


Fullstack GraphQL with Neo4j

Developer Relations Engineer
20 min read

Editor’s Note: This presentation was given by Will Lyon at GraphConnect New York in September 2018. He recently published the book, Fullstack GraphQL Applications with GRANDstack.
Presentation Summary
Will Lyon is a Neo4j Developer Relations Engineer. He is familiar with Neo4j, both from the inside building applications as well as from the outside as a customer. Today’s session features an introduction to GraphQL.
GraphQL is an API query language and runtime for building APIs originally built by Facebook. GraphQL queries allow you to describe your data, ask for what you want, and then deliver predictable results. They do this by specifying entry points, selection sets, and then determine how to traverse schemas based on what fields the user wants to return. In GraphQL, the response matches the fields in the selection set and query, so users should only get back the data that was requested.
In GraphQL’s First Development, your graph schema is the first aspect to understand. The GraphQL schema becomes your specification for the API and is used to mock an API. This API is what will be written by front-end developers and then given to backend developers. These two teams work together so you are able to build up the front-end and backend at the same time.
To understand how GraphQL works, we must first start with a GraphQL schema. From type definitions we define query types, which are entry points for the API. We define our schema with our Schema Definition Language and then we define our resolvers.
Next, we execute a Cypher query. When it comes back, we are going to format it. For our example, we use the Apollo Server library, which wraps graphql-js. The Apollo Server has an executable schema function, which we pass our type definition into and that will deliver our executable schema. Instantiating a Neo4j driver, and passing things into Apollo Server, will spin up an Express Server and serve our GraphQL endpoints. That is the standard way GraphQL API’s work, but this approach still has its problems.
Neo4j GraphQL was built with specific goals in mind:
- Drive the database data model
- Generate Cypher from GraphQL
- Autogenerated resolvers (no boilerplate)
- Extend GraphQL functionality with Cypher
There are two versions of Neo4j GraphQL. The first version is the database plug in which was written in Kotlin (JVM). It was deployed to Neo4j and serves as a GraphQL endpoint. The second is neo4j-graphql-js, written in JavaScript, which makes it compatible with any JS GraphQL implementation including graphql-js, Apollo Sever, etc.
Neo4j GraphQL is part of GRANDstack. GRANDstack is composed of GraphQL, React, Apollo and Neo4j Database. This set of tools comes together from building modern applications.
Full Presentation
My name is Will Lyon. I work on the Developer Relations Engineering team at Neo4j. I work on the database to make it easier to build applications with Neo4j. I’ve done that for the last three years. Before that, I worked at a few different startups as a software engineer. A few of them used Neo4j as a customer. For that reason, I’ve seen Neo4j from both sides.
Today, we’re going to do an introduction to GraphQL. We’ll look at how we build a GraphQL service, and then dive into some of the Neo4j GraphQL integrations that we’ve been working on. We’ll talk a little bit about some features we want to add to those integrations and what’s coming down the pipeline for those.
GraphQL is an API query language and runtime for building API’s. We think of GraphQL as an alternative to REST for building API’s. With GraphQL, we start with a strict GraphQL schema and that defines the types, the fields available in each type, and the entry points for our API.

A GraphQL query specifies the entry point. Which entry point are we hitting? Are we searching for users by ID, are we searching for all movies with the title of The Matrix? Where are we starting?
Then a GraphQL query specifies a called selection set. Once we’ve started in our entry point, how do we want to traverse this graph? How do we want to traverse our schema? What fields do we want to return?
In REST, we hit an endpoint that has a very well-defined response that we’re going to receive. With GraphQL the response matches the fields in our selection set and our query. We’re only going to get back the data that we requested.
GraphQL was created in Facebook a few years ago. They created it to solve two very specific problems.
One was to reduce the number of network requests sent to render a view. If you think of News Feed where we have a bunch of posts and articles and we have users associated with those posts. We want to load News Feed so we hit the personalized News Feed endpoint, we get a bunch of articles. If we don’t have the proper user data cached on our device, we might need then to hit a user endpoint to hydrate each one of those user objects. So we may end up making several requests to render this one News Feed view.
The second problem that Facebook was trying to solve when they created GraphQL is reducing the amount of data sent over the wire. We said that we only send back the fields that we’ve requested in our query.
First, we don’t have to go to the data layer to fetch all those fields to resolve them if the client is not going to use them. That saves us query time and execution time by not fetching from the data layer. Then that’s also less data that we send over the wire so if we’re on a slow wireless network, our payloads are going to be a lot smaller.
These are the reasons that Facebook created GraphQL. They open sourced it a few years ago and the community has really been building a lot of cooling on top of GraphQL since then.

GraphQL makes this really important observation that your application data is a graph. It’s called GraphQL for a reason. Regardless of how you store your data on the backend in your database, your application data, users and customers are a graph. GraphQL recognizes that and presents your API to you to query as a graph.
GraphQL Example
Let’s look at an example.
Let’s say we have data about movies. We have the genre of the movie, who directed it, who acted in it, what other movies did they act in, etc.
We start with a GraphQL schema and that defines our type.

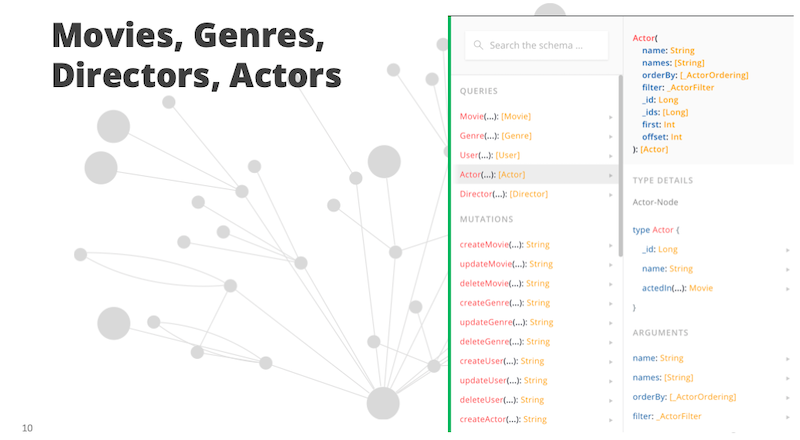
We have movie genre, actor, director and we have the fields specified on each one of these. If we spin up our GraphQL API, we see our documentation for it.
Below is a screenshot from GraphQL Playground, which is like an Integrated Development Environment (IDE) for working with GraphQL API’s. You see that we have queries and mutations on the left. These are the entry points for our GraphQL service. Then on the right, we have information about our types and the fields that are available.
If we send a GraphQL query, then it will look like this example:
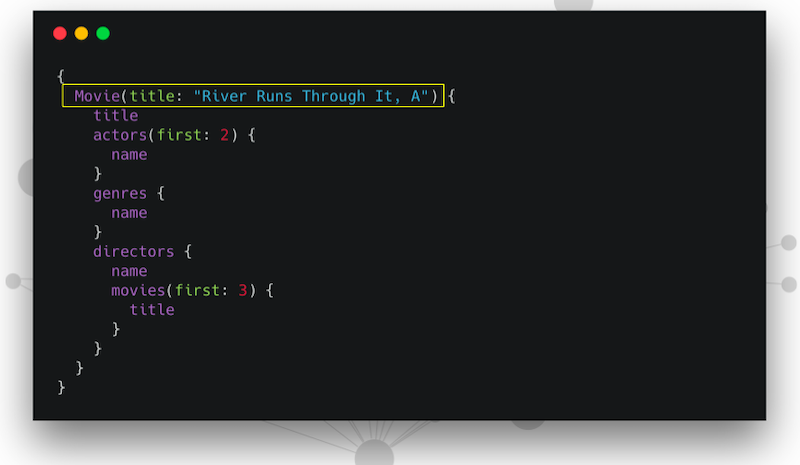
Note that we’re specifying an entry point. In this case – movie. We’re passing in the title of the movie we’re searching for. The movie is A River Runs Through It, and then we have a selection set following that. The selection set is saying, okay, once you’ve found A River Runs Through It, these are the fields we want you to grab off off that node. Then we want you to find the actors.
Traverse this application data graph to find the actors, grab their name, genres and directors. Who directed A River Runs Through It? Grab their name.
We’re nesting within directors. We’re saying, okay, so whoever directed A River Runs Through It, what other movies did they direct? Give me the first three that you find and the title of those movies.
We’re expressing how we want to traverse this graph. Our GraphQL implementation is going to contain the logic for how to fetch that from the data layer. In this case, we’re fetching it from Neo4j, so we’re doing an actual graph traversal.

When our data comes back, we see that the format matches our GraphQL query. We get back just the data that we asked for.
Does that mean that we don’t need Cypher? No, not at all.
It’s important to understand that GraphQL is an API query language, not a database query language. This means it has limited expressivity. We can’t do projections, aggregations or express variable length paths, like in Cypher.
GraphQL is just a query language for querying an API. GraphQL is also data-layer agnostic. It’s not tied to any specific database or data layer. In fact, one of the great benefits of GraphQL is that we’re able to wrap existing API’s. We have one GraphQL service call out to multiple data layers, so that’s really flexible. This, I think, is a key point to understand.
It’s also worth noting that, if we want to build a GraphQL API, we’re not just limited to working on new projects. We are also able to wrap exiting REST API’s. We combine multiple data sources into one GraphQL service. And we could also do what’s essentially the microservices of GraphQL, which is called schema stitching, where we take lots of different GraphQL services and stitch them together into one unified schema.
For new projects, there are many great tools we call these GraphQL engines. These engines basically help us spin up a GraphQL API either on top of an existing database, or something that’s the equivalent of an ORM, to help us quickly build GraphQL projects.
GraphQL First Development
There’s an important concept working with GraphQL, called GraphQL First Development or Schema First Development, which is important to understand.
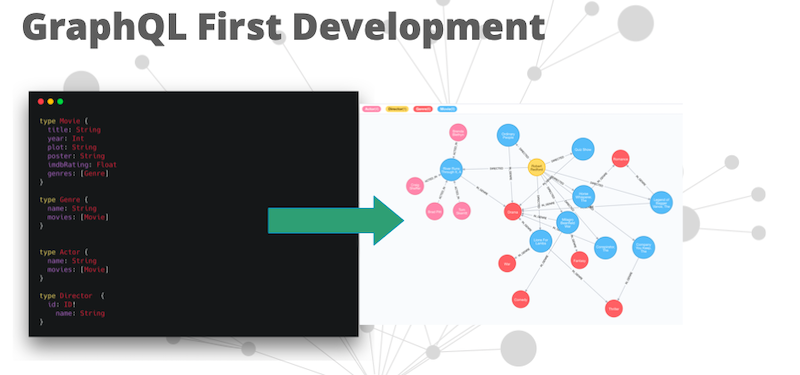
Your GraphQL schema becomes your specification for the API. You actually use the schema to mock an API, because you know the types of all your fields – this is actually something that’s done very frequently. The front-end developers will say, “This is my ideal schema.” Then front-end developers will write it and give it to the backend folks.
They mock the schema, so you’re able to build up the front-end and the backend at the same time.
Example GraphQL API
Let’s look at an example.
This is a project we built a few weeks ago on the Neo4j Community Forum.
The Neo4j Community Forum is a discourse forum. We’ve added personalized content to the top, and we have these community activity feeds where we’re showing popular community content, popular community projects and newly certified developers.
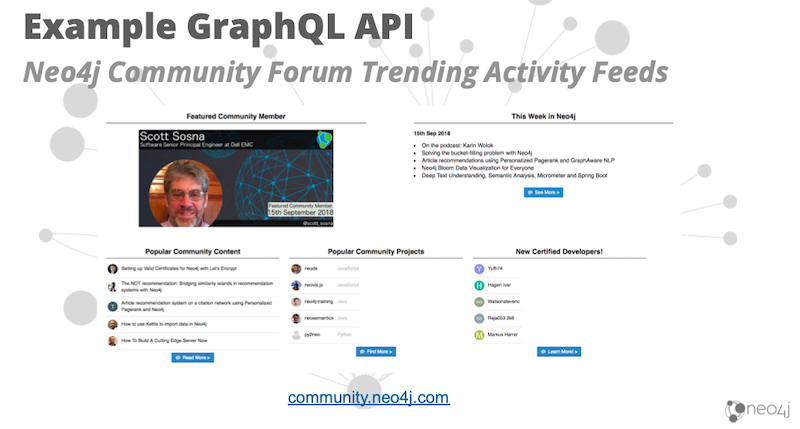
These are activity feeds showing interesting blog posts in the community, interesting open source projects and Neovis-js.
This is all populated from a GraphQL API. What happens when this page loads is it uses jQuery to send a GraphQL query to some endpoint that gives us back the data to load this view. Let’s talk about how we built that GraphQL API to serve this community content.
This is an open GraphQL endpoint; it’s available in the GraphQL Playground. This is a tool I mentioned earlier for exploring GraphQL API’s.
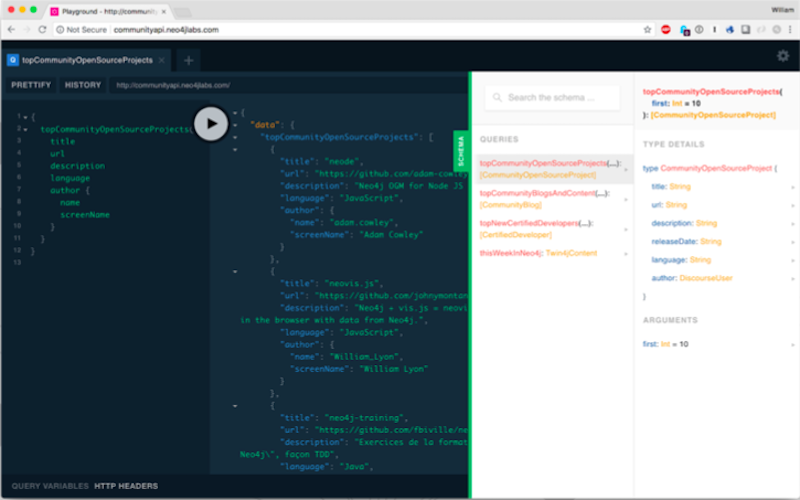
The first thing I do is explore my schema. I see I have four – these are fields on a query type. A query is a specific kind of type that specifies the entry points I’m able to hit. I have top community open source projects, top community blogs and content. Then I am able to inspect the type that those resolve to.
Let’s go ahead and write a query here. I want to see top three community blogs and content.
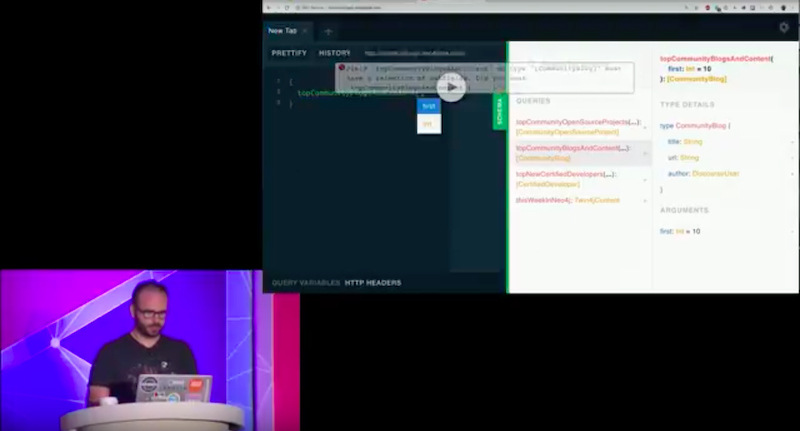
That’s my entry point, and now I need to specify a selection set. Let’s get the title and URL.
This search is giving me these blog posts:
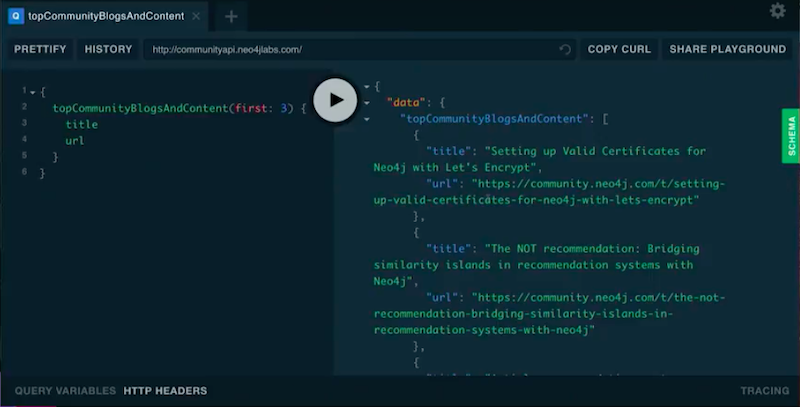
One post is about valid certificates for Neo4j Let’s Encrypt, another one is about recommendations.
I also want to look at the author. For the author, I get a name and screen name. Now, when I see that query, I see it was David Allen who wrote this post about valid certificates. I see who wrote the other posts, as well.
That’s how we query the GraphQL endpoint. I wrote a blog post about this. This has the details in the code but we’ll step through it a little bit.
How Does GraphQL Work?
First, where’s the data coming from? We’re ultimately recording a Neo4j instance. We call it the Community Graph.
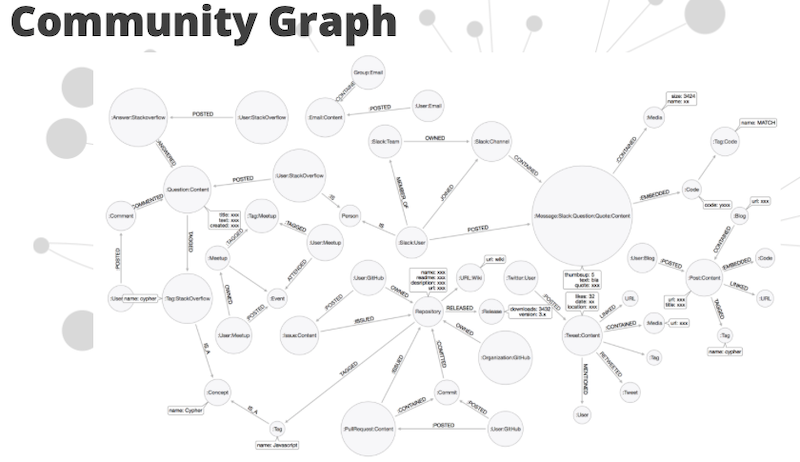
The DevRel team has built tooling to monitor sites like GitHub, Stack Overflow, Twitter and MeetUp. This has been for people who are posting Neo4j-related projects to GitHub or people who are writing blogs about Neo4j.
We load them into the Community Graph. We have the data in Neo4j. We start with a GraphQL schema.

We start with our type definitions, we define community blog and a discourse user. We define the fields on each of those. We define our query type – the entry points for API.

We want to be able to search for community blogs and content, and that is going to give us an array of community blog objects.
This is some JavaScript:

That GraphQL’s schema that we defined is really just a string. That means it’s SDL, Schema Definition Language. There’s a specific language that’s used to define these GraphQL schemas. The reason this language exists is because it’s language agnostic.
We define this schema. We use this in JavaScript, Java, Python or any of the other GraphQL implementations. We happen to be using JavaScript here.
The next thing we need to do is define our resolvers.

Resolvers are the functions that contain the logic for fetching data from our data layer. In JavaScript, this is an object with a bunch of functions. Inside our resolver we might want to check an authorization header to ensure the user has permissions for this resource. We might want to send a query to a database, format the results and so on.
In our case, we’re going to execute a Cypher query. This is the Cypher query that we run:
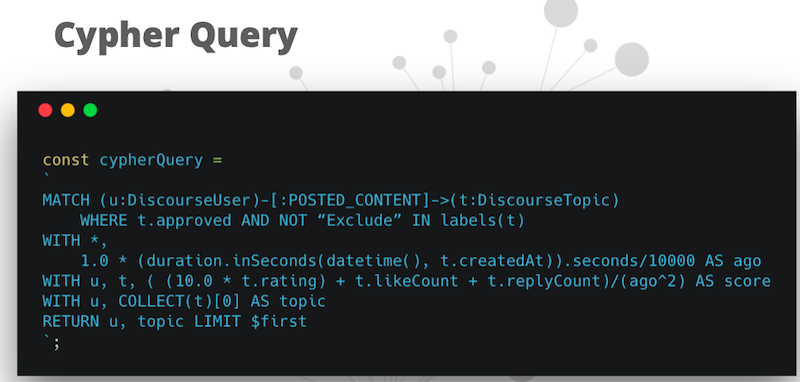
The Cypher query is looking for users in the Community Graph that posted some content. Then it uses an exponential time decay function to rank them. This is something like the Hacker News and reddit, and contains the interesting things that people are uploading. Trending topics go to the top and boring stuff that nobody cares about just floats away. This is pretty easy to do in Cypher.
Then comes our resolver.
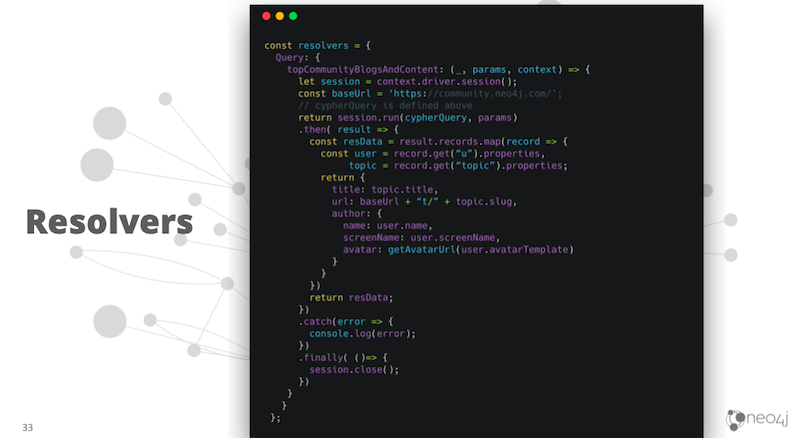
We’re going to execute that Cypher query. When it comes back, we’re going to format it a little bit, and then take on a base URL to display on the website.
We serve this GraphQL endpoint with Apollo Server. Apollo is a company that’s really becoming the GraphQL company. They’re building lots of tooling, both on the server and the client for working with GraphQL.
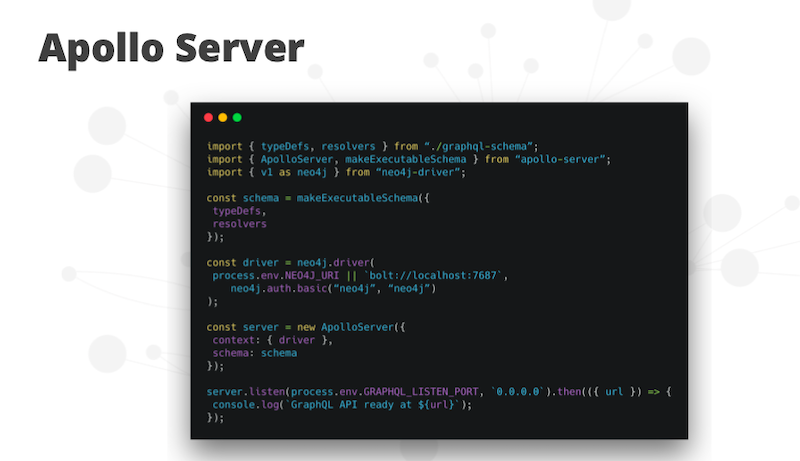
In this case, we’re using the Apollo Server library, which wraps graphql-js. Graphql-js is the JavaScript implementation of GraphQL and Express. Express is a common web server for Node.js.
We use this executable schema function from Apollo Server, then we pass in our type definition, which is our schema and our resolvers. That gives us an executable schema:
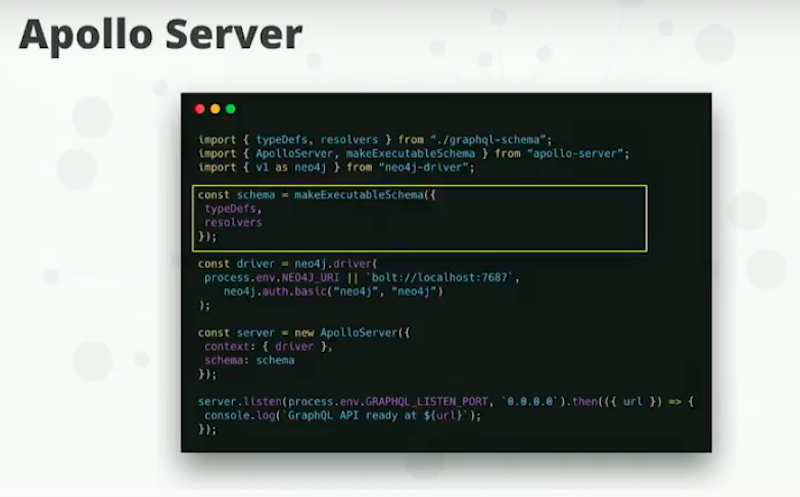
We instantiate a Neo4j Driver instance, and we pass these to Apollo Server. That’s going to spin up an Express Server that’s going to serve our GraphQL endpoints.
That’s what I’ll call the standard way to GraphQL API’s, implements and resolvers.
There are a few problems with this approach though.

One problem is schema duplication. I have to maintain a database schema, and I have to maintain a GraphQL schema.
I have some mapping and translation layer, because I have graph on the front-end of GraphQL. Maybe I’m not storing my data as a graph, so I have some mapping and translation layer to work there.
There’s a lot of boilerplate code you saw we had to work with for executing our query. We had to implement all these resolvers.
Then, performance-wise, we have what’s called an n+1 query problem. We didn’t see it here because we’re resolving our query, which is just a single Cypher query. But imagine if we had to fetch all of these blog posts, and then for each blog post we had to go back to the database and say, “Database, please tell me the user of this blog post.” This is the n+1 query problem, where we make a bunch of queries to the database.
Neo4j GraphQL
About a year ago, the DevRel team said we would build a Neo4j GraphQL integration.
I think GraphQL for graph databases in Neo4j make sense for a lot of reasons. These are the goals we set for our Neo4j-GraphQL integration.

One, we want to support GraphQL First Development. That’s very important. We want the GraphQL schema to drive the database model.
Then we want to generate Cypher from GraphQL. When you send a GraphQL request, we don’t want you to have to specify the Cypher that maps to that of your resolver. We just want to generate that from some arbitrary GraphQL request. More importantly, we want this to be a single Cypher query. For any arbitrary GraphQL request, we want just one round trip to Neo4j.
The boilerplate is no fun, so let’s not make it so developers have to implement resolvers.
Then we want to extend the power of GraphQL with Cypher. Cypher is this amazing, expressive graph database query language. We do this by adding what’s called a schema directive to GraphQL. Schema directives are GraphQL’s built-in extensibility mechanism.
Let’s throw a Cypher directive in there.
GraphQL First Development
We infer the Neo4j database model from the GraphQL schema.
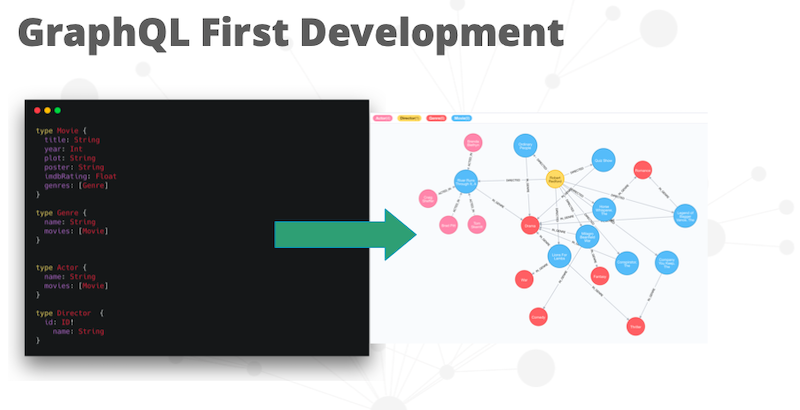
That’s pretty easy to do because it’s a graph.
Then we generate Cypher from GraphQL:
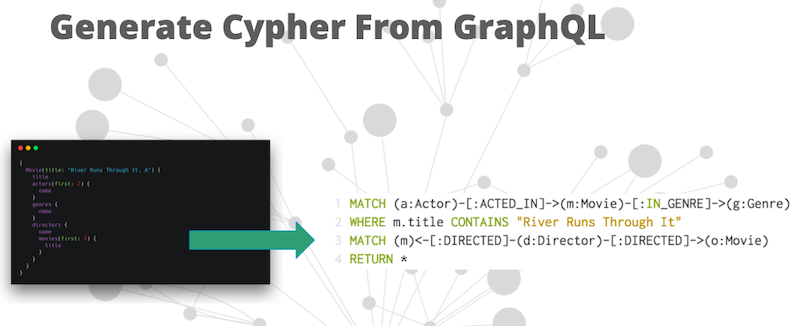
This actually ends up being fairly easy, because we know what the database model is going to be by inferring that from the schema. We apply some rules for generating Cypher from any arbitrary graph bill request – then, extend GraphQL with Cypher.

By extending GraphQl with Cypher, we’ve added support for these Cypher schema directives. We annotate any field, either on a query type or any field anywhere in the type definition with a Cypher query. What that does is make that field a computed field. We run that Cypher query as a sub-quer,y and the results are then mapped to that field in your schema.
Two Versions of Neo4j GraphQL
There’s two versions of our Neo4j graph development integration.

One is the GraphQL database plugin. This is JVM, it’s written in Kotlin, so it’s for the JVM. It’s deployed to Neo4j and, with this, Neo4j directly serves your GraphQL endpoint. This also exposes some GraphQL procedures, so you run GraphQL in Cypher that generates Cypher.
Then we also have neo4j-graphql-js. This is a JavaScript library that’s intended to work with any of the JavaScript GraphQL implementations, like graphql-js, Apollo Server, et cetera.
Let’s take a look at the GraphQL database plugin.
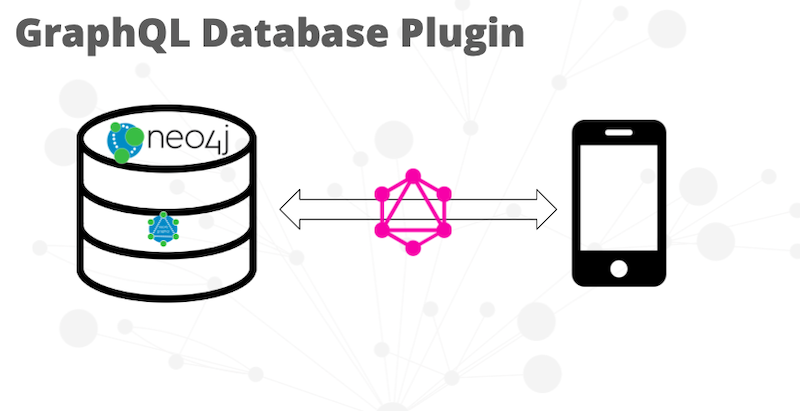
The basic idea is that this plugin is deployed to Neo4j. Neo4j serves a GraphQL endpoint. Your clients then talk directly to Neo4j by sending GraphQL requests, which are available in the Neo4j Desktop. You just click the install button and you’re good to go.
Generating GraphQL API from Existing Neo4j Database
Let’s look at generating GraphQL API from an existing Neo4j database.
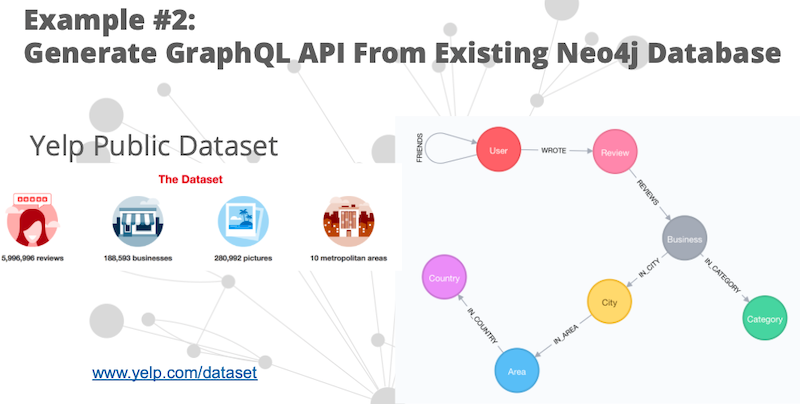
I have the Yelp Public Dataset loaded in Neo4j. This contains businesses, reviews and stuff like that.
We’ll switch over to Neo4j Desktop.
Start Neo4j. Open Reviews. I’ve already installed the GraphQL plugin. We verify that just by seeing the plugins we have available at the bottom. We’ll go to Neo4j Browser.
We have this data from Neo4j. If we want to spin up a GraphQL API, how do we do that? We use graphql.idl.
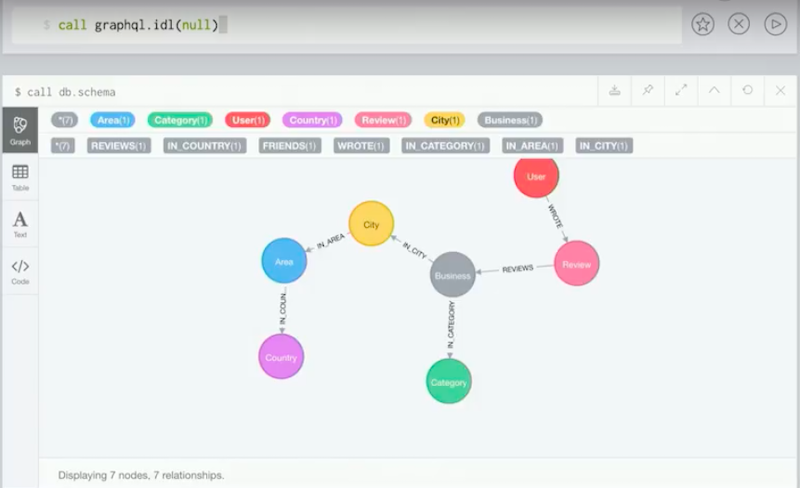
This is a procedure that is exposed by the plugin Interface Definition Language (IDL), this is another name for SDL.
We have two options here: We pass a GraphQL schema to this plugin and the plugin will then spin up a GraphQL API on top of Neo4j using that GraphQL schema, or if we don’t pass anything it’ll just infer the schema from our database, which is what we want to do.
This is GraphQL Playground that I’m running locally.
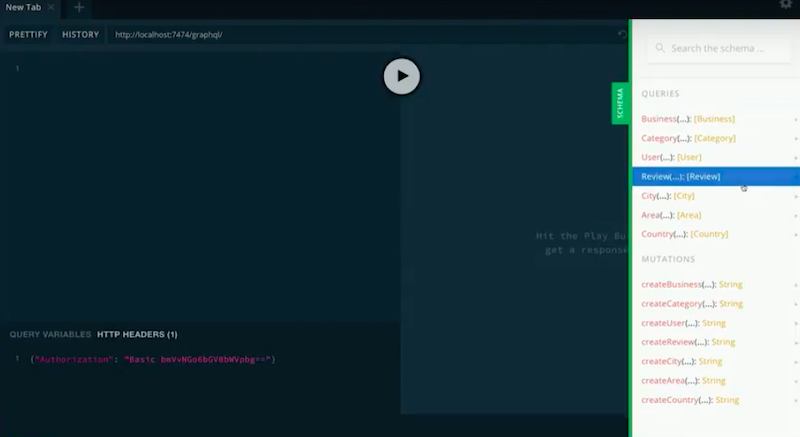
If we check out our schema, we see we have queries and mutations, we query for businesses by any of the properties on those nodes. We could query for categories and so on.
Let’s make sure this works. We will query for users named Will. I’m sure there’s a bunch, so we’ll take the first one. Let’s get his name. Then let’s see the reviews he wrote. We are able to look for what you want. Texts, stars… and then let’s traverse out to the business, what city is it in, and what’s its name?
Behind the scenes, this is generating the Cypher query.
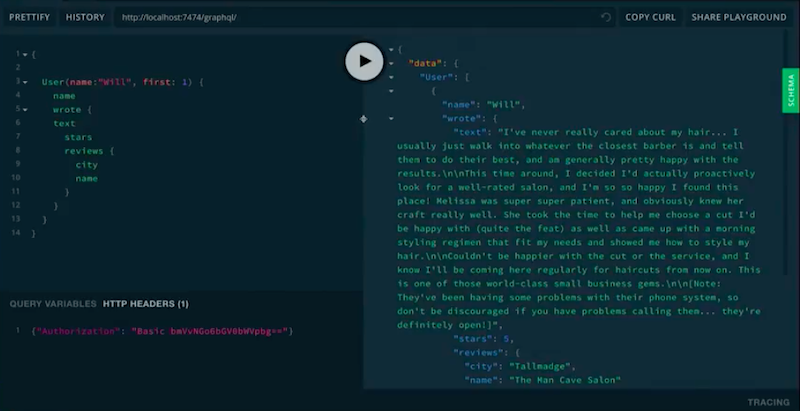
Will. Limit one. Here’s some guy named Will. He reviewed the Man Cave Salon. He gave it five stars. That’s cool, it must be a good place. That’s the plugin.
Neo4j GraphQL-JS
I’m going to leave it at that and move on to neo4j-graphql-js. This is the next version of our GraphQL integration.
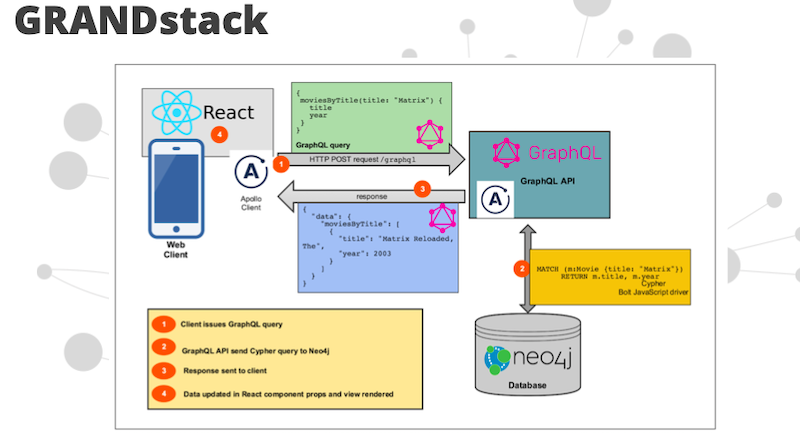
Neo4j-graphql-js available on NPM. NPM install neo4j-graphql-js. Here’s what the architecture looks like in my lovely diagram here:
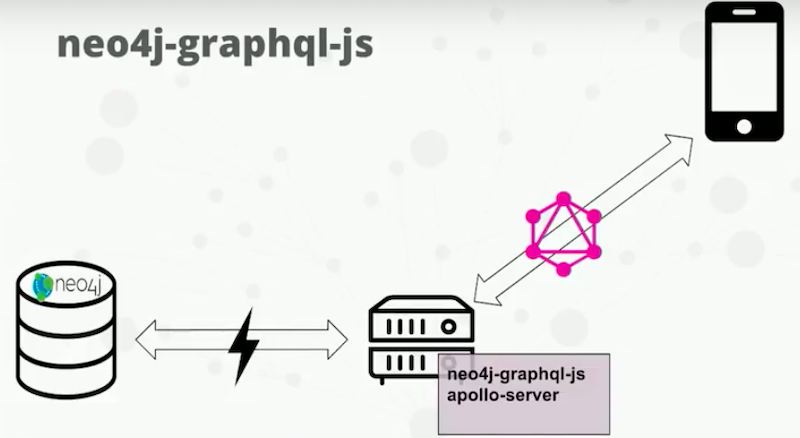
Instead of your client hitting Neo4j directly, you’re running an Express server, or something like that, that’s serving your GraphQL endpoint. That Express server is what’s actually hitting Neo4j with your generated type queries. It’s using our bolt drivers, taking advantage of that for fetching data from Neo4j. We do low balancing on our GraphQL servers. We do caching if we want to. We don’t always want to hit the database directly.
Our third way of building a GraphQL API with neo4j-graphql-js is to switch back and switch databases here. On Neo4j Desktop, I’m going to stop the Reviews database and switch to the GraphConnect schedule graph.
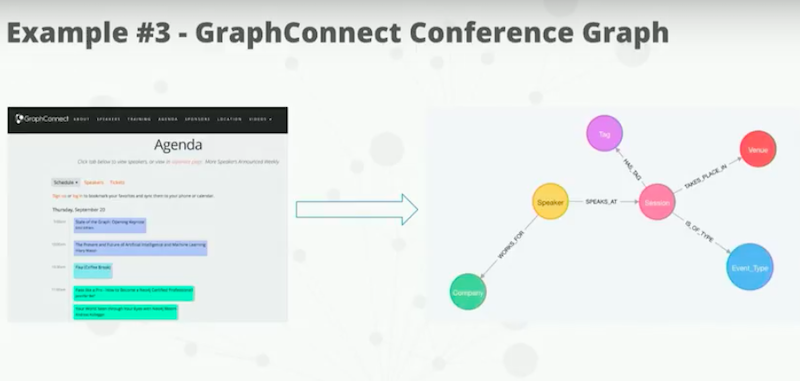
Every year, my colleague Rik imports the GraphConnect’s agenda into Neo4j so that users are able to query it in Neo4j. Let’s take a look at this database.
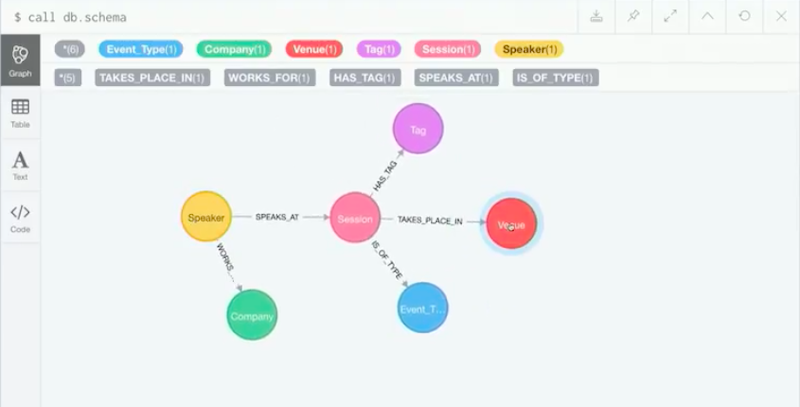
We have speakers that speak at a session. It takes place in a venue. Whatever room it takes place in has a tag. This session is tagged GraphQL. What we want to do is put a GraphQL API on top of this using neo4j-graphql-js. How are we going to do that?
First, we define a GraphQL schema. Here’s what the schema looks like.
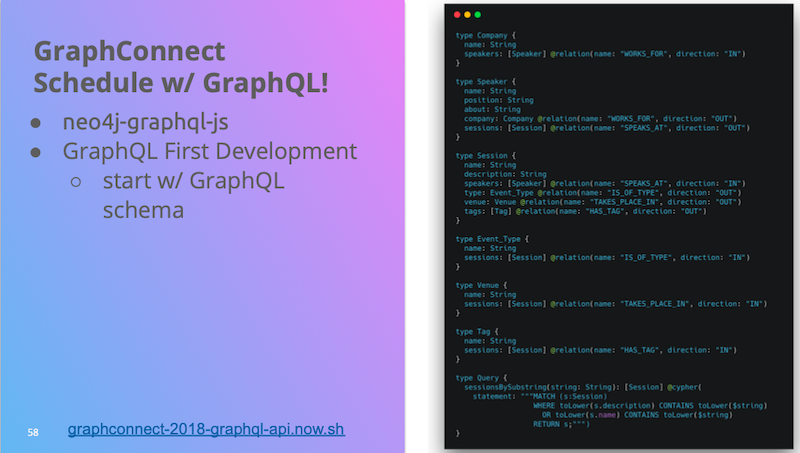
There are a couple of additions here. The previous schemas we saw when we were looking at movies and actors, it showed this field actors points to an array of actors. One thing we need to do is give neo4j-graphql a hint of the relationship type and the direction when we’re talking about referencing another type in our schema. That’s where this @relation directive comes in.
When we’re talking about a speaker that’s connected to a company, we use this @relation directive to annotate this schema and say the relationship tag we want to use is called Works For and it’s going out from the speaker to the company.
Then we also have added a session via a sub-string query field that’s annotated with a Cypher statement, so that we’re able to search for exact matches and what Cypher contains. We add the query, otherwise, it’s a fairly standard GraphQL schema.
What do we do here?
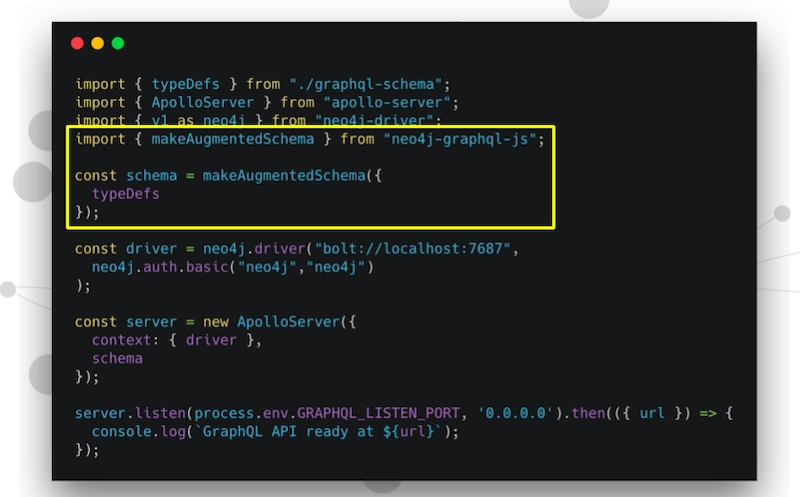
Think back to what we did two examples ago. In our first example, we were working with the discourse data. We imported “make executable schema” from Apollo Server. Here we’re grabbing “make augmented schema” from neo4j-graphql-js and we’re passing in our type definition.
What are we getting from just that string? Well, we’re getting an executable schema object, and we just pass that directly to Apollo Server.
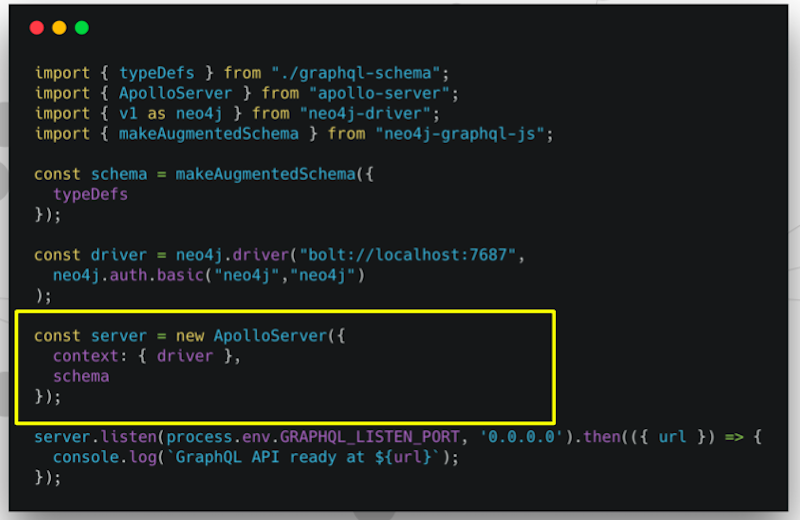
Note that we didn’t define any resolvers. All we defined was that GraphQL schema. Previously, we had all that boilerplate code that said, “Please give me a connection to the database and send this query.” Then format the results in whatever manner that is asked. We had to do that for every type.
One thing that’s nice about neo4j-graphql-js is those are generated for us. That’s this idea of reducing boilerplate.
Let’s run this and see if this works.
Let’s search for speakers named Will Lyon. We grab their name, then source out to the company, grab the company name and see also all of the sessions that this speaker has at GraphConnect. So we run this and…
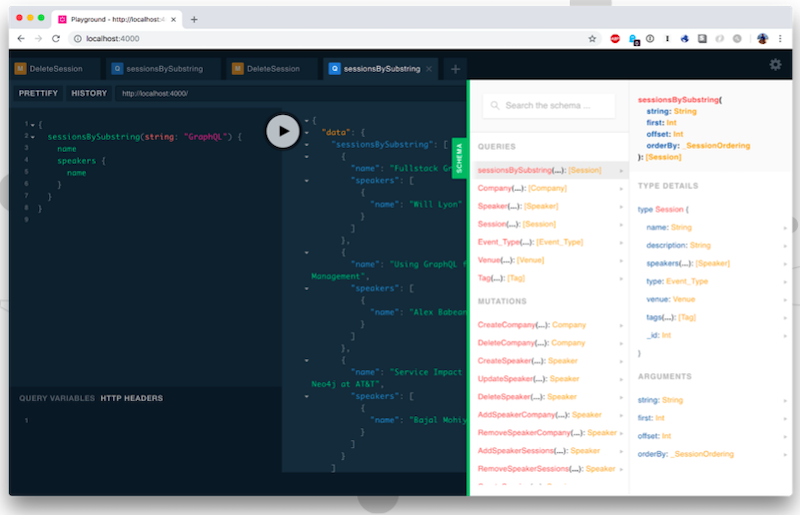
Yep. You see we have a speaker named Will Lyon. Will works for Neo4j and he has four sessions at GraphConnect. Now we know that our Cypher query works.
If we jump back to our ID here we see in debug mode the Cypher query that’s generated in the background here.
This is the Cypher query that’s generated from our GraphQL request.
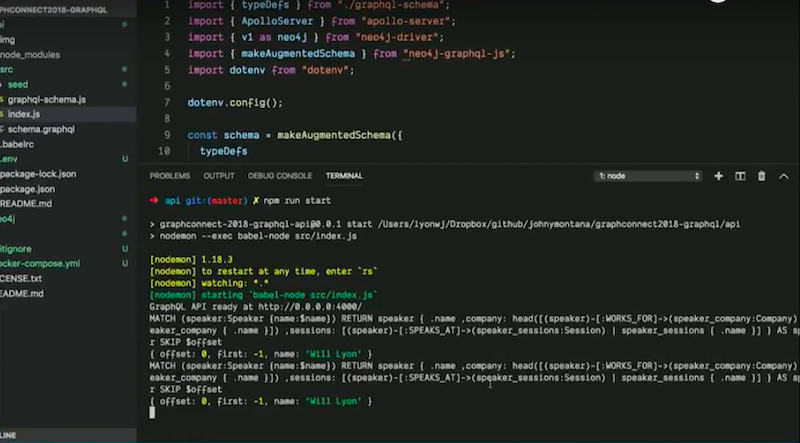
The query has done a match on speaker, looked up a name, and finally it does object comprehension to return results.
I want to point out this augment schema functionality.
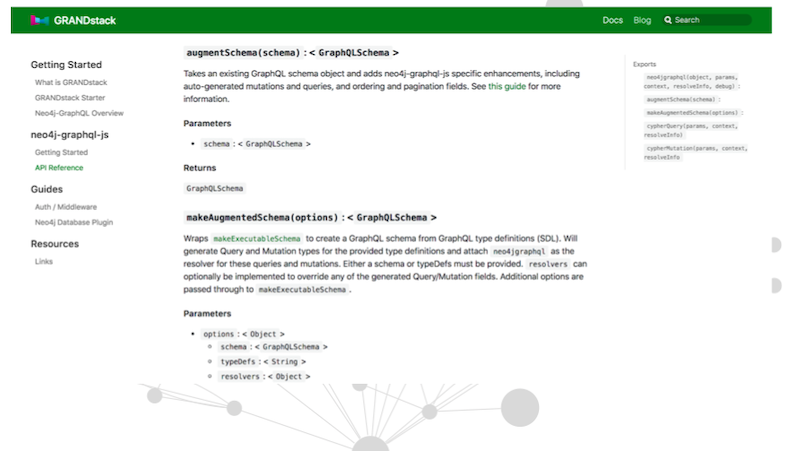
The augment schema functionality doesn’t seem like much. We’re getting a crud API generated for us. That doesn’t seem super impressive, but it’s really very convenient.
I spin up a GraphQL API just from my type definitions. If I want something beyond his basic crud, I do these @Cypher schema directives. It gives me the power of Cypher and GraphQL without writing any other code.
Then the nice thing about neo4j-graphql-js is that I then override any of those resolvers with any sort of custom logic that I want. I want to fetch data from another database. It’s really flexible. It also generates, again, all of the crud mutations as well.
GRANDstack
Neo4j GraphQL is part of what we call the GRANDstack. This is GraphQL, React, Apollo and Neo4j. This is the prescriptive set of tools for building modern applications.

We talked about GraphQL. React is a very popular JavaScript library for building UI’s. We talked about Apollo. Apollo has GraphQL tooling both on the client and the server. It really makes working with GraphQL easier.
This is the GRANDstack, and how it all fits together.
There’s a GRANDstack starter project that gives you a lot of the boilerplates, examples and abstracts using neo4j-graphql-js.
Apollo Client (for React)
I was going to talk a little bit about how the Client works.
We’ve talked about how we could spin up GraphQL API’s. We saw how to query them using GraphQL Playground. That’s the equivalent of querying something in Neo4j Browser.
This is the full-stack talk, so we want to know how we build applications with GraphQL.
Once we have a GraphQL endpoint, we query it using lots of different tools.
For example, I use that Community Neo4j Forum that I previously mentioned. That’s using the jQuery request. To make a GraphQL request, we didn’t really talk about this, there’s no transport layer specified as part of the GraphQL specification, but the convention is HTP. HTP post requests are available for read operations.
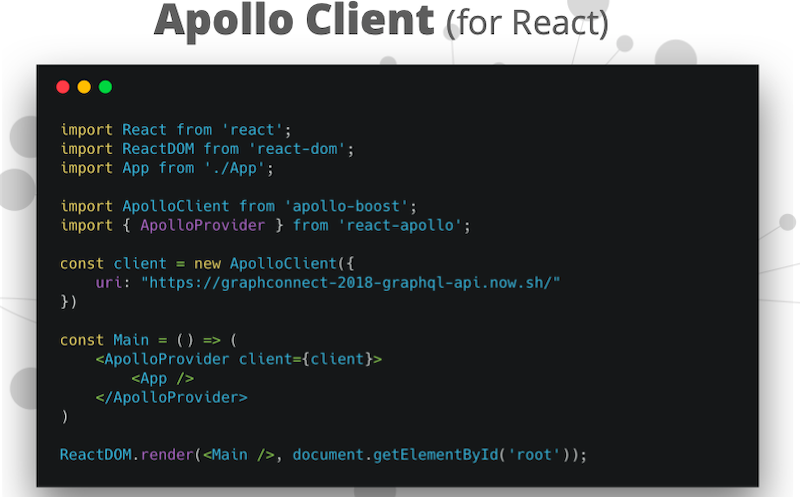
You are able to do post requests with jQuery, but you could also use tools like Apollo Client. Apollo Client has integrations with most of the very popular front-end frameworks. Here we’re using the React integration, which gives you a lot of cool functionality.
Here we are pulling in the React Apollo integration and we’re instantiating an Apollo Client instance.
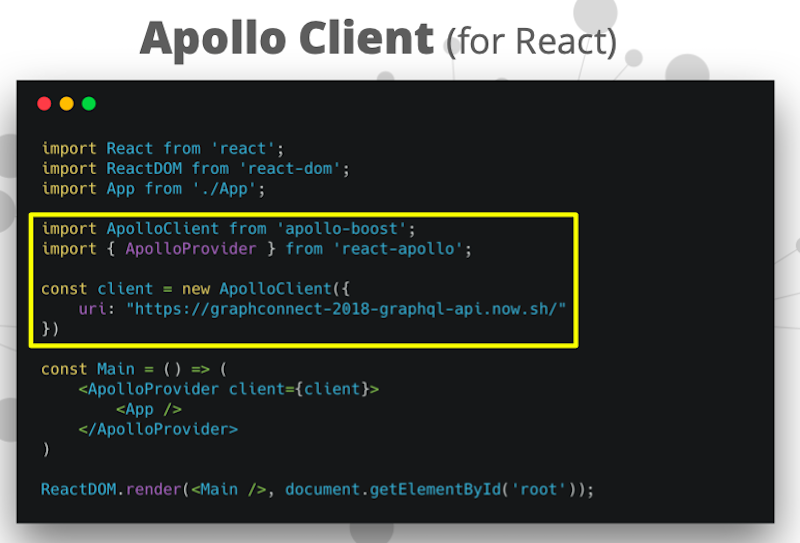
The Apollo Client instance is pointing to this GraphQL API endpoint. Then this gives us the ability to inject the Client into our React component hierarchy. This gives us a query component that we use to actually execute our GraphQL query.
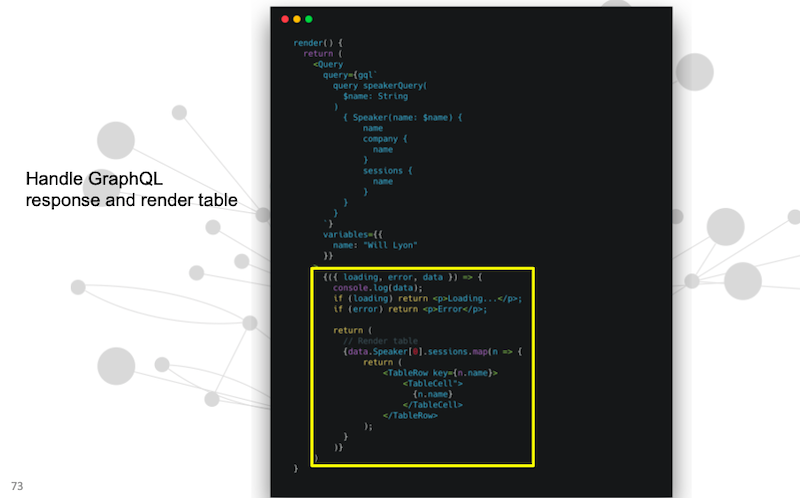
Here’s that speaker query:

Look for speaker by name, who they work for, what sessions do they have. Then we also have some handlers for when that data comes back.
Here we’re just mapping over the results to render a table that’s showing Will’s GraphConnect schedule.
GraphQL – Cypher Library In Other Languages
I want to talk a little bit about what we’re planning for updates to these integrations.
Currently, one of the things that a lot of folks have asked for are GraphQL to Cypher generation libraries in other languages. We have JavaScript. We have the JVM plugin but the logic for just generating Cypher queries is tightly coupled in the plugin. The next thing we want to do is extract out that logic to be able to give a Java library that users could use similar to neo4j-graphql-js.
I’m curious other languages that people want. If you’re building a GraphQL service with Neo4j what language are you doing it in? Let me know in the comments.
Click below to get your free copy of the Learning Neo4j ebook and catch up to speed with the world’s leading graph database technology.
Share Article


Explore
Related Articles



Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements

