



From the beginnings of the Neo4j graph database – released almost nine years ago in version 1.0 – up to the latest version (and also the developments of other manufacturers, though Neo4j has not lost its leading position in the market since then), the area of graph databases and graph-based systems has established itself as an independent technology sector that’s growing at an above-average rate.
Evidence for this evolution is also GQL (Graph Query Language) – a proposal for a future industry standard of a common graph query language, analogous to SQL. Standardization committees such as W3C or ISO are already discussing it.
The standardization of SQL helped relational databases to breakthrough and gain a broad adoption in the database sector. However, has been challenged due to competition in the NoSQL (“Not Only SQL”) market, fueled by massively increasing data volumes (big data). And graph technology in particular, as one of the fastest growing branches of the big data solution space, has played a major role in the tides turning to a standard graph query language.
There must be reasons for the current successful developments in the graph field. Considering that graph theory and graph models have been widely used for a long time (within and outside the IT world), the reasons must be found on the technological level.

In addition to the high maturity of the respective implementations, the property graph data model should be mentioned here, which stands out in its relative simplicity from more complex and more academic data models (such as UML or RDF). There are only nodes and edges and both can have attributes. This creates greater flexibility, because many existing graph-based concepts are easily mapped to the property graph model while remaining easy to understand for us humans.
The decision of some graph technology manufacturers to limit their products to this rather simple model, and to expand it only carefully, has proven to be well-considered. Users and developers had the freedom they needed to design and implement ideas with a still relatively new technology. It also enabled the database vendors to observe and learn from the sometimes very creative applications of their technology in the real world.
For example, the extension of the property graph model to include labels and the introduction of Cypher, a declarative query language for Neo4j, are good “lessons learned,” and what you can achieve if you foster good relationships with your community of users, customers and partners (and occasionally listen to them).
The Structr platform can also be seen as one of these creative solutions based on graph technology.
Structr uses a graph database as primary data storage in all areas and makes extensive use of its flexibility to implement functions, such as a data model modifiable at runtime and the new flow engine which allows visual programming. In addition to the benefits of the Neo4j graph platform, the positive characteristics of a graph application platform such as Structr add up and make it possible to implement any kind of application in a relatively short amount of time.
Use Cases: More Data, More Dynamics, More Intelligence
Initially, when the technology and products were new, there were assumptions as to in which areas and for which applications graph technology would be adapted.
Both Neo4j and Structr were initially developed for the use case of Content and Media Asset Management. It was a great surprise, for both manufacturers, that predictions about which industry or which use case was suitable for the use of graph databases and platforms, turned out to be wrong. However, they were wrong because apparently almost all areas in which software systems are used can benefit from graph technology.
This is also reflected in the following picture, which shows the development of graph technology use cases – from simple, rather static cases with small amounts of data to dynamic, intelligent systems with large amounts of data.
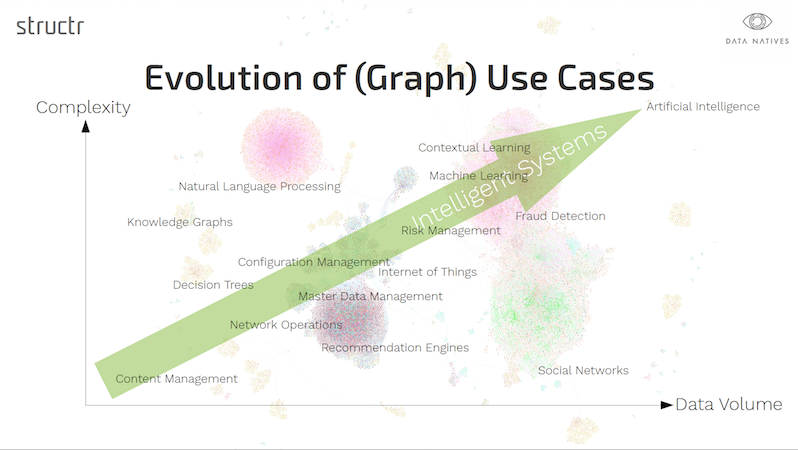
“Static” here means that the data changes relatively seldom. A typical example is Content Management, in which media content created once is stored and managed in a searchable way. The focus lies more on good organization and fast read access – a requirement profile that graph databases meet well from the beginning.
Over time, more and more dynamic use cases with frequently changing data, such as real-time transaction monitoring or social media applications, were added. Consequently, the technical solutions were honed over time for good write performance.
Many graph solutions initially introduced in isolated areas have proven their value and have gradually been extended by additional hierarchies or dimensions, while growing in complexity and data volume. An example is the historization of data as a temporal extension of data that only describes a single state.
The advantages of graphs over less flexible models is evident: Graphs can be extended in any direction without having to migrate existing structures. This brings even more benefits – on a medium and long-term time scale – as it further simplifies development and increases maintainability.
In addition, intelligent graph application cases – often characterized by the combined usage of static and dynamic information (or primary and metadata) to derive new correlations by smart graph processing and graph algorithms – have become increasingly common in recent times.
It is no coincidence that graph-based systems in particular are increasingly being used as the basis for NLP (natural language processing), ML (machine learning) and AI (artificial intelligence) systems. Most models in these disciplines are graphs. Not only are graphs similar to linguistic language models, taxonomies and ontologies, but they also resemble the structures of the real world, from neurons and body cells to elementary particles and their interactions.
In short, graphs are the most general and easiest-to-understand representations of the real world and are therefore best suited as data models and for persisting graph-like structures.
Graphs As the Basis for Intelligent Software
The fact that intelligent software is best developed with graph technology is also demonstrated by the development of Neo4j and Structr.
Only recently, Neo4j announced the completion of a further financing round (Series E Round) amounting to USD 80 million. With the additional investment volume, the acceptance of the graph platform is to be further expanded and Neo4j is equipped to keep up in the AI and ML environment.
The users and customers of Structr also benefit from this, because Structr helps with accessing Neo4’s benefits quickly and easily.
In version 3.0, we added a flow engine to the platform, which makes it possible to develop and run programs in a graphical flow editor. This is the basis for the development of a ML and AI module that we will launch in 2019.
As a supplement to the existing Schema Editor and Flow Engine modules, it will extend the range of functions in the direction of ML and AI and contribute to making the vision a reality – that applications can be developed with less and less programming and special knowledge, which optimally exploit the advantages of graph technology.
Structr is also set to be a sponsor of Neo4j’s GraphTour 2019. Check out the details and find out if GraphTour is coming to a city near you!
New to graph technology?
Grab yourself a free copy of the Graph Databases for Beginners ebook and get an easy-to-understand guide to the basics of graph database technology – no previous background required.
Get My Copy
Grab yourself a free copy of the Graph Databases for Beginners ebook and get an easy-to-understand guide to the basics of graph database technology – no previous background required.
Get My Copy





