LLM Knowledge Graph Builder Back-End Architecture and API Overview
Engineering Lead, Persistent Systems
11 min read
Introduction
We’re surrounded by data — documents, emails, social posts — but making sense of it all? That’s the real challenge. Sifting through the noise to find meaningful connections has always been a headache.
Enter the Neo4j LLM Knowledge Graph Builder. This tool combines the power of large language models (LLMs) with graph databases to turn messy, unstructured data into clear, connected knowledge graphs. Just upload your files — PDFs, web pages, whatever — and it builds a knowledge graph you can explore, query, or even chat with using GraphRAG. It’s like giving your data a brain. Get a quick overview of the process and learn more.
This post is part of our ongoing series covering various aspects of the Neo4j LLM Knowledge Graph Builder:
- Overall functionality
- Knowledge graph extraction
- Front-end architecture and integration
- Back-end architecture and API overview (current)
- Graph visualization
- GraphRAG retrievers
In this post, we delve into the back-end architecture, providing a comprehensive overview of API design and implementation.
Architecture Overview
The back end is built on Python with the FastAPI framework, featuring integration with LangChain for GenAI and document loaders (e.g., YouTube Loader, GCSFileLoader, UnstructuredLoader, PyMuPDFLoader). This API offers a scalable, efficient solution for loading, processing, and interacting with documents across different sources to extract content and generate graphs. This open source project is available on GitHub (LLMGraphBuilder). Check out the back-end API specification document.
Back-End Architecture
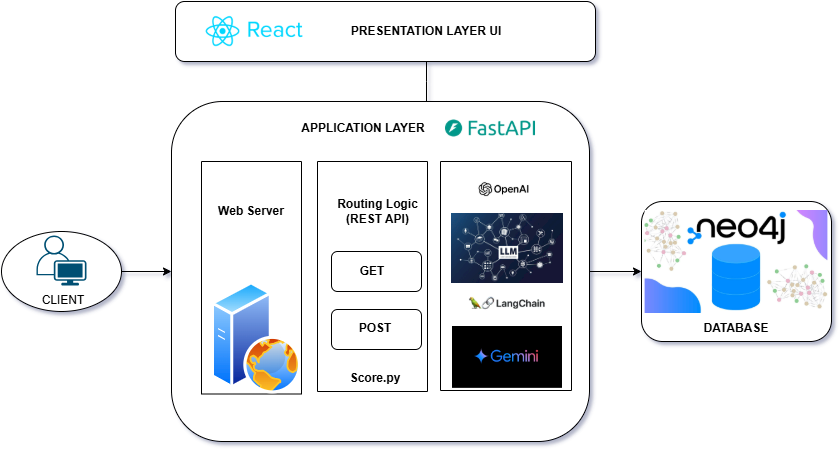
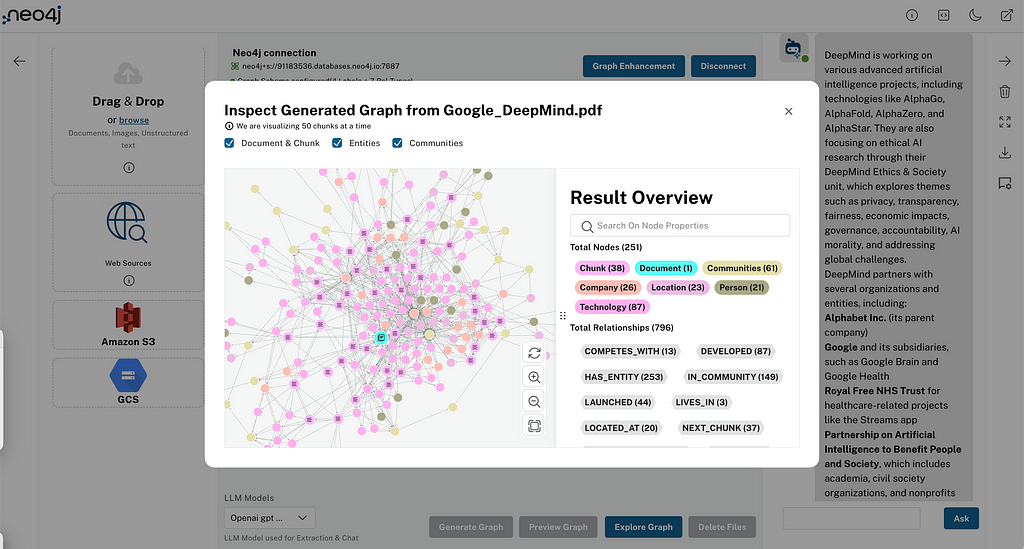
Purpose of the API
The primary goal of these APIs is to fetch content from various document sources and process them using LangChain’s LLM Graph Transformer to extract entities and relationships in the form of graph documents to store in a Neo4j database for an AI-driven conversational interface powered by GraphRAG retrievers. This solution is particularly suitable for scenarios like information retrieval and content summarization.
Architecture Details
The back end leverages FastAPI for routing and request handling, ensuring fast response times and easy scalability. The following components/library are key to the system:
- LangChain integration: Handles interactions with GenAI, enabling natural language responses based on the loaded documents.
- Document loaders: Allow ingestion of data from various sources, including:
– Google Cloud Storage (GCS) File Loader: Reads documents from GCS with support for various file types (e.g., PDF, Word, text)
– PyMuPDFLoader: For data extraction of PDF documents
– UnstructuredFileLoader: Loads and extracts file data of many types; currently supports loading text files, PowerPoint, HTML, PDFs, images, etc.
– YouTube Loader: Converts YouTube videos into transcriptions, making them searchable and retrievable through LangChain
– WikipediaLoader: Loads wiki pages from wikipedia.org into document format
– S3 Directory Loader: Loads the document object from an S3 Directory object
– WebBaseLoader: Loads text from HTML web pages into document format - Embedding: Vector embeddings measure the relatedness of text content. Providing them can help with tasks like text analysis and similarity comparisons. For example, words like “cat” and “kitty” have similar meanings, and vector embeddings can capture this semantic similarity. We support three types of embeddings in the application:
– SentenceTransformerEmbedding: Uses Hugging Face embedding model with LangChain. Model “all-MiniLM-L6-v2” maps text to 384-dimensional dense vector space.
– OpenAI Embeddings: Model “text-embedding-ada-002” maps text to 1536-dimensional dense vector space.
– Vertex AI Embedding: Model “textembedding-gecko@003” maps text to 768–dimensional dense vector space. - Neo4jGraph: This LangChain utility handles connections to the Neo4j database to retrieve and store graph data, provide graph schema, and interact with different index types.
- Neo4jVector: Allows for the creation of a retriever that uses a vector index stored in Neo4j. This retriever can be configured to search for documents based on similarity scores, with options to filter by specific document names and set score thresholds. The vector search is then augmented with a GraphRAG retrieval query to fetch additional contextual information from the knowledge graph, starting with the documents in the vector index.
API Design Principles
- Modularity: The LangChain framework allows the APIs to adapt to various LLM models, data loaders, and retrieval mechanisms for the chatbot with minimal configuration.
- Scalability: FastAPI provides asynchronous support for scaling to handle multiple document uploads and queries simultaneously.
- Data validation: Leverage Pydantic models to validate request and response data.
- HTTP status code: Return appropriate HTTP status codes to indicate success, errors or redirects.
- Statelessness: The back end is not meant to keep or handle user state; that’s all managed by the front end. Connection details and user context are passed with every request, enabling seamless scaling. In GCP Cloud Run, this is enforced by design — instances are ephemeral and can scale automatically, so any persistent state must be stored externally (e.g., Cloud Storage, Firestore).
- Open API and documentation: FastAPI automatically generates Swagger and Redoc documentation at:
– /docs (Swagger UI)
– /redoc (Redoc UI)
API Example Walkthrough
Connect API to the Neo4j database:
curl -X 'POST'
'https://dev-backend-967196130891.us-central1.run.app/connect'
-H 'accept: application/json'
-H 'Content-Type: application/x-www-form-urlencoded'
-d 'uri=neo4j%2Ds%3A%2F%2Fdemo.neo4jlabs.com&userName=test&password=token&database=test1&email=abc%40gmail.com'Response:
{
"status": "Success",
"data": {
"db_vector_dimension": 384,
"application_dimension": 384,
"message": "Connection Successful",
"gds_status": true,
"write_access": true,
"elapsed_api_time": "1.41",
"gcs_file_cache": "True"
}
}API Endpoints in Detail
Provide structured access to each functionality, with endpoints for uploading documents, extracting content, saving to the database, querying chatbot content, and retrieving processed data.
We categorize all APIs into five categories:
- Infrastructure
- Document processing
- Visualization
- Graph enhancements
- Chat experience
Here’s a detailed specification for each of the key API endpoints:
Infrastructure
/connect (Infrastructure)
Authenticates and connects the front end to the back end using Neo4j database credentials. Based on the response from this API, the front-end UI displays the connection status and the database type icon, such as Graph Data Science or AuraDB. Additionally, it checks and returns the response regarding the existing vector dimensions in the database and the application-supported vector dimensions. If the vector dimensions in the existing database differ, an alert is displayed in the connection modal pop-up.

/backend_connection_configuration (Infrastructure)
Creates the connection object for the Neo4j database based on the back-end environment configuration and returns the status to show/hide login dialog in the UI (i.e., no need to pass credentials via login pop-up if env-configured).
/drop_and_create_vector_index (Infrastructure)
Drops and creates the vector index when the existing vector index dimensions are different from the required ones.
/schema (Infrastructure)
Gets the labels and relationships from existing Neo4j database data. Users can set the schema for graph generation (i.e., nodes and relationship labels) in the settings panel.
/delete_document_and_entities (Infrastructure)
Deletes nodes and relationships for multiple files. Users can choose multiple documents to delete and can opt to delete only document and chunk nodes, keeping the entities extracted from that document.
Document Processing
/upload (Document Processing)
Handles the uploading of large files by breaking them into smaller chunks. This method ensures that large files can be uploaded efficiently without overloading the server.
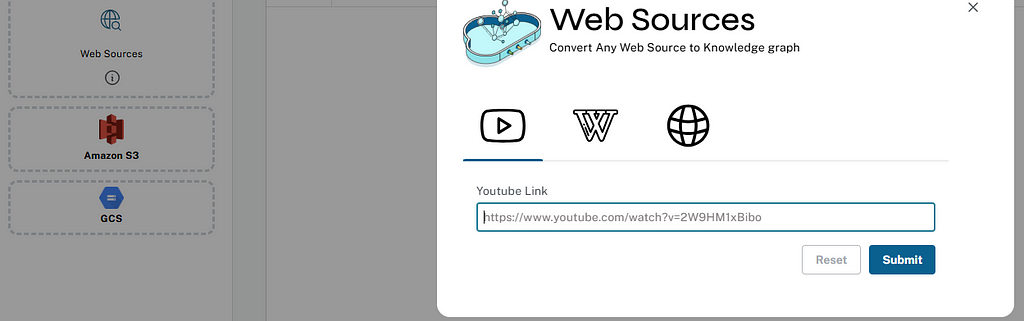
/url/scan (Document Processing)
Creates document source nodes for all supported sources, including S3 buckets, GCS buckets, Wikipedia, web pages, YouTube videos, and local files. Supported sources of content:
- S3 bucket — User passes the bucket URL and all the PDF files inside folders; subfolders will be listed.
- GCS bucket — User passes GCS project ID, GCS bucket, and folder name, then authenticates to access all the PDFs under that folder and its subfolders. If the folder name is not passed by the user, all the PDFs under the bucket and its subfolders will be listed if the user has bucket read access.
- Wikipedia — The text content from the URL is processed; the URL is passed by the user.
- Web URLs — Text content from any web URL is processed
- YouTube video transcriptions — Processes text transcripts from YouTube videos.
/extract (Document Processing)
Extracts nodes and relationships from previously uploaded sources content. Steps of this functionality:
- Read the content of source provided in the form of LangChain document object from respective LangChain loaders.
- Divide the document into multiple chunks and create the relationships:
–PART_OF— From document node to all chunk nodes
–FIRST_CHUNK— From document node to first chunk node
–NEXT_CHUNK— From a chunk pointing to the next chunk of the document
–HAS_ENTITY— Between chunk nodes and entities extracted from LLM - Compute and store chunk embeddings and create vector index.
- Extract nodes and relationships in the form of a graph document from the respective LLM using LangChain LLM Graph Transformer.
The library is used to get nodes and relationships in the form of graph documents from LLMs. User and system prompts, LLM chain, and graph document schema are defined in the library itself. - Delete uploaded files from GCS after extraction or in case of failure, copy to another GCS bucket for further investigation.
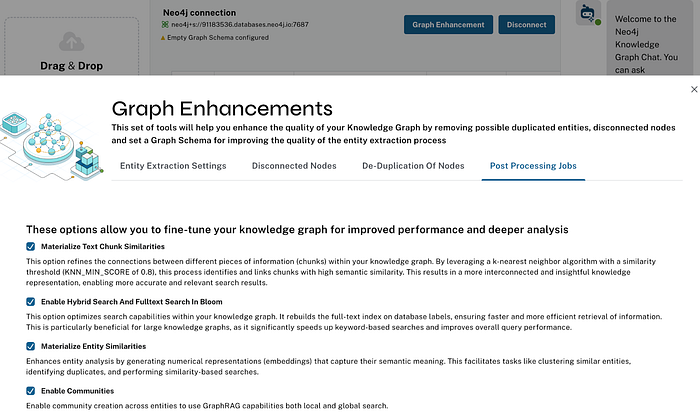
- Post-processing to refine graph structure, enabling advanced search functionalities and integrating community detection for enhanced insights. The post-processing API integrates various tasks, ensuring that the knowledge graph is enriched, optimized, and ready for downstream applications.

/chunk entities (Document Processing)
Gets the entities and relationships associated with a particular chunk and chunk metadata based on retrieval mode (i.e., vector and vector + full text).
/sources_list (Document Processing)
Gets the list of all sources (document nodes) in the Neo4j graph database.
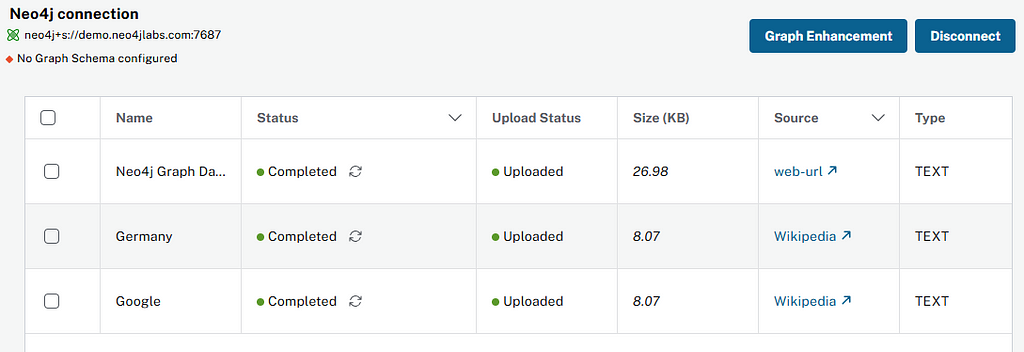
/post_processing (Document Processing)
At the end of all document processing, creates k-nearest neighbor relationships between similar chunks of documents based on KNN_MIN_SCORE, which is 0.8 by default, computes hierarchical community clusters, generates community summaries with the LLM, and recreates a full-text index on all labels in the database so that the retrievers, Neo4j Bloom and other downstream applications can make use of it.
The following tasks are carried out as part of post-processing:
- Materialize text chunk similarities
- Enable hybrid search and full-text search in Neo4j Bloom
- Materialize entity similarities
- Enable communities
- Graph schema consolidation
Get more information about post-processing tasks.
/update_extract_status (Document Processing)
Provides a continuous update on the extraction status of a specified file. It uses server-sent events to stream updates to the client.
/canceled_job (Document Processing)
Cancels the processing job.
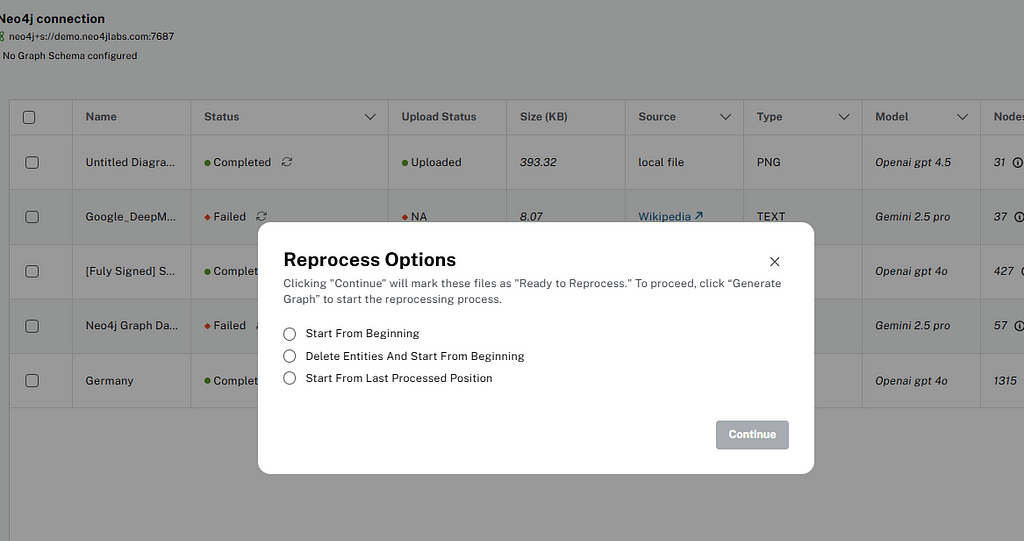
/retry_processing (Document Processing)
Reprocesses canceled, completed or failed file sources. Users have three options for reprocessing files:
- Start from beginning — File will be processed from the beginning (i.e., first chunk again).
- Delete entities and start from beginning — If the file source is already processed and has any existing nodes and relationships, those will be deleted and the file will be reprocessed from the first chunk.
- Start from the last processed position — Canceled or failed files will be processed from the last successfully processed chunk position. This option is not available for completed files.
Once the status is set to Reprocess, users can again click on Generate Graph to process the file for knowledge graph creation.
The Developer’s Guide to GraphRAG
Combine a knowledge graph with RAG to build a contextual, explainable GenAI app. Get started by learning the three main patterns.
Graph Visualization
/get_neighbours (Visualization)
Gets the nearby nodes and relationships based on the element ID of the node for graph visualization of details of specific nodes. It’s used in detail views of chatbot results, post-processing tables, and elsewhere.
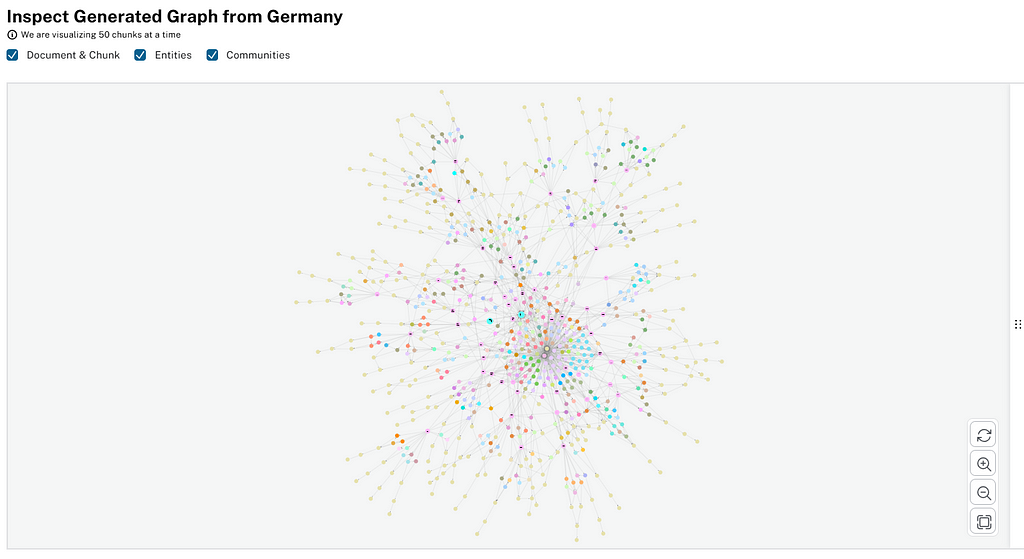
/graph_query (Visualization)
Visualizes graphs for a particular document or list of multiple documents. It will return documents, chunks, entities, relationships, and communities to the front end to portray in a graph visualization.
Graph Enhancements
/populate_graph_schema (Graph Enhancements)
Populates a graph schema based on the provided input text, model, and schema description flag. You can use an LLM to provide suggestions for node labels and relationship types, treating the provided text as a (more or less formal) schema description or as actual prose text from which entity types should be inferred.
/get_unconnected_nodes_list (Graph Enhancements)
Retrieves a list of nodes in the graph database that aren’t connected to any other entity nodes — only to chunks from which they were extracted.
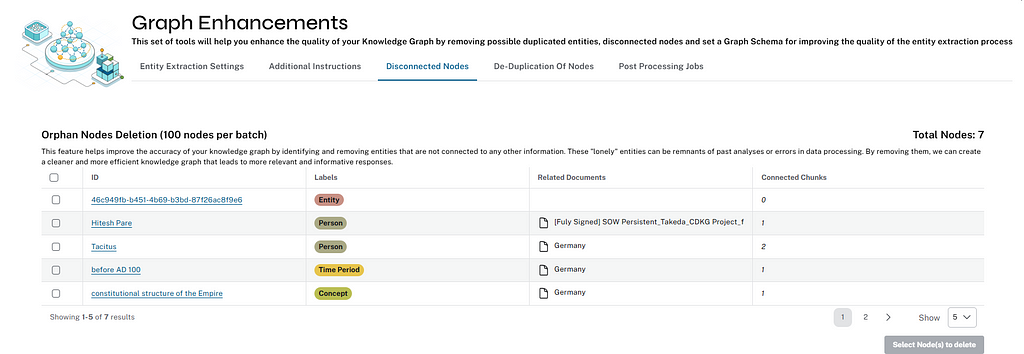
/delete_unconnected_nodes (Graph Enhancements)
Deletes unconnected entities from the Neo4j database with the input provided from the user.
/get_duplicate_nodes_list (Graph Enhancements)
Fetches duplicate entities from the Neo4j database. It uses a Cypher query that matches nodes with embeddings and IDs, excluding certain labels (e.g., chunk, session, document).
The query determines duplicates based on various conditions, including cosine similarity of embeddings exceeding a defined threshold (DUPLICATE_SCORE_VALUE), text substring containment, or a text edit distance below a certain limit (DUPLICATE_TEXT_DISTANCE).
The method ensures that duplicate subsets are removed by comparing nodes within the same group. The method executes the query and returns a list of duplicate nodes, along with the total count of duplicates.
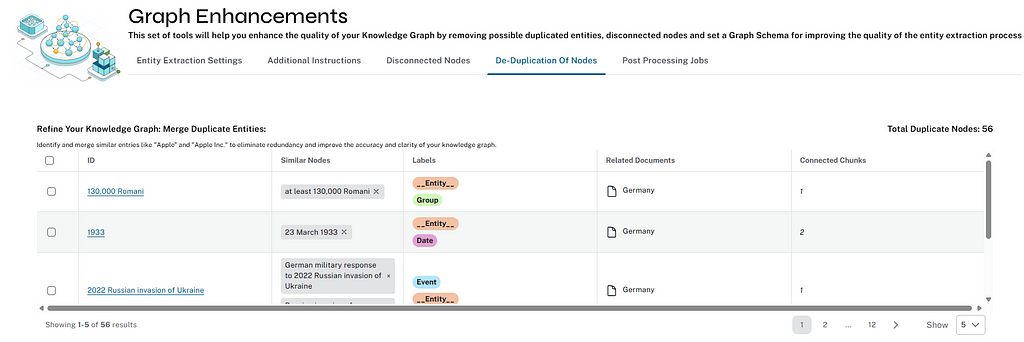
/merge_duplicate_nodes (Graph Enhancements)
Merges duplicate entities in the Neo4j database selected by the user. Relationships are transferred to the resulting entity.
Chat Experience
/chat_bot (Chat Experience)
Responsible for a chatbot system designed to leverage multiple AI models and a Neo4j graph database, providing answers to user queries.
It interacts with AI models from OpenAI, Google’s Vertex AI, etc. and uses embedding models to enhance the retrieval of relevant information.
It uses different retrievers (see Retrieval Detail) to extract relevant information from the user query and uses LLM to formulate the answer. If no relevant information is found, the chatbot gracefully conveys that to the user.

/clear_chat_bot (Chat Experience)
Clears the chat history saved in the Neo4j database.
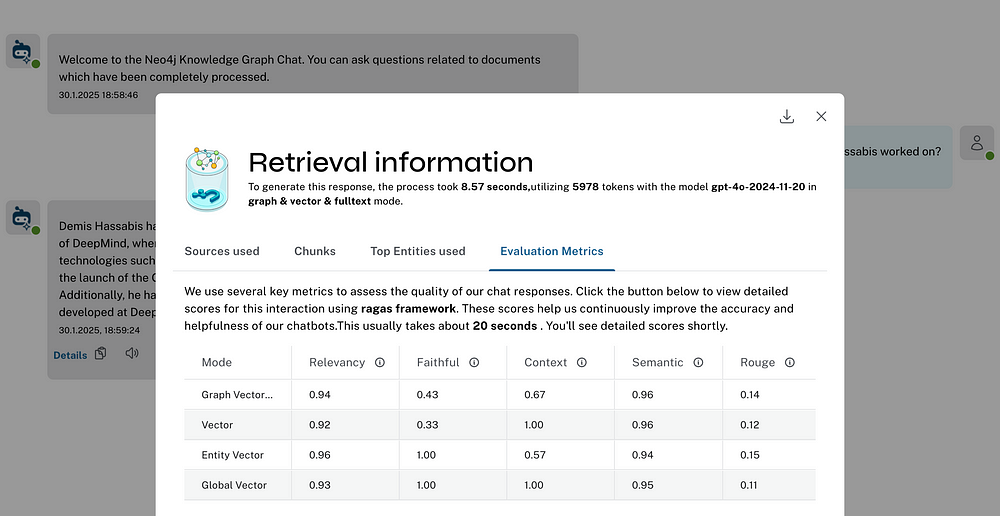
/metric (Chat Experience)
Evaluates the chatbot response for the different retrievers based on metrics like faithfulness and answer relevancy. This uses the Ragas library to calculate these metrics.

/additional_metrics (Chat Experience)
Evaluates chatbot responses based on metrics like context entity recall, semantic score, rouge score. This require additional ground truth to be supplied by the user. This uses the Ragas library to calculate these metrics.
/fetch_chunktext (Chat Experience)
Fetches text associated with a particular chunk and chunk metadata.
Summary
The back-end architecture, built on Python with the FastAPI framework, demonstrates a robust and scalable approach for integrating GenAI capabilities and managing diverse document sources.
With LangChain’s LLM Graph Transformer and a suite of document loaders, the system effectively processes content from various inputs, extracting entities and relationships to generate meaningful graph documents stored in the Neo4j database.
By leveraging vector embeddings for semantic analysis and incorporating Neo4jGraph and Neo4jVector utilities, the solution ensures efficient data retrieval and contextual understanding, enhancing use cases like information retrieval and content summarization.
This comprehensive and modular design makes the back end a versatile foundation for AI-driven conversational interfaces and advanced data interactions.
Stay tuned for the next post in this series, where we’ll dive deeper into graph visualization techniques and GraphRAG retrievers in the LLM Knowledge Graph Builder.
We welcome your thoughts and feedback. Drop a comment or raise an issue on GitHub to share your insights!
LLM Knowledge Graph Builder Back-End Architecture and API Overview was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
The Developer’s Guide to GraphRAG
Combine a knowledge graph with RAG to build a contextual, explainable GenAI app. Get started by learning the three main patterns.
Share Article



Explore
Related Articles