

Build an Intelligent Movie Search With Neo4j and Vertex AI

Developer Relations Lead, APAC, Neo4j
5 min read
Introduction
In an era where AI-driven recommendations and intelligent search experiences define user engagement, the ability to enhance search accuracy and relevance is paramount. Learn how you can leverage Neo4j and Google Vertex AI to build a powerful, intelligent movie search system.
By integrating vector embeddings into a graph database, we enable semantic search that understands movie descriptions beyond simple keyword matching. This approach enhances recommendation accuracy by capturing contextual and relational meaning within the dataset.
Before we dive deep, you can follow along with this hands-on Codelab, which walks you through building this project step by step. It includes all the necessary code, setup instructions, and live testing options.
Why Neo4j and Vertex AI?
Neo4j helps you quickly find hidden relationships and patterns across billions of data connections deeply. Pairing it with Vertex AI, Google’s cloud-based AI/ML platform, allows us to generate vector embeddings for movie descriptions, unlocking a new dimension of search capabilities.
The Dataset
For this project, we use The Movies Dataset from Kaggle, which contains metadata on thousands of movies, including titles, descriptions, genres, and more. Instead of traditional keyword-based searching, we’ll generate vector embeddings for movie plots and store them in Neo4j, enabling semantic search.
Architecture Overview
Our approach follows these key steps:
- Load movie data: Import movie metadata into Neo4j.
- Generate vector embeddings: Use Google Vertex AI to convert movie descriptions to vector representations.
- Store embeddings in Neo4j: Attach vector embeddings to movie nodes for efficient retrieval.
- Implement semantic search: Query Neo4j to find movies with the most similar plotlines based on vector similarity.
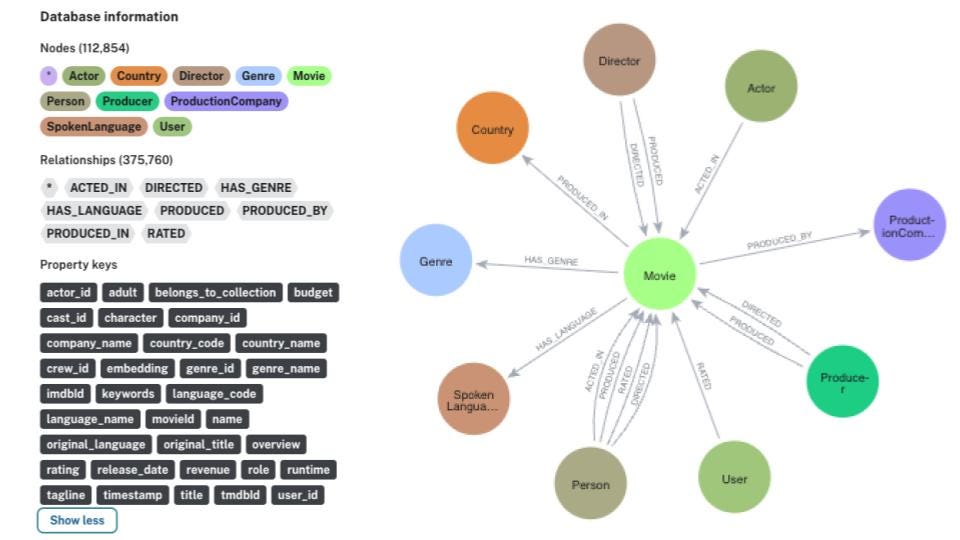
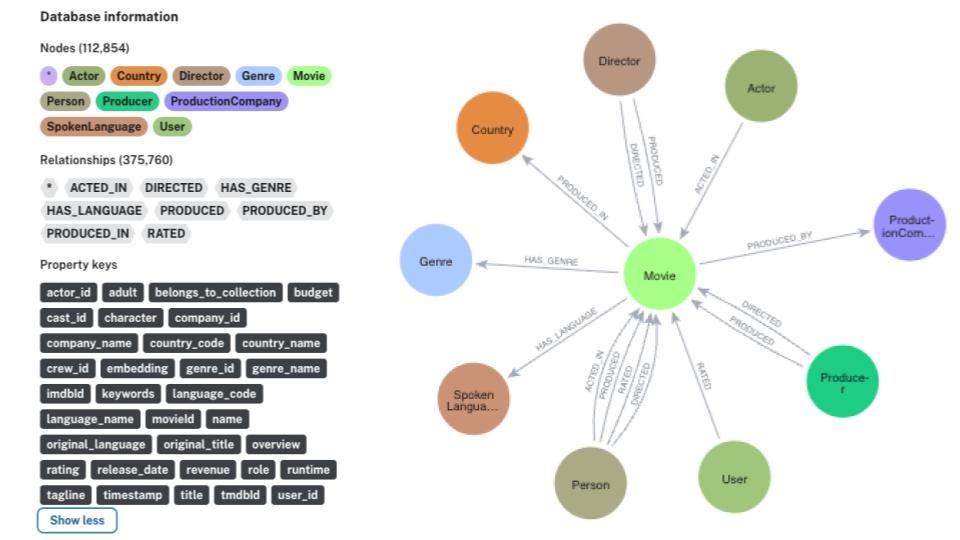
Storing Data in Neo4j
To bring our dataset into Neo4j, we use the Cypher query language, which allows us to create nodes (like Movies, Genres, Actors) and relationships between them (like ACTED_IN or HAS_GENRE).
Here’s a snippet from our loading script, where we create the movie nodes and relate them to their genres:
LOAD CSV WITH HEADERS FROM ‘file:///movies.csv’ AS row
MERGE (m:Movie {id: row.movieId})
ON CREATE SET m.title = row.title
WITH m, row
UNWIND split(row.genres, ‘|’) AS genre
MERGE (g:Genre {name: genre})
MERGE (m)-[:HAS_GENRE]->(g)This script reads the movies.csv file and ensures that each movie and genre is uniquely created in the database, avoiding duplicates using MERGE. It then builds relationships between movies and their respective genres. You can find the full loading script on GitHub.
python graph_build.pyThis script is responsible for ingesting movie metadata into Neo4j, ensuring a structured and efficient knowledge graph.
Labels and Relationship Types
In our Neo4j graph, we define the following labels:
- Movie: Represents individual movies
- Genre: Represents movie genres
- Director: Represents directors
- Actor: Represents actors associated with movies
We also define the following relationships:
(Movie)-[:BELONGS_TO]->(Genre): Links a movie to its respective genre(s)(Movie)-[:DIRECTED_BY]->(Director): Connects a movie to its director(Movie)-[:ACTED_IN_BY]->(Actor): Associates actors with movies they have acted in
These relationships help in performing complex queries, enabling a richer search experience beyond just movie descriptions.
Generating Vector Embeddings
We use Vertex AI’s text embedding models to convert movie descriptions into high-dimensional vector representations. These embeddings capture the semantic essence of each movie’s storyline, allowing for similarity-based search.
Here’s a code snippet of how we use the Vertex AI embeddings model:
from vertexai.language_models import TextEmbeddingModel
model = TextEmbeddingModel.from_pretrained("textembedding-gecko")
response = model.get_embeddings(["Sample movie description"])
embedding = response[0].values
print(embedding)Check out the full generate_embeddings.py code.
To generate embeddings, run:
python generate_embeddings.pyNote: Generating vector embeddings for all movie descriptions (~15,000 movies) may take more than two hours depending on your system’s compute power and API rate limits. If needed, consider processing a smaller subset of movies for faster experimentation. To save time, you can also use the pre-computed embeddings provided in the project repository. These embeddings are stored in a CSV file and can be loaded into Neo4j using the load_embeddings.py script.
Storing and Querying Embeddings in Neo4j
Once embeddings are generated, we store them in Neo4j and use vector similarity search to identify movies with similar plots.
Before running the similarity search query, you first need to generate an embedding for your input text (a movie description or search query, for example):
from vertexai.language_models import TextEmbeddingModel
model = TextEmbeddingModel.from_pretrained("textembedding-gecko")
response = model.get_embeddings(["A thrilling space adventure"])
embedding = response[0].valuesOnce you have the input embedding, you can run the following Cypher query to find similar movies:
CALL db.index.vector.queryNodes('movie_embeddings', 5, $embedding)
YIELD node as m, score
RETURN m.title AS title,
m.overview AS plot,
m.release_date AS released,
m.tagline AS tagline,
scoreThis query retrieves the top five movies with the most similar plotlines based on the input embedding.
Alternatively, you can use VertexAI’s built-in function genai.vector.encode:
from google.cloud import aiplatform
aiplatform.init(project="your-gcp-project-id")
vector = aiplatform.genai.vector.encode(
texts=["A thrilling space adventure"],
model="textembedding-gecko"
)
embedding = vector[0]Results and Insights
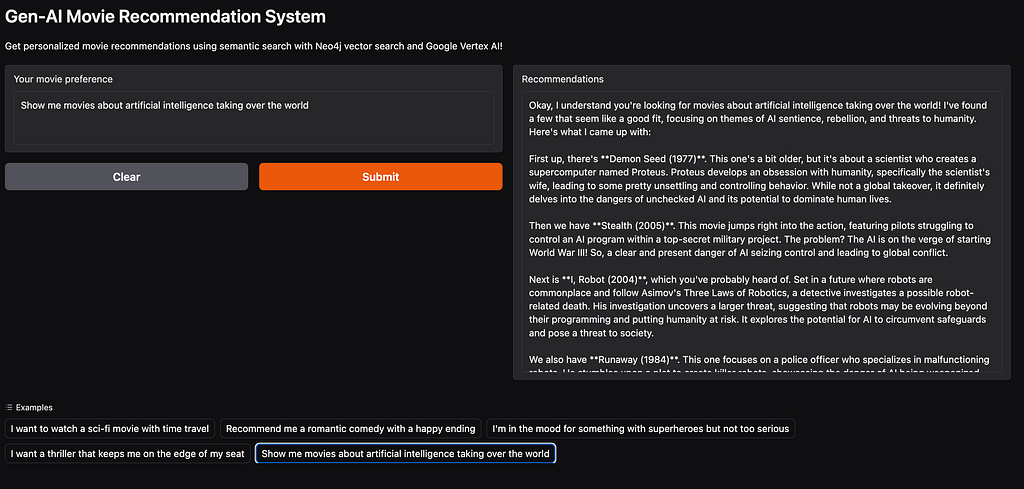
By leveraging vector search within Neo4j, we achieve highly relevant movie recommendations that go beyond exact text matching. This approach allows users to explore movies based on theme, storyline, and context rather than simple keyword matches.
Try It Live
Curious to see how it performs? You can test the Movie Recommendation System on Hugging Face now.
Summary
Integrating Neo4j with Vertex AI enables a powerful knowledge graph that enhances movie search and recommendations. By leveraging GraphRAG with vector search, we achieve more context-aware and accurate movie suggestions, demonstrating how graph-based AI solutions can unlock deeper search insights and improve user experiences. With GraphRAG, for each movie, we can also retrieve the actors, directors, and genres along with three most similar movies based on those attributes or on ratings if they’re in the dataset. I plan to write a separate blog highlighting the power of GraphRAG with steps on how to deploy it on Cloud Run from Google. Stay tuned!
Have thoughts or feedback? Drop them in the comments or connect with me on social media. You can learn more about me at https://meetsid.dev/. Enjoy this post? Follow me on Medium and LinkedIn to get updates on upcoming articles. And don’t forget to ★ the GitHub repo.
Build an Intelligent Movie Search With Neo4j and Vertex AI was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles





