
Financial Fraud Detection with Graph Data Science: Identifying Fraud Rings

Graph Analytics & AI Program Director
5 min read

Financial fraud is growing and it is a costly problem, estimated at 6% of the Global Domestic Product, more than $5 trillion in 2019.
Despite using increasingly sophisticated fraud detection tools – often tapping into AI and machine learning – businesses lose more and more money to fraudulent schemes every year. Graph data science helps turn this pattern around.
By augmenting existing analytics and machine learning pipelines, a graph data science approach increases the accuracy and viability of existing fraud detection methods. The end result: Fewer fraudulent transactions and safer revenue streams.
In this blog series, we are taking a closer look at how your data science and fraud investigation teams can tap into the power of graph technology for detecting first-party fraud as well as sophisticated fraud rings.
In this fourth and final blog of our four-part series, we outline a process for finding fraud rings using graph technology.
Example: Identifying Fraud Rings
Fraud rings involve multiple parties working together to defraud merchants, banks or others.
Smaller rings are often run by a group of acquaintances or family members, some of whom may be unwitting participants. Large rings are more likely to be professional and more sophisticated, equipped with technology and resources unavailable to smaller rings.
Fraud rings may cross business roles, making them harder to detect since data about customers and vendors often resides in separate software systems or other data silos. A fraud ring could involve a buyer and a seller, many sellers and many buyers working together and even buyers and sellers with good reputations and valid transactions, with some fraudulent transactions mixed in.
Anomalies of many types may indicate fraud, from a sudden surge in sales and/or returns of a particular product, traffic from particular IP addresses or uncharacteristic purchases for a given demographic.
Although fraud rings are strongly linked, many businesses rely on manual or ad-hoc methods to detect them. Graph data science on connected data increases the likelihood of catching fraud rings in time to minimize – or eliminate – their impact.
8 Steps for Finding Fraud Rings Using Graph Technology
The steps below are just one example. Your approach will vary depending on your goals
and the data itself.
- Use graph queries to uncover a suspicious pattern, such as multiple users coming
from the same IP address. (Some of the techniques used in the first-party fraud
example from blog 3 in this series will also apply.) - Use Community Detection algorithms to identify strongly connected communities
engaged in known fraud across various accounts using email addresses, phone
numbers, authorized users and previously flagged activity. - Use the Louvain Modularity graph algorithm to examine whether hierarchies exist among these communities. Set thresholds to separate petty thieves from fraud rings so that investigators prioritize their efforts.
- Use a Centrality algorithm like PageRank to uncover influential individuals and to
identify high frequency paths. - After verifying the pattern of one fraud ring, use a Similarity algorithm such as
Jaccard to identify other potential fraud participants and rings across your data. - Once the approaches to find fraud rings have been validated by investigators, and
a labeled and scored dataset has been created, you can use these graph-based
features in a machine learning pipeline. - Extract the calculated node and relationship properties – graph features from the
previous step – into your ML environment (e.g., into a Python notebook). Join those
properties with any other relevant tabular data. Use variable selection and model-building
techniques to pinpoint the most important features and use them to
predict future fraudulent activities or entities. - Once you’re satisfied with your results, move your model into production. Write back
any relevant findings to the Neo4j Graph Database to support further exploration.
Beyond Data Scientists: How Graph Analysis Benefits Fraud Investigators
Fraud investigators, like many criminal investigators, have a sense when something is just not right. Current fraud detection tools make it difficult for them to dig into an extended network since tabular data is not designed to capture relationships and reveal network structure.
Benefits of analyzing network structure extend beyond data scientists to everyone involved in fraud detection and investigation. Graph data visualizations are powerful for sharing results with the business and enabling further exploration of a connected dataset. After a data scientist runs graph algorithms, they can visualize the results in Neo4j Bloom. Analysts can then use codeless searches and easy-to-use interactions to explore the dataset in Bloom.
Conclusion
Fraud is a connected data problem.
Graph data science enables you to uncover more fraud and shut it down quickly. Accurate identification of fraudulent patterns focuses your time and energy on real fraud, significantly reducing effort on false positives.
Graph data science enables you to answer questions you cannot answer today without a tremendous amount of effort. The Neo4j Graph Data Science Library offers an enterprise-ready toolset for running sophisticated graph algorithms on connected data at scale. Graph analytics and feature engineering both add highly predictive relationships to your machine learning for better results.
Best of all, adding graph data science to your fraud detection toolkit is non-disruptive. Your existing ML models are already uncovering fraud. By analyzing your data through graph-based fraud detection, you add new dimensions and improve model accuracy without changing your existing ML pipelines. At the same time, you harness the power of graph algorithms to analyze the network structure of your data.
The more fraud you find, the more effective your teams will become at detecting even more subtle cases of fraud (in a virtuous cycle). You uncover a pattern, pursue it, follow another lead and find more anomalies. You operationalize those patterns to detect in real-time and explore yet again to find the ever-changing tactics that fraudsters use to evade detection. At the same time, experience with graph analytics in one area leads to deployment in other areas, such as managing risk and compliance, master data management and real-time recommendations.
Neo4j provides the first enterprise-grade approach to data science that harnesses the natural power of relationships and structures to infer behavior. It offers an integrated graph database for graph persistence so there’s no need to recreate your graph each time it changes; your graph data is natively stored in the graph, available for further exploration and visualization. Neo4j enables you to scale to tens of billions of nodes, empowering you to move from a valuable initial proof-of-concept to a high-performance production environment.
Using Neo4j for graph data science, you gain a practical approach to increase your predictive accuracy with the data you already have.
Discover how organizations are adding graph data science to their machine learning pipelines to find more fraud. Click below to get your copy of Financial Fraud Detection with Graph Data Science.
Share Article



Explore
Related Articles

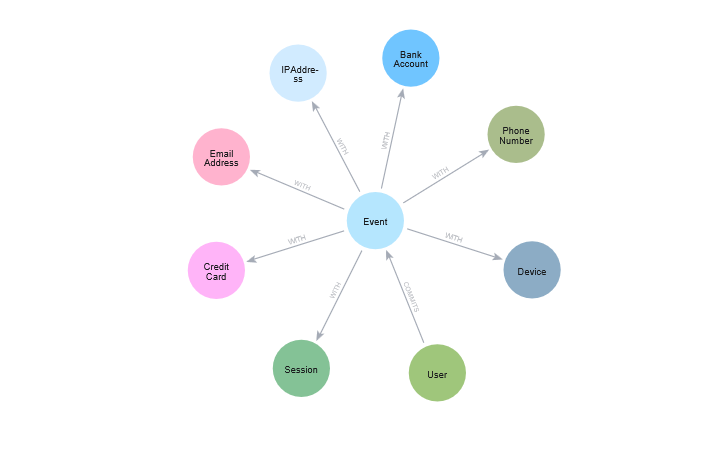
Optimize Weakly Connected Component Projections

Use Weakly Connected Components to Avoid Cypher Query Crashing
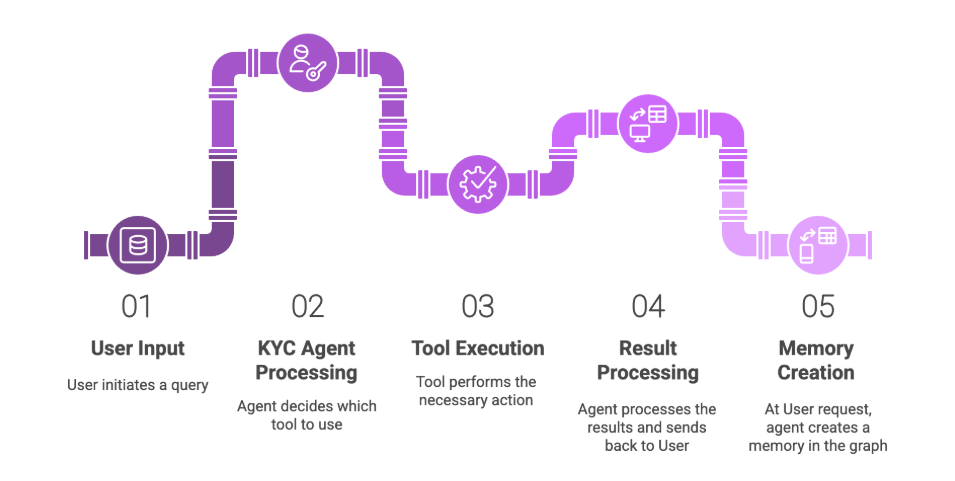
GraphRAG in Action: A Simple Agent for Know-Your-Customer Investigations

Mastering Fraud Detection With Temporal Graph Modeling
