the first challenge of our framework: How should your application define the tool methods in a way for the framework to know what to call when it gets the request from the agent?
My first thought was to have an interface called Tool, which would have a method to retrieve the name of the tool, and an execute method that would take and return a JsonObject. But that doesn’t seem elegant. And it doesn’t seem right to have the implementation so disconnected from what we manually register with the agent.
So instead, I’ve done it so that you define your tools as regular Java methods, and we use reflection to figure out what to run, but we also use reflection (together with some annotation) to register the agent. So instead of registering manually with the URL above, we register the agent programatically based on what the application implementation actually looks like. To help, we have two components: a base class called AbstractAgent and an annotation called description. So to make your agent, you make a subclass to AbstractAgent and you add a @description annotation for the class (which will be the agent’s system instructions), for the methods (which will be the tool description), and for every parameter the tools require.
Note that for this reflection to work, you have to compile your Java project with the -parameters compiler option.
@description("You are a calculator and should perform computational operations as asked by the user")
public class MyAgent extends AbstractAgent {
public MyAgent() {
super("sk-proj-.......", "asst_.......", 60000, false);
}
@description("Summarise two integer numbers")
public int sum(@description("The first number to sum")int a, @description("The second number to sum")int b) {
return a + b;
}
@description("Multiply two integer numbers")
public int mult(@description("The first number to multiply")int a, @description("The second number to multiply")int b) {
return a * b;
}
}The AbstractAgent will have a static method for registering it, which you can call like this:
System.out.println(AbstractAgent.registerAgent(MyAgent.class,
"sk-proj-......."));What it prints out is what will be the assistant ID of your assistant. After registering, you’ll be able to find it on the OpenAI assistant page. The second argument is the OpenAI API key you need for all communication with the agent. This registration should only be done once, then you hard-code the assistant ID in your application and don’t call it again (unless you change the Tool signatures).
The parameters to the base class are that same OpenAI API key, the assistant ID from the command above, the timeout (in ms) to use for agent calls, and whether you want debug output (i.e., printouts of the tools called).
The communication with OpenAI is over a REST API, and we’ll use Apache HttpClient for that. Then we’ll use Google Gson for the JSON parts. All REST calls are similar. Creating a thread for example would look like this:
private static final String BASE_URL = "https://api.openai.com/v1";
private static final HttpClientResponseHandler<String> stringResponseHandler = response -> {
int status = response.getCode();
if (status >= 200 && status < 300) {
return new String(response.getEntity().getContent().readAllBytes());
} else {
throw new IOException("Unexpected response status: " + status);
}
};
private final CloseableHttpClient client = HttpClients.createDefault();
private final String apiKey;
private final String assistantId;
private final long timeoutMs;
private final boolean debug;
protected AbstractAgent(String apiKey, String assistantId, long timeoutMs, boolean debug) {
this.apiKey = apiKey;
this.assistantId = assistantId;
this.timeoutMs = timeoutMs;
this.debug = debug;
}
public AgentThread createThread() throws AgentException {
try {
HttpPost post = new HttpPost(BASE_URL + "/threads");
post.setHeader("Authorization", "Bearer " + apiKey);
post.setHeader("OpenAI-Beta", "assistants=v2");
String json = client.execute(post, stringResponseHandler);
return new AgentThread(JsonParser.parseString(json).getAsJsonObject().get("id").getAsString());
}
catch (Throwable t) {
throw new AgentException(t);
}
}And yes, error handling is rather basic in the current implementation. Any error case will be thrown as AgentException (possibly with a cause indicating what caused it).
Now let’s look at the routine for the main message loop (i.e., the implementation of the flow chart above):
private String promptAgent(String threadId, String prompt) throws AgentException {
try {
postUserMessage(threadId, prompt);
String runId = runAssistant(threadId);
long startTime = System.currentTimeMillis();
JsonObject runStatus;
do {
if (System.currentTimeMillis() - startTime > timeoutMs) {
throw new TimeoutException("Timed out waiting for run to complete");
}
Thread.sleep(1500);
runStatus = getRunStatus(threadId, runId);
if ("requires_action".equals(runStatus.get("status").getAsString())) {
JsonArray toolCalls = runStatus.getAsJsonObject("required_action")
.getAsJsonObject("submit_tool_outputs")
.getAsJsonArray("tool_calls");
JsonArray toolOutputs = new JsonArray();
for (JsonElement toolCallElem : toolCalls) {
JsonObject toolCall = toolCallElem.getAsJsonObject();
String functionName = toolCall.getAsJsonObject("function").get("name").getAsString();
JsonObject arguments = JsonParser
.parseString(toolCall.getAsJsonObject("function").get("arguments").getAsString())
.getAsJsonObject();
if (debug) {
System.out.println(" ... calling tool: " +
functionName + " - " +
toolCall.getAsJsonObject("function").get("arguments").getAsString()
.replace("\n", "").replace("\r", ""));
}
// This will be overwritten if a matching tool was found
Object toolResult = createUnknownToolReply(functionName);
// Use a reflection to find a method in the subclass that matches the tool name
// and that has the description annotation (which indicates that it was reported as a tool)
Method[] methods = this.getClass().getDeclaredMethods();
for (Method method : methods) {
try {
if (method.getName().equals(functionName) &&
method.isAnnotationPresent(description.class) &&
method.getReturnType() != void.class) {
Object[] params = Arrays.stream(method.getParameters())
.map(param -> GSON.fromJson(arguments.get(param.getName()), param.getType()))
.toArray();
method.setAccessible(true);
toolResult = method.invoke(this, params);
break;
}
}
catch (Throwable t) {
t.printStackTrace();
}
}
JsonObject output = new JsonObject();
output.addProperty("tool_call_id", toolCall.get("id").getAsString());
output.addProperty("output", GSON.toJson(toolResult));
toolOutputs.add(output);
}
submitToolOutputs(threadId, runId, toolOutputs);
}
} while (!"completed".equals(runStatus.get("status").getAsString()));
return getLastAssistantMessage(threadId);
}
catch (Throwable t) {
throw new AgentException(t);
}
}The helper methods, like getRunStatus() for example, look similar to createThread() — simple REST calls.
The full source code of the library (the AbstractAgent class and the description annotation) is in the GitHub repo. There you’ll also find the static registerAgent() method and all the helper methods.
Using the agent implementation in the MyAgent example earlier is as simple as this:
MyAgent agent = new MyAgent();
try (AbstractAgent.AgentThread thread = agent.createThread()) {
System.out.println(thread.promptAgent("What is 5 times 7?"));
}You can also do a loop where you prompt with follow-up questions in the same thread (as we’ll see in the Stack Overflow example below).
The Stack Overflow Agent
With our small Java library in place, we can start to work on our Stack Overflow agent. The first thing we want is our Neo4j connection and an implementation of the Cypher queries we need. In the GraphRAG version shown in the beginning, we used vector search to find the candidate posts, then traversed the posts and comments from them.
Here, we’ll give a vector search option as a first entry for the agent to find the relevant posts, but then we’ll provide it with some different ways to traverse from there (getting the threads, the comments, traverse over users, find accepted answers, etc.). Below, you see part of the class (the first three fetchers); you can find the full implementation on GitHub.
package org.bergman.agentic.demo;
import java.util.Collection;
import java.util.Map;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Config;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.Query;
import org.neo4j.driver.SessionConfig;
public class Neo4jConnection implements AutoCloseable, OpenAIConnection {
private static final String DB_URI = "neo4j+s://********.databases.neo4j.io";
private static final String DB_USER = "neo4j";
private static final String DB_PWD = "***********";
private static final String DB_NAME = "neo4j";
private final Driver driver;
public Neo4jConnection() {
driver = GraphDatabase.driver(DB_URI, AuthTokens.basic(DB_USER, DB_PWD), Config.defaultConfig());
}
@Override
public void close() throws Exception {
driver.close();
}
public Collection<Map<String, Object>> getRelevantQuestions(String userQuestion) {
var query = new Query(
"""
WITH genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('post_embeddings', 2, embedding) YIELD node AS p, score AS pscore
MATCH (p)((:Post)-[:PARENT]->(:Post))*(parent)
WITH embedding, collect(parent) AS parents
CALL db.index.vector.queryNodes('title_embeddings', 2, embedding) YIELD node AS q, score AS qscore
WITH parents, collect(q) AS posts
UNWIND parents+posts AS question
RETURN DISTINCT question {.score, .title, .body, id: elementId(question), created: toString(question.created)}
""",
Map.of("question", userQuestion, "apiKey", API_KEY));
try (var session = driver.session(SessionConfig.forDatabase(DB_NAME))) {
var record = session.executeRead(tx -> tx.run(query).list());
return record.stream().map(r -> r.get("question").asMap()).toList();
}
}
public Collection<Map<String, Object>> getThread(String questionId) {
var query = new Query(
"""
MATCH (q:Post) WHERE elementId(q) = $question
MATCH path = (q)((:Post)<-[:PARENT]-(:Post))*
UNWIND nodes(path) AS post
RETURN post {.score, .body, .postType, id: elementId(post), created: toString(post.created)}
""",
Map.of("question", questionId));
try (var session = driver.session(SessionConfig.forDatabase(DB_NAME))) {
var record = session.executeRead(tx -> tx.run(query).list());
return record.stream().map(r -> r.get("post").asMap()).toList();
}
}
public Map<String, Object> getAcceptedAnswer(String questionId) {
var query = new Query(
"""
MATCH (q:Post) WHERE elementId(q) = $question
OPTIONAL MATCH (q)-[:ACCEPTED_ANSWER]->(post:Post)
RETURN post {.score, .body, .postType, id: elementId(post), created: toString(post.created)}
""",
Map.of("question", questionId));
try (var session = driver.session(SessionConfig.forDatabase(DB_NAME))) {
var record = session.executeRead(tx -> tx.run(query).single());
return record.get("post").isNull() ? null : record.get("post").asMap();
}
}
...
}Note how all those methods return Maps and Lists of maps. The reason is that all our agent tool methods returns an Object, which will be converted to a JSON structure with GSON.toJson(toolResult), and maps fits well with JSON. Also note how the Cypher queries never return the nodes as they are; they use map projection to select what properties to return and in what format. This is to avoid properties we don’t want (like the vectors, which are 6 KB each) and to convert them to formats accepted by GSON (e.g., String instead of LocalDateTime).
Now we can do our agent implementation, using those Neo4j routines:
package org.bergman.agentic.demo;
import java.util.Scanner;
import org.bergman.agentic.openai.description;
import org.bergman.agentic.openai.AbstractAgent;
@description(
"""
You are assisting a development team with questions on their specific development environment.
For this you have a graph which is an export from Stack Overflow for teams. It has posts and comments on those posts.
The original post is usually a question, and the other posts are answers on that question.
All posts and comments has a link to the user that posted them.
""")
public class SOChatAgent extends AbstractAgent implements OpenAIConnection {
private static final String ASSISTANT_ID = "asst_***********";
private static final long TIMEOUT_MS = 60000;
private static final boolean DEBUG = true;
private final Neo4jConnection neo4j;
protected SOChatAgent(Neo4jConnection neo4j) {
super(API_KEY, ASSISTANT_ID, TIMEOUT_MS, DEBUG);
this.neo4j = neo4j;
}
@description(
"""
Find relevant questions (topics) in the graph based on vector search on the question the user asked (the prompt)
""")
public Object findRelevantQuestions(
@description("The question as asked by the user") String userQuestion
) throws Exception {
return neo4j.getRelevantQuestions(userQuestion);
}
@description(
"""
For a specific question (topic), get all posts in that thread (the question itself and all answers).
The result is unsorted, but there is a created field with when it was posted.
""")
public Object retrieveThread(
@description("The id of the question/topic to get the thread for") String questionId
) throws Exception {
return neo4j.getThread(questionId);
}
@description(
"""
For a specific question (topic), get the answer that has been indicated as the accepted answer
(if there is one, otherwise it returns a string that says 'No accepted answer')
""")
public Object retrieveAcceptedAnswer(
@description("The id of the question/topic to get the accepted answer for") String questionId
) throws Exception {
var result = neo4j.getAcceptedAnswer(questionId);
if (result == null) {
return "No accepted answer";
}
return result;
}
@description(
"""
Fetch all comments for a specific post (question or answer).
This may be an empty list if there are no comments.
""")
public Object retrieveComments(
@description("The id of the post to get the comments for") String postId
) throws Exception {
return neo4j.getComments(postId);
}
@description(
"""
Get the user that posted a question, an answer or a comment.
""")
public Object getUser(
@description("The id of the post (question or answer) or comment for which to get the user who posted.") String entityId
) throws Exception {
return neo4j.getUser(entityId);
}
@description(
"""
Get all posts (questions and answers) posted by a specific user.
""")
public Object getUserPosts(
@description("The user id to get the posted posts for.") String userId
) throws Exception {
return neo4j.getUserPosts(userId);
}
@description(
"""
Get all comments posted by a specific user.
""")
public Object getUserComments(
@description("The user id to get the posted comments for.") String userId
) throws Exception {
return neo4j.getUserComments(userId);
}
@description(
"""
Get the post that an answer or a comment was posted on.
If there is no parent (i.e. the post was a question) it return the string 'No parent'
""")
public Object getParentPost(
@description("The id of the post (answer) or comment") String entityId
) throws Exception {
var result = neo4j.getParentPost(entityId);
if (result == null) {
return "No parent";
}
return result;
}
}The interface OpenAIConnection just has the API_KEY constant — that’s all it is.
Finally, we can do our prompt loop where we ask the user to provide questions until they write “exit” to stop the loop:
public static void main(String[] args) throws Exception {
try(Neo4jConnection neo4j = new Neo4jConnection()) {
SOChatAgent agent = new SOChatAgent(neo4j);
try(Scanner scanner = new Scanner(System.in);
AbstractAgent.AgentThread thread = agent.createThread()) {
while (true) {
String input = scanner.nextLine();
if (input.trim().equalsIgnoreCase("exit")) {
break;
}
System.out.println(thread.promptAgent(input));
}
}
}
}All the demo code is on GitHub.
Testing
Now let’s try our new chatbot (with debug enabled to see what tools it requests):
> I am getting started with Aura development on Windows. What are the three most important things for me to do?
... calling tool: findRelevantQuestions - {"userQuestion":"getting started with Aura development on Windows"}
... calling tool: retrieveAcceptedAnswer - {"questionId": "4:1ad7b1b4-413f-49bd-aa14-24a8f5f75f28:405"}
... calling tool: retrieveAcceptedAnswer - {"questionId": "4:1ad7b1b4-413f-49bd-aa14-24a8f5f75f28:659"}
... calling tool: retrieveAcceptedAnswer - {"questionId": "4:1ad7b1b4-413f-49bd-aa14-24a8f5f75f28:256"}
- Install WSL, Docker
- Configure SSH Keys
- Install Visual Studio Code
> Are there any pitfalls reported in the threads on any of those steps?
... calling tool: retrieveComments - {"postId": "4:1ad7b1b4-413f-49bd-aa14-24a8f5f75f28:406"}
... calling tool: retrieveComments - {"postId": "4:1ad7b1b4-413f-49bd-aa14-24a8f5f75f28:660"}
No reported pitfalls in the threads.
> exit
Thread deleted: thread_UwrncnmVUSplDhaO5YNU64q9That’s it! We now have our very own agent to help us get started developing as an Aura engineer.
Final Words
It should be noted that the library presented here should be seen as a way to demonstrate how agentic AI works, not as a production-grade library. There are several things that should be done to make it production-ready:
- Better error handling (instead of the single AgentException).
- Create a map of method handles instead of doing the reflection on every call.
- Use DTO and Java Records for the tool results. As I wrote earlier, there’s no contract with the agent regarding the return type of the tools, but at least in our code, we would make it cleaner and with a clearer contract for each tool.
- More annotations for more tailoring of the tools
- Testing
- Testing
- Testing
But instead of doing all of that, I would probably go for Rod Johnson’s library instead.
Agentic AI with Java and Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

GraphRAG and Agentic Architecture: Practical Experimentation with Neo4j and NeoConverse
