The eBay App for Google Assistant: Graph-Powered Conversational Commerce


4 min read

Editor’s Note: This presentation was given by Ajinkya Kale and Anuj Vatsa at GraphConnect New York in October 2017.
Presentation Summary
The eBay App for Google Assistant is a chatbot powered by knowledge graphs that supports conversational commerce. In creating the system, the eBay team wondered how they could determine the next question that the chatbot should ask the user.
Natural Language Understanding (NLU) is used to break down queries into their component parts. Learning from one type of query can be captured and transferred to other contexts to further enrich the knowledge graph. They believe that graphs are the future for AI. For eBay, Neo4j is more than a database; it also powers machine learning on the knowledge graph.
eBay uses a Dockerized system on top of Google Cloud Platform to deploy it. eBay originally ran two services in one container: a monolithic Scala service and Neo4j. The team decided to migrate to microservices, adhering to Docker best practices.
One challenge was the size of the data model. By leveraging an alpha feature of Kubernetes called StatefulSet, eBay was able to scale the app to support increased traffic in one locale (eBay U.S.) as well as rolling it out to additional locales (eBay Australia).
Full Presentation: The eBay App for Google Assistant: Graph-Powered Conversational Commerce
What we’re going to be talking about today is our use of Neo4j as a backend to the AI technology in eBay’s virtual shopping assistant:
Ajinkya Kale: I lead the research efforts on knowledge graphs in the New Product Development group at eBay. We focus on cutting-edge technology and also on the artificial intelligence side of eBay efforts.
At eBay, we have around 160 million active buyers and about $11 billion in mobile sales:

We have more than a billion live listings. There’s a misconception that eBay is all about used items, but 81% of the items that are sold on eBay are actually new. And we have almost 13 million listings added through mobile every week.
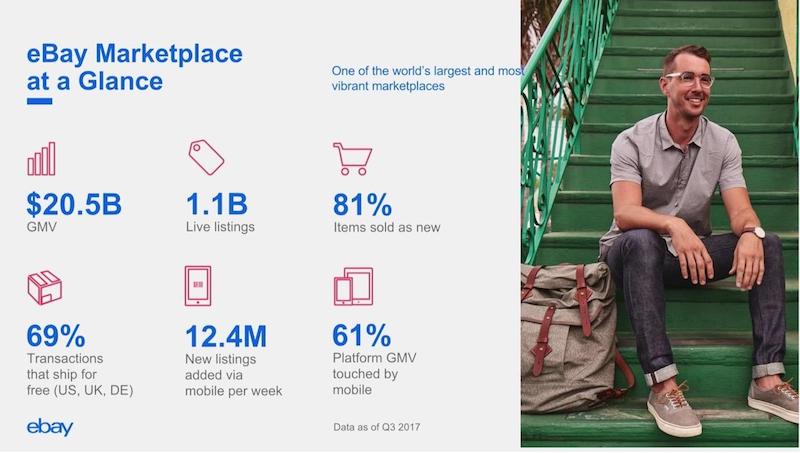
Every country, every site, has its own priorities. In the UK, there’s a makeup product sold every three seconds. Australia has a wedding item purchased every 26 seconds.

The eBay App for Google Assistant
The eBay App for Google Assistant is a chatbot powered by knowledge graphs. The app is a personal shopping assistant. We built it as a shopping assistant initially within the Facebook Messenger platform, but now it is only available with Google Assistant (the Facebook Messenger ShopBot has been shut down).

We created the app to bridge the gap between regular search and natural language search. If you enter a query like, “I want a gift for an 11-year-old who likes Iron Man,” most other search engines will fail. It’s a really hard problem to go from a regular search engine to a search engine which powers natural language.
The eBay App for Google Assistant supports natural language understanding (NLU).
What Is Conversational Commerce?
Conversational commerce is basically a system where you interact with the agent as you would interact with a salesperson in a shop.

If you go to a shop to buy some sneakers, you say, “I’m looking for some shoes,” the salesperson might ask you, “Okay, what are you going to use them for?” And once you tell him what you’re going to use them for, then he might ask you what brand you prefer, then maybe what color you prefer, and what size shoes you wear.
This kind of multi-turn interactivity is really hard to accomplish in a regular search engine.
Figuring Out the Next Question to Ask
In creating the system, we had to ask ourselves, “How do we determine the next best question to ask when a user is trying to search for an item on the platform?” There are a lot of bot frameworks – like Api.ai, wit.ai, and others – but they’re all based on rules engines. You input a rule and the system will start acting the way you’ve input the rules. It’s almost like a bunch of “if-then-else” statements.
eBay offers almost everything under the sun. We have more than 20,000 product categories and more than 150,000 attributes such as brand, the color of the object, and any other attribute about an object that you’re trying to buy. You really cannot use a rules engine to support a huge catalog like eBay, with more than a billion items in inventory.

We needed a solution that would scale and where we could encode this inherent human brain behavior where when I talk to someone about shoes, the next thing he’ll think about is Nike or Adidas as a brand. For humans, it’s very easy to think about it in that form. It comes inherently with the knowledge that we have been building since childhood.
Rather than just encoding rules, we decided it was more like a probabilistic inference problem where given a particular intent that the user is looking for, you decide based on some probability the next best question to ask.

eBay has around 16 million active buyers. Almost every product that could be searched for has been searched for, and almost every attribute that could be used has been used.
We went from eBay’s core user behavior data to form a probabilistic graph so that we can drive conversation on what questions to ask next. And this is where you would see a graph database being used.
There’s a nice paper by Peter Norvig that talks about how data is the key, even in the deep-learning or machine-learning era. You can have amazing algorithms, but without data you cannot do much about it.
The biggest challenge we had was that, although there is a lot of academic research and papers talking about how natural language generation can be driven through machine learning or deep learning, none of them really have productionalized an actual conversational system based on deep learning.

We ended up building an expert system based on a collaborative approach where you use past user behavior data and apply it to the next user in a probabilistic way.

Using Natural Language Understanding to Break Down Queries
This diagram shows the natural language understanding system that we have built:

Right now you can go to Google Assitance and try the eBay app using queries like this. We take a query like this one:
“My husband needs some new black leather dress shoes, but I want to spend less than $80. What do you have?”
We break the query into multiple components to get a deeper understanding of the user intent. We detected the gender from the query. You cannot just use the gender for the actual shopper; you have to look at the gender in the query. In this case, a female is searching for her husband, so we’ve detected that the gender is male.
The intent here is needs, which means it’s a shopping intent. And then there is item condition; and on eBay, you can buy used items as well as new, and she is clearly looking for a new item. Black leather dress shoes are attributes of the product she’s trying to look for. And there are also some constraints like price, which we have to apply when we filter out the inventory we have.
Here is a simplified example of the graph underneath:
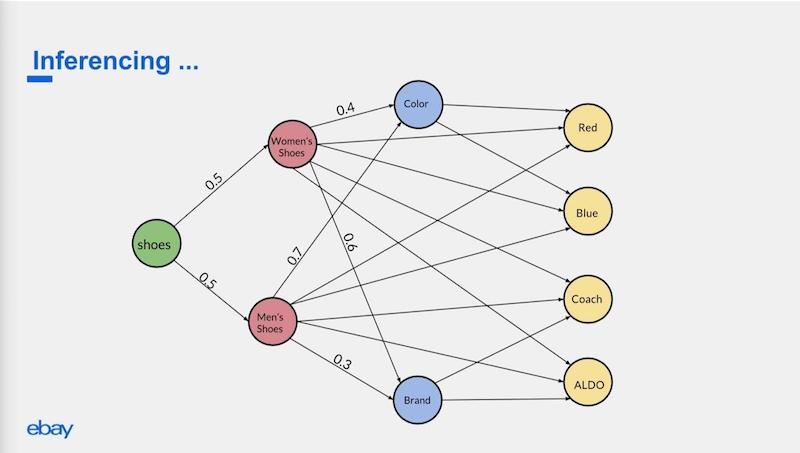
If the query is about shoes, we first data-mine what gender is the user looking for.
Women’s shoes have different attributes that should be asked about next compared to men’s shoes. Perhaps women care more about brand than men do. Men may care more about color (which is almost always brown).
Based on those probabilities, we decide how to infer this and basically convert it into a Markov chain where you only need the current context to ask the next question.
Transferring Learning
NLU handles the natural language understanding for the query and then we have a piece that does the ecommerce understanding:

If you say something like, “I’m looking for eggplant Foamposites,” I would have no idea what you are talking about. But because we have so much past user behavior data, there has to be someone who’s an expert in sneakers who must have clicked on the right item.
We know from that item’s attributes that when someone says, “Eggplant Foamposite,” the product should be in the athletic shoes category, the product brand is Nike, they’re mostly used as basketball shoes, we know what the product release date was, the color is mostly purple and the material is Foamposite.
But there is another really nice and unique thing about this process. From this query, you determine from the graph that eggplant corresponds to purple. The cool thing about this is that you can apply it in cases where you do not have much past user behavior data.
So if someone says, “I’m looking for an eggplant iPhone case,” most of the time the person is not looking for pictures of eggplants on the case. He or she is looking for a purple case.
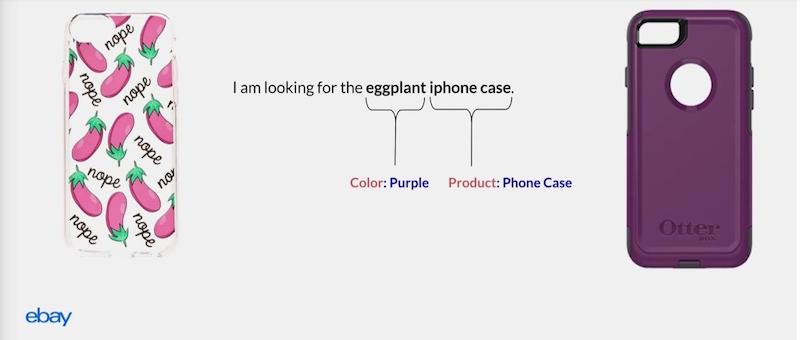
From the previous query, where we learned that Nike has tagged all these eggplant Foamposites with the color purple, we associated or learned through our knowledge graph that eggplant is associated with purple, and now we can use it in a situation where we absolutely don’t know about what someone means when they say, “Eggplant iPhone case.”
That type of transfer is very good and is possible only because of the probabilistic knowledge graph that we built.
Architecture Overview of eBay ShopKnowledge
This is an overview of the system architecture:

We have a huge set of data, which includes ecommerce data, as well as world knowledge data, which comes from Wikipedia, Wikidata, and other data sources such as Freebase and DBpedia.
We combine this data using the Apache Airflow scheduler to get the data into a knowledge graph form through Google Cloud and Spark. The data is then eventually modeled as a graph and pushed to Neo4j.
More Than a Database
For us, technically, the graph is not just a database, as it is for most of the users of a graph database. It’s not for BI or analytics either. For us, it’s a store that is used as a cache for a machine-learning knowledge graph.
Once the data goes to the knowledge graph database system, we do graph inferencing on it to power query understanding, entity extraction, price prediction and determination of trends.
In the previous example, we looked at how inferencing works. Once we have the data into the graph structure, we use a Dockerized system on top of Google Cloud Platform to deploy it. The deployment structure and the services will be explained later in this blog.
This is a high level summary of what we have in our current knowledge graph:

We have around half a billion nodes, and now about 20 billion relationships. We have combined ecommerce data with Wikidata to power more world knowledge, such as when the product was released and what other trends people are following. Things keep changing, so you have to add more knowledge into your knowledge graph.
There are also some machine learning aspects. As I mentioned, we don’t use the graph just as our database, but also to store the probabilistic graphical model and use it as a cache for the runtime system.
We have implemented some supervised models on top of it. For example, if you are talking about winter jackets, you don’t want sports jackets because eBay has a winter jacket category. You want to actually make the categorization to get attributes from the winter jacket category. Those are supervised models that also live in the graph.
We use some semi-supervised approaches to label propagation. We have a whole team that curates the graph for trends. Because we have such a huge graph, they cannot curate each of the nodes in the graph and mark the trends. They model a subset of the graph with trends, and then we use label propagation to spread it through the entire graph.
Use Case: What Is It Worth?
One cool use case that we have recently served on Google Assistant, and which you can try, is What Is It Worth? You can say, “I want to talk to eBay,” and then you can either try to find out how much an item that you have is worth or you can check the price for the latest products that are going to be launched.
You can say, “What is the iPhone 8 going to cost?” Or you can say that “I have this old backpack that’s lying around. It’s this particular model. It’s this particular color. What can I get for it?” That’s also served through our knowledge graph.
Neo4j: The End of Data JOINs
Why Neo4j?
When we started we did try some relational datasets, but we soon found out that the more datasets we had, the JOINs kept growing. We said, “Let’s just forget about all these JOINs now. Let’s put everything in a graph. For any new dataset, our pipelines go from anywhere from a week to two weeks to just add a new dataset.” So we never have to worry about JOINing ever again.
Obviously, Neo4j is battle-tested. It has good production support and the tooling system is also good. We could very easily do a lot of experimentation because of the interactive browser and the visualizations that they have. And it’s the only solution that provides graph algorithms on top of a graph database.

Graphs Are the Future for AI
I agree with Emil that graph technology is the future of artificial intellingence.
I had a lot of search experience before I joined the AI team at eBay. What I found is that a search system usually needs an autocomplete system, a query recommendation system and an item recommendation system. All of that can be powered through a graph.
You can think of it as your machine learning model cache, and some other system can do your backend indexing. All your business logic and the creative juices can live in the graph where you actually do the inferencing. And you can push only the part where you have to pull items to the backend indexing store.

Containerizing Neo4j
Anuj Vatsa: Now let’s focus on how we evolved with Neo4j over the last year and a half and share some key takeaways about how we containerized the Neo4j database and how we deployed huge data models into Google Cloud using Kubernetes.
As a part of the New Products Development team, we were doing a lot of prototyping and that’s how we started using Neo4j, because it fits our case very well. And one of the main aspects of this was also deploying to the cloud.

Our tech stack includes Docker. We use Kubernetes and we have polyglot services in the backend. We have some services written in Scala, some in Java and some in Go, so we wanted to make sure that everything works out of the box.

Why Docker and Kubernetes?
So why did we decide to use Docker? Docker gave us a very easy way to build, ship, and run applications through lightweight containers in the cloud. We use Kubernetes because Kubernetes is the best orchestration layer out there which would allow us to scale in or scale out our containers depending on the traffic volume.
In the early days, because we were prototyping, we were using a huge monolithic Python service and we had lots of different modules running as a single Python service. We had a huge Python code base and one of them was the knowledge graph module.

When you think of this from a containers perspective, we had two processes: the Python service and the graph database. Initially, our models were pretty small, so at one point the graph database was actually a localhost to the system.
The problem with the huge Python service was, as many of you might have encountered, we ran into the global interpreter lock issues. That meant we could only serve a couple of requests per second, so we were spawning more pods to serve more users.
We went back and thought we should actually split all the services into individual microservices:
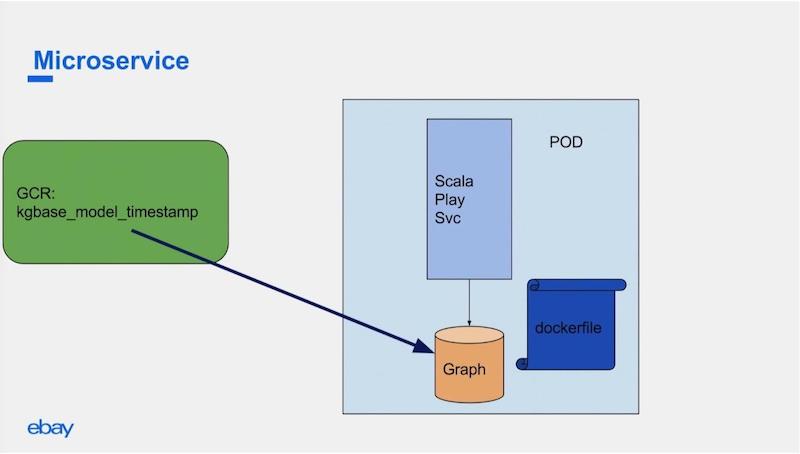
Once the data science team built the graph models, we used to bake the graph models as base Docker images. We used to put them in the Google Cloud repository, which you can think of as a GitHub for Docker images.
In our service deployments, we used to have this Docker file refer to the current base image that was supposed to be deployed. It used to download the data and spawn the graph database and then we wrote a Scala service on top of the database to serve our APIs and all other use cases.
In this way, graph was still a localhost to the system and we had two processes running: the Scala service and the graph database.
This limited us in a couple of ways. First, if our models grew huge, their deployment would become a bottleneck. Second, pushing and downloading these models was taking a lot of time. We wanted a solution that would work in all these cases.
In this version of the graph, we were still using Cypher queries and we saw some latencies at the rate of a couple of seconds. When we switched over to procedures, we brought down our latencies to less than a hundred milliseconds. Switching to procedures was an improvement of 25x over the baseline.
Following Docker Principles
One of the Docker principles says that you should never run multiple processes within a single container, and that is what we were doing.
We were running a Scala service and Neo4j as a process within our container. We wanted to get away from that. The other issue arose when we need to do a pod restart. We used to go back and download the model and then restart the pod so that would also become a bottleneck (see list of limitations below).

Handling Multi-Terabyte Models
In the meantime, we had requirements coming up where our models were on the order of multiple terabytes. At the same time, we were thinking of launching in different locales.
The first version of the eBay App for Google Assistant was only for the U.S., but now we also offer it for the Australian dataset.

One of our requirements was minimal deployment time. We also wanted the switch from the old dataset to the new dataset to be pretty seamless. The end user shouldn’t even know that we have switched over to new data.
That’s how we arrived at the containerized solution. We considered the fact that a lot of folks spawn their own VMs and load balance their services to herd the VMs. We could have done that too but that meant we would be taking away all the goodness from Kubernetes and we’re pushing all that load balancing and scaling of logic onto ourselves.
Even though spawning your own VMs was a tried and tested model, we went with containerizing the Neo4j graph database.
Most of the Kubernetes apps, by default, are stateless. That means they don’t have any storage and the way you provide storage for a Kubernetes app is through persistent volumes. If you want to use a persistent volume and make sure your pod doesn’t copy over the data each time, there is an alpha feature in Kubernetes called StatefulSet.
StatefulSet ensures that when you start a pod, the data that is associated with this pod is constant in all the rollouts. We will copy the data only the first time when we are doing the switch over for the data. If there was a pod restart or a hardware failure, on the consecutive next pod initialization, we wouldn’t have to copy over the data. That meant we were avoiding multiple duplicate copies.

Scaling with Kubernetes
Remember that we used to bake the models into these base Docker images. Instead of baking them into the Docker images, we started baking the models into Google Persistent Disks (PDs). During a deployment, that PD gets copied to the local PD. And this happens only the first time.
Then through a Kubernetes service definition, we could easily route the traffic from our Scala service to the pods, as shown below.
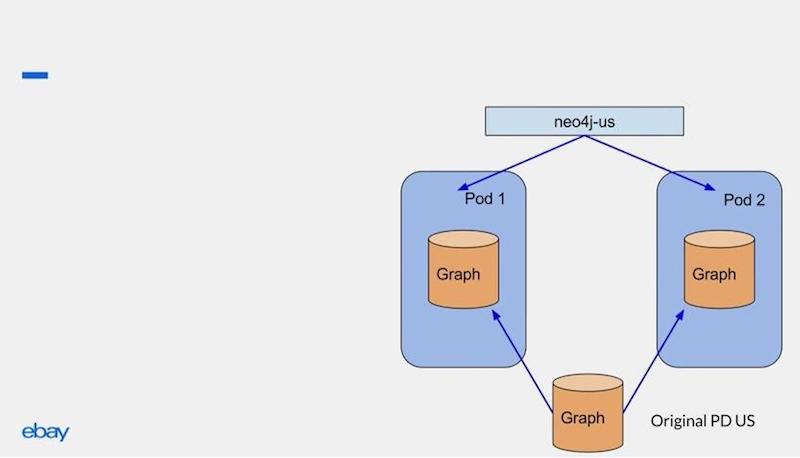
So in the example above, we have two pods, and the Kubernetes service definition knows when the pods are coming up, and it load balances and routes the traffic to each of the pods. If our traffic increases, all we have to do is change the deployment script from 2 to x number of pods, and Kubernetes takes care of scaling out.
The diagram above shows the Scala service talking to Neo4j US. One of the requirements was supporting also multiple locales. With this model, we were also able to work on getting the Scala service to route on different Kubernetes service definitions, depending on the locale. Each of those deployments are individual.

If the data science team comes up with new data, and we go through the whole process of creating a new original PD. When we do the switchover, StatefulSets does an ordered termination of pods and ordered initialization of pods.
That ensured if there is any data corruption or problem that we didn’t catch in testing, we can stop that particular pod and it will stop the rollout because StatefulSet ensures that Pod N is up before working on the next one.
We are still continuously evolving. This was pretty new and like I said, some of the things that we used were alpha features. We are still working with the Kubernetes team, and we’re working on ways we can improve.
One of the limitations of this method is that, when you create a pod for the first time, because it’s a multi-terabyte model, your init phase takes a lot of time. It takes us a few hours to get one of the pods up because of the data copy. Hopefully we can get to a stage where our deployment times are not in the magnitude of hours but in a couple of minutes.
Share Article



Explore
Related Articles
Integrating Neo4j With LangChain4j for GraphRAG Vector Stores and Retrievers



Transform Static Risk Assessment Into a Dynamic Data-Driven Strategy
LLM Knowledge Graph Builder Back-End Architecture and API Overview