

Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements

Machine Learning Engineer, Neo4j
5 min read

The Text2Cypher task aims to translate natural language questions into Cypher queries. In late 2024, we shared our Neo4j Text2Cypher (2024) Dataset and took a deep dive into how baseline and fine-tuned models performed. We wanted to further understand where these models struggle the most and how we can make the dataset even better.
We analyzed the evaluation results from various angles to better understand how our models are performing:
- First, we looked at the overall performance — analyzing test-set results, tracking how key evaluation metrics varied across different instances, running statistical analyses (like averages and standard deviations), and assigning complexity levels to get a clearer picture of model challenges.
- Then we broke things down further by examining performance across different factors. We compared results based on data source (e.g., neo4jLabs/synthetic/gemini), database type (e.g., neo4jLabs/movies), and specific fine-tuned models. For each model, we analyzed key evaluation metrics, average scores, and complexity levels to better understand what impacts performance.
- Finally, we dug into common mistakes to pinpoint where models struggle the most. Did issues in the dataset cause the errors? Did the evaluation metrics influence results? Or were there deeper challenges with how the models processed the data?
By identifying these patterns, we’re finding new ways to improve our dataset and models. We’ll apply the key learnings to update our models and better support developers. Let’s dive into the details.
Exploring Key Evaluation Metrics
For our analysis of the evaluation results, we used the test set and the data from earlier experiments with both baseline and fine-tuned models.
In our previous blog posts, we focused on Google BLEU and ExactMatch scores, but we actually calculated results using several other evaluation metrics. These additional metrics gave us valuable insights into per-instance performance, which we’ll explore here. The metrics we used include BERTScore, FrugalScore, Sentence (Cosine) Similarity, and Jaro-Winkler. We’ll dive into them here.
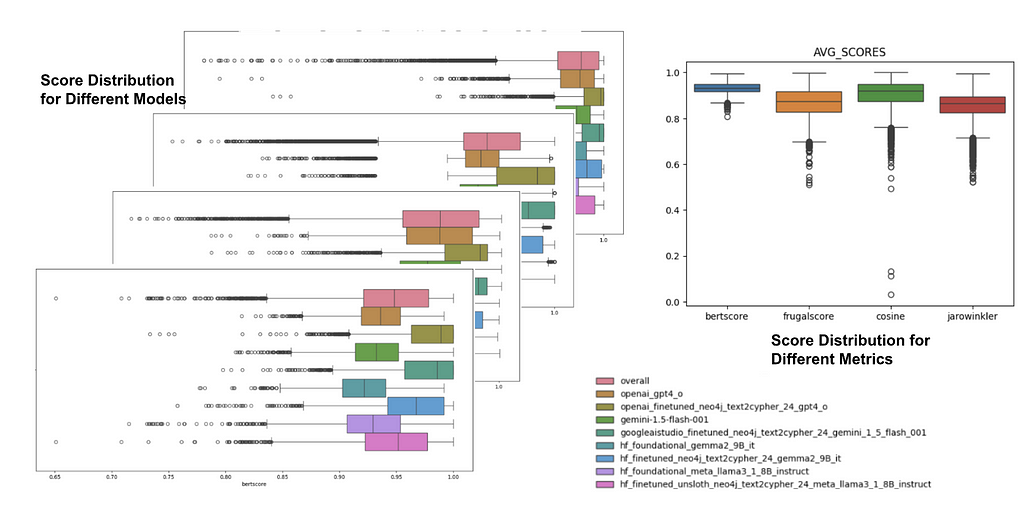
When we checked the score distribution for different models, we noticed a lot of outliers — instances where the models really struggled. Exploring more, we found that outliers appeared in all the evaluation metrics.
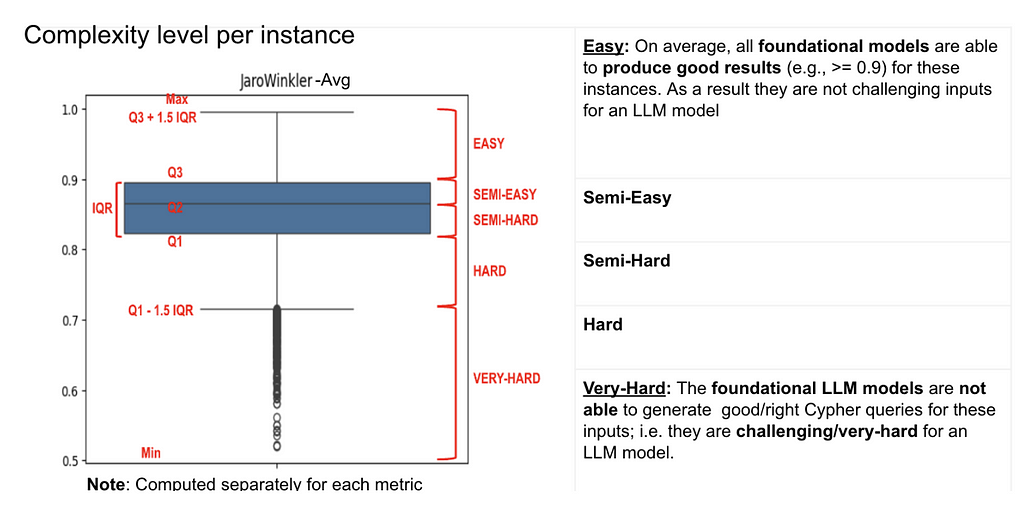
To get a better sense of the difficulty level, we assigned complexity levels to these instances based on the score distribution. We kept it simple, using the quantiles to categorize the instances. The “easy” instances are those where all the foundational models can easily generate good Cypher queries. On the other hand, the “challenging” ones are difficult for the foundational models. These levels are later used for the analysis of the model outputs.

We also took a closer look at the data sources and databases. For the data sources, we found that the models struggled most with neo4jLabs/functional, neo4jLabs/gemini, and neo4jLabs/gpt4o — all synthetic datasets. For the databases, the models struggled the most with recommendations, companies, and neoflix. These are the data sources and databases we’ll examine and analyze in the future.
Insights From Fine-Tuned Models
Here, we examine three fine-tuned models in more detail and explore where they face the most challenges. To start, we plot the distribution of metrics for each instance, comparing the baseline and fine-tuned versions of the models.
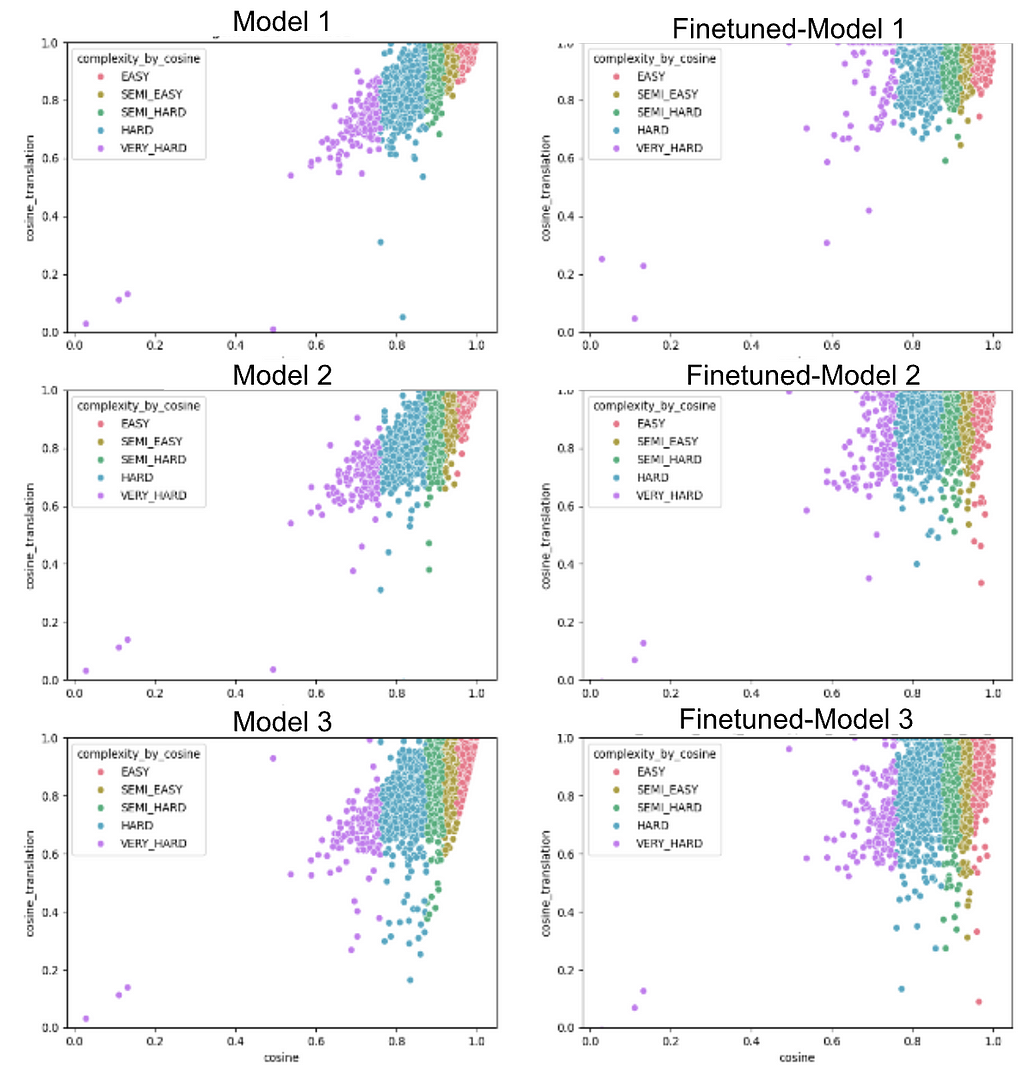
The plot reveals a linear relationship between the average evaluation score (on the x-axis) and model performance (on the y-axis). It also shows that fine-tuning improves the model’s performance: Scores move closer to the top, and the density in the higher range of the plot increases.

Next, we manually checked a set of instances by comparing the ground-truth and generated outputs. Since it’s not practical to check every instance across all models, we used a few heuristics-based steps to decide which ones to focus on:
- We calculated an average score per instance using the foundational models.
- We selected which instances to review by comparing their average scores with those of the target models.
- We narrowed it down by complexity level, focusing only on Easy and Very-Hard instances for our checks.
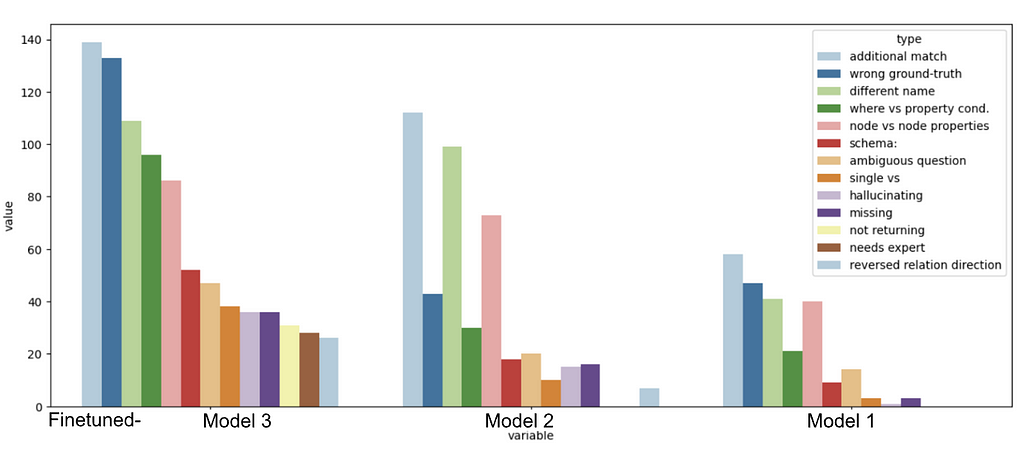
After completing the manual checks, we identified various errors made by the models. We identified common patterns by grouping these errors and running some statistical analysis. The plot above shows these errors, giving us insights into where the models struggle the most.

Common Error Groups
Here are the top five common mistake groups we found:
- Additional [Matches, Fields, …]
- Wrong ground truth
- Naming mismatches
- Confusion between WHERE and property conditions
- Node vs. node properties
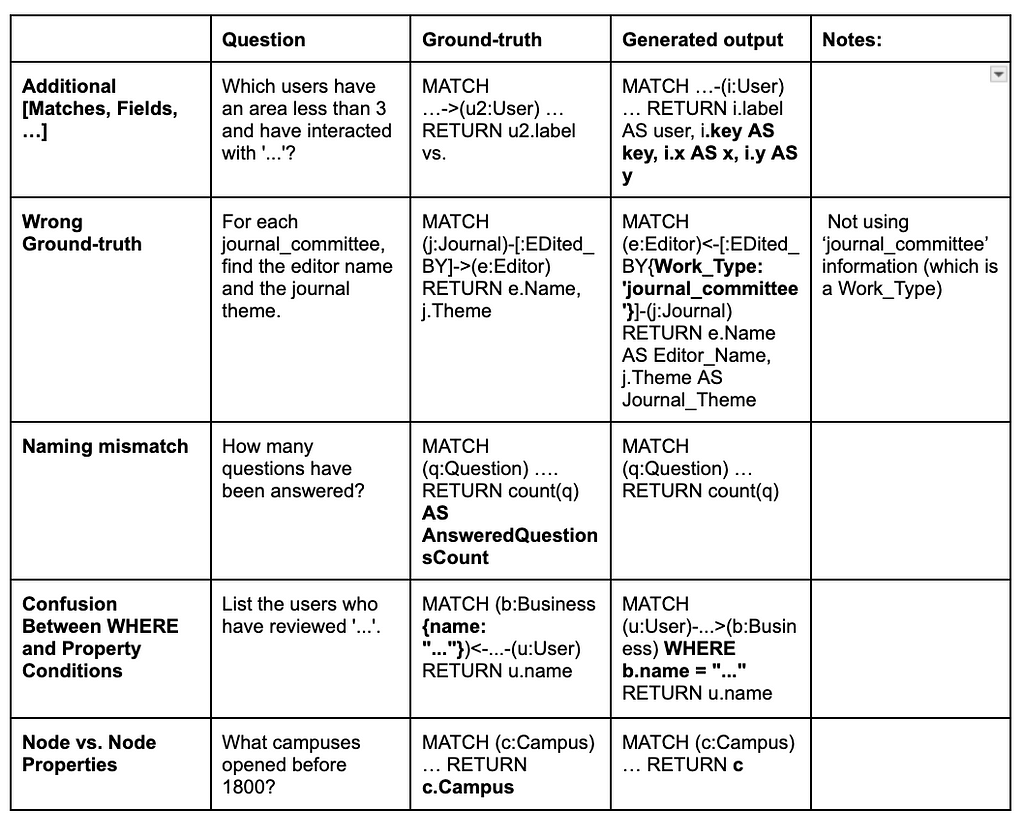
These are the areas where the models tend to make the most frequent errors, and they offer clear starting points for improvement.
Surprising Errors We Encountered
We also came across some surprising and unexpected errors during our analysis.

Here are a few examples:
- Ambiguous questions: For instance, asking for top-k results without specifying the field to rank by.
- Schema issues: Some questions could be answered through different relationships in the database, causing confusion.
- Cypher-specific challenges: For example, using the MAX function versus using ORDER BY and returning the top element.

These errors highlighted some tricky spots where the models struggle to interpret the queries correctly.
Summary and Next Steps
In this analysis, we’ve found key areas where our models struggle, mainly with the quality of ground-truth data and evaluation metrics. For example, inconsistencies in comparing Cypher queries with different clauses (e.g., WHERE vs. property conditions) or choosing between aggregation methods like MAX vs. ORDER BY can impact evaluation results. These insights will guide us in improving the dataset, refining the models, and enhancing the evaluation process in future updates.
Next, we plan to dive deeper into the dataset to find more challenges and improve its quality. We’ll further clean the data using new tools or human annotators. On the evaluation front, while we’ve already implemented both translation-based and execution-based methods alongside various metrics, we see opportunities for improvement. One promising direction is incorporating parse trees into our evaluation process, and we look forward to exploring this further.
We’ll continue working to make our models and dataset even better, so stay tuned for more updates!
For more information about Text2Cypher, check out Introducing the Fine-Tuned Neo4j Text2Cypher (2024) Model and Benchmarking Using the Neo4j Text2Cypher (2024) Dataset.
Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Build a Private Network Path to Aura on AWS, Azure, and Google Cloud Using Terraform



