




We published a new book! This technical deepdive about full stack GraphQL applications is hot off the presses, and we want to give you a sneak peek into its offerings. This first chapter teaser is going to whet your appetite for more expert insights into building data-intensive applications, and we are thrilled to offer you the whole book – for free! – whenever you’re ready to learn more. Enjoy!
Getting Started With Full Stack GraphQL
Before beginning our journey with full stack GraphQL, we will take a look at the technologies we will be using and introduce the powerful concept of thinking in graphs. This section of the book focuses on the backend of our full stack application, specifically the database and GraphQL API.
In chapter 1, we introduce the components of a full stack GraphQL application and take a look at the specific technologies we will use throughout the book: GraphQL, React, Apollo, and Neo4j Database. In chapter 2, we dive head first into GraphQL and the basics of building a GraphQL API application. In chapter 3, we explore the Neo4j graph database, the property graph data model, and the Cypher query language.
Then, in chapter 4, we show how to leverage database integrations for GraphQL and, specifically, the Neo4j GraphQL library to build GraphQL APIs backed by a graph database. After completing this first part of the book, we will have our database and initial GraphQL API application up and running and will be ready to start building the frontend in part 2.
Chapter 1: What Is Full Stack GraphQL?
1.1 A Look at Full Stack GraphQL
In this chapter, we take an introductory look at the technologies we will use throughout the book. Specifically, we’ll look at the following:
- GraphQL – For building our API
- React – For building our user interface and JavaScript client web application Apollo – Tools for working with GraphQL, on both the server and client
- Neo4j Database – The database we will use for storing and manipulating our application data
Building a full stack GraphQL application involves working with a multitier architecture, commonly known as a three-tier application, which consists of a frontend application, the API layer, and a database. In figure 1.1 we see the individual components of a full stack GraphQL application and how they interact with each other.
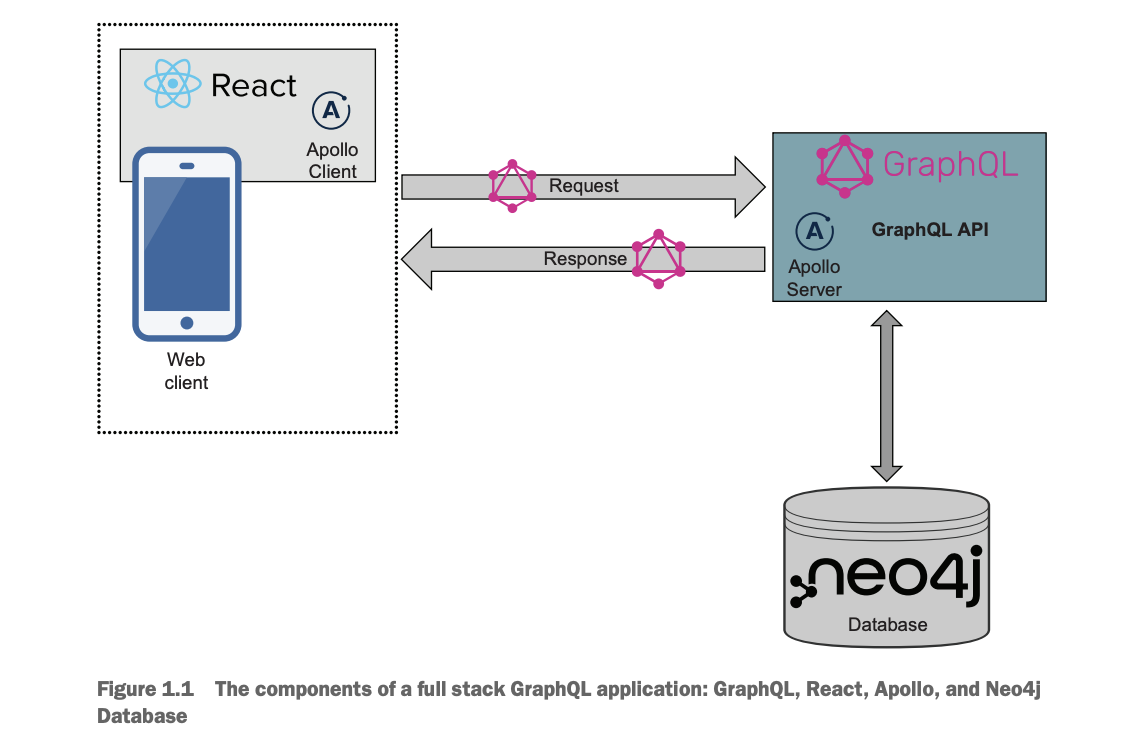
Throughout this book, we will use these technologies to build a simple business review application, working through each technology component as we implement it in the context of our application. In the last section of this chapter, we review the basic requirements of the application we will be building throughout the book.
The focus of this book is learning how to build applications with GraphQL, so as we cover GraphQL, we’ll do so in the context of building a full stack application and using GraphQL with other technologies, including designing our schema, integrating with a database, building a web application that can query our GraphQL API, adding authentication to our application, and so on. As a result, this book assumes some basic knowledge of how web applications are typically built, but it does not necessarily require experience with each specific technology.
To be successful, the reader should have a basic familiarity with JavaScript, both client side and Node.js, and concepts such as APIs and databases. You should have installed node and should be familiar with the basics of the npm command line tool (or yarn) and how to use it to create Node.js projects and install dependencies. We will use the latest LTS version of Node.js as of this writing (16.14.2), which is available to download at https://nodejs.org/. You may wish to use a Node.js version manager such as nvm for managing Node versions. See https://github.com/nvm-sh/nvm for more information.
We include a brief introduction to each technology and suggest other resources for more in-depth coverage where needed by the reader. It is also important to note that we will cover specific technologies to be used alongside GraphQL and that at each phase, a similar technology could be substituted (e.g., we could build our frontend using Vue instead of React). Ultimately, the goal of this book is to show how these technologies fit together and provide the reader with a full stack framework for thinking about and building applications with GraphQL.
1.2 GraphQL
At its core, GraphQL is a specification for building APIs. The GraphQL specification describes an API query language and a way of fulfilling those requests. When building a GraphQL API, we describe the data available using a strict type system. These type definitions become the specification for the API, and the client is free to request the data it requires based on these type definitions, which also define the entry points for the API.
GraphQL is typically framed as an alternative to REST, which is the API paradigm you are mostly likely to be familiar with. This can be true in some cases; however, GraphQL can also wrap existing REST APIs or other data sources. This is due to the benefit of GraphQL being data-layer-agnostic, meaning we can use GraphQL with any data source.
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools. – graphql.org
Let’s dive into some more specific aspects of GraphQL.
1.2.1 GraphQL Type Definitions
Rather than being organized around endpoints that map to resources (as with REST), GraphQL APIs are centered around type definitions that define the data types, fields, and how they are connected in the API. These type definitions become the schema of the API, which is served from a single endpoint.
Since GraphQL services can be implemented in any language, a language-agnostic GraphQL Schema Definition Language (SDL) is used to define GraphQL types. Let’s look at an example in figure 1.2, motivated by considering a simple movie application. Imagine you’ve been hired to create a website that allows users to search a movie catalog for movie details, such as title, actors, and description, as well as show recommendations for similar movies the user may find interesting.
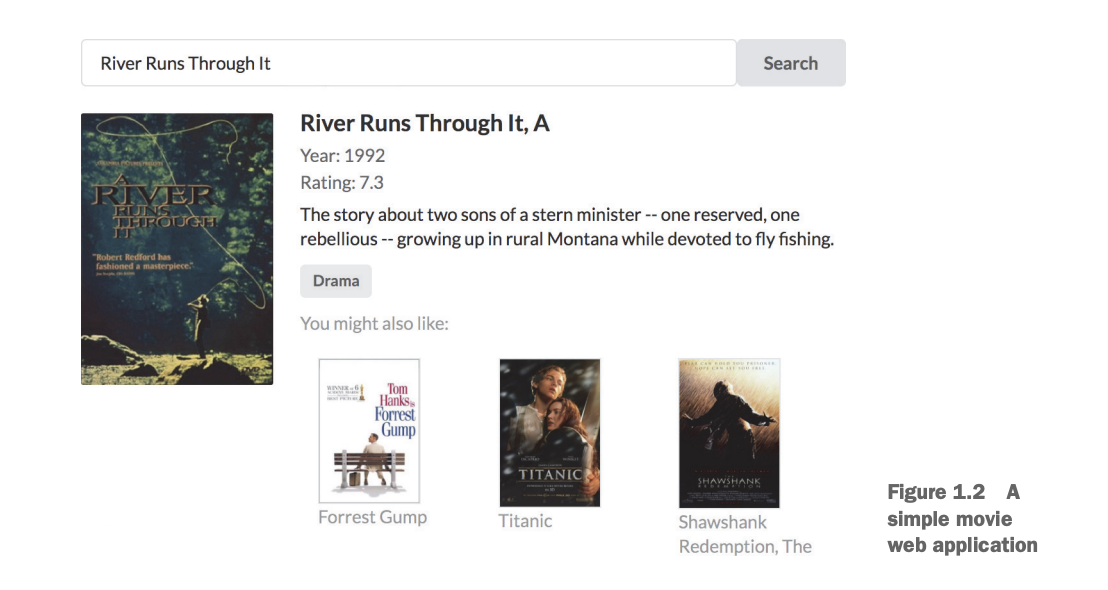
Let’s start in the next listing by creating some simple GraphQL type definitions that will define the data domain of our application.
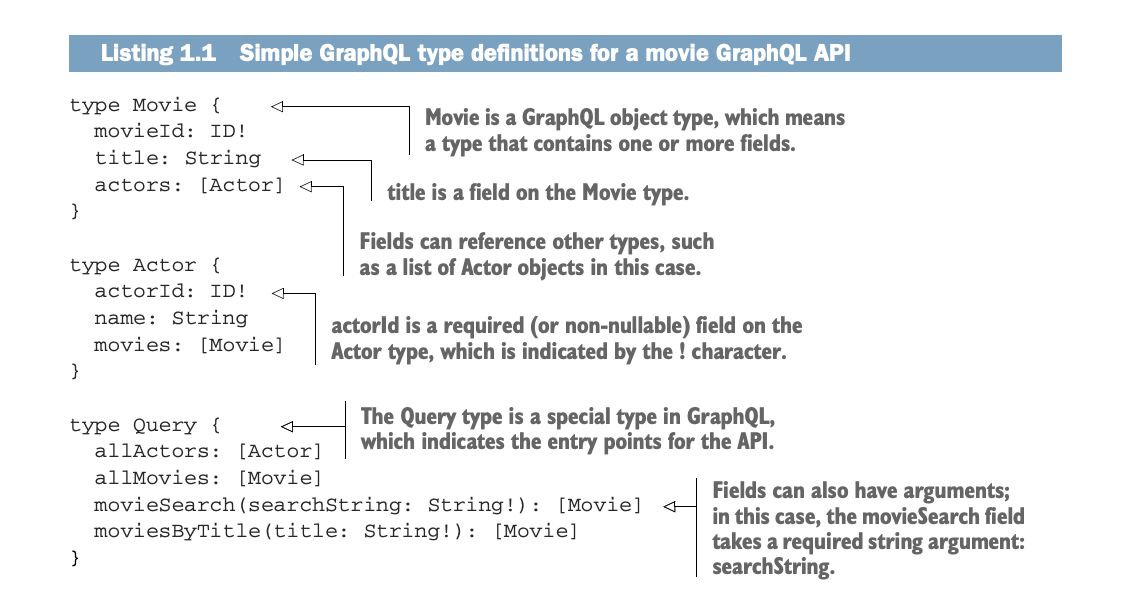
Our GraphQL type definitions declare the types used in the API, their fields, and how they are connected. When defining an object type (such as Movie), all fields available on the object and the type of each field are also specified (we can also add fields later, using the extend keyword). In this case, we define title to be a scalar String type – a type that resolves to a single value, as opposed to an object type, which can contain multiple fields and references to other types.
Here actors is a field on the Movie type that resolves to an array of Actor objects, indicating that the actors and movies are connected (the foundation of the “graph” in GraphQL).
Fields can be either optional or required. The actorId field on the Actor object type is required (or non-nullable). This means that every Actor object must have a value for actorId. Fields that do not include a ! are nullable, meaning values for those fields are optional.
The fields of the Query type become the entry points for queries into the GraphQL service. GraphQL schemas may also contain a Mutation type, which defines the entry points for write operations into the API. A third special entry-point-related type is the Subscription type, which defines events to which a client can subscribe.
NOTE: We’re skipping over many important GraphQL concepts here, such as mutation operations, interface and union types, and so on, but don’t worry; we’re just getting started and will get to these soon enough!
At this point, you may be wondering where the graph is in GraphQL. It turns out that we’ve defined a graph using our GraphQL type definitions. A graph is a data structure composed of nodes (the entities or objects in our data model) and relationships that connect nodes, which is exactly the structure we’ve defined in our type definitions using SDL. The GraphQL type definitions previously shown have defined a simple graph with the following structure (see figure 1.3).
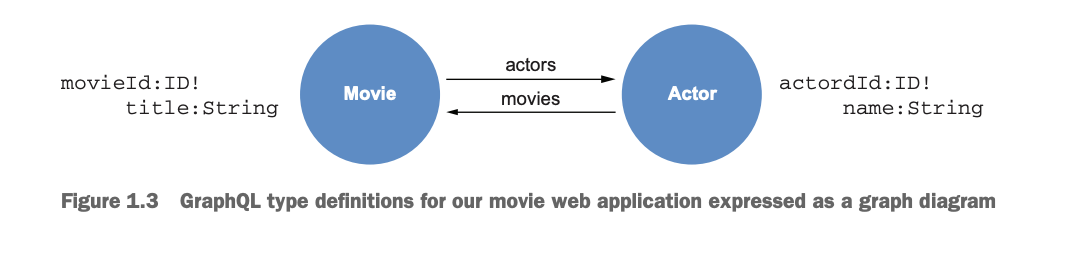
Graphs are all about describing connected data, and here we’ve defined how our movies and actors are connected in a graph. GraphQL allows us to model application data as a graph and traverse the data graph through GraphQL operations.
When a GraphQL service receives an operation (e.g., a GraphQL query), it is validated and executed against the GraphQL schema defined by these type definitions. Let’s look at an example query that could be executed against a GraphQL service defined using the previously shown type definitions.
1.2.2 Querying with GraphQL
GraphQL queries define a traversal through the data graph defined by our type definitions and request a subset of fields to be returned by the query – this is known as the selection set. In this query, we start from the allMovies query field entry point and traverse the graph to find actors connected to each movie (see the next listing). Then, for each of these actors, we traverse to all the other movies they are connected to.

Note that our query is nested and describes how to traverse the graph of related objects (in this case, movies and actors). We can represent this traversal through the data graph and the results visually (see figure 1.4).
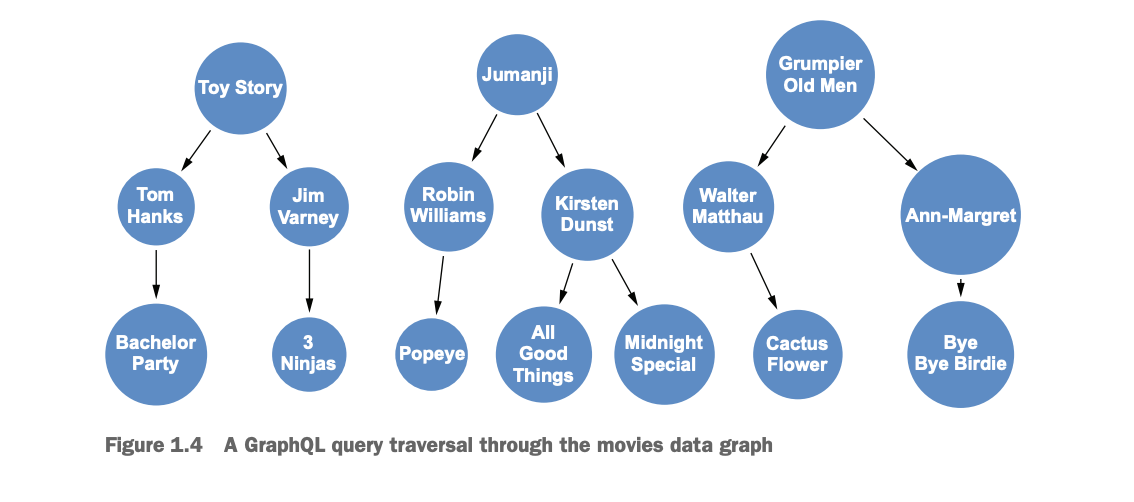
Although we can represent the traversal of the traversal of the data graph visually, the typical result of a GraphQL query is a JSON document, as shown in the next listing.





