


Journey Planning… And Why I Love Cypher

Developer Experience Engineer at Neo4j
7 min read
Editor’s Note: This presentation was given by Adam Cowley at GraphConnect Europe in May 2017.
Presentation Summary
Adam Cowley wanted to create a door-to-door journey-planning tool with Cypher that would allow him to accurately map a trip via train, bus, or both. He relied on open-source data from the UK government to compile both the locations and schedules of train and bus routes, data which he loaded into Neo4j via a simple LOAD CSV function.
By relying on single-directional relationships that took into account platform and service transfers, and the locations of stations and the traveler, he was able to develop a 200-line Cypher query that pulled data from a database of more than 50,000 nodes with 75,000 relationships, with results returned within two to five seconds.
Full Presentation: Journey Planning… And Why I Love Cypher
In this blog we’re going to discuss how to use Cypher to create a door-to-door journey-planning tool:
As a full-stack web developer and co-founder of Commit, a multi-disciplined development house, I’ve been using Neo4j for about three years now. We’re going to go through how I built a journey planner using Neo4j, the modeling decisions I made and the snippets of Cypher that helped me along the way.
Using Nodes to Map a Journey
Below is a picture of a roundabout in my hometown called “The Magic Roundabout:”

This roundabout is quite confusing to navigate, but it can be simplified through the use of a graph.
For example, by representing the junctions in the roads with nodes, connecting them with relationships, and creating properties against those relationships, we can easily determine how to navigate the roundabout:
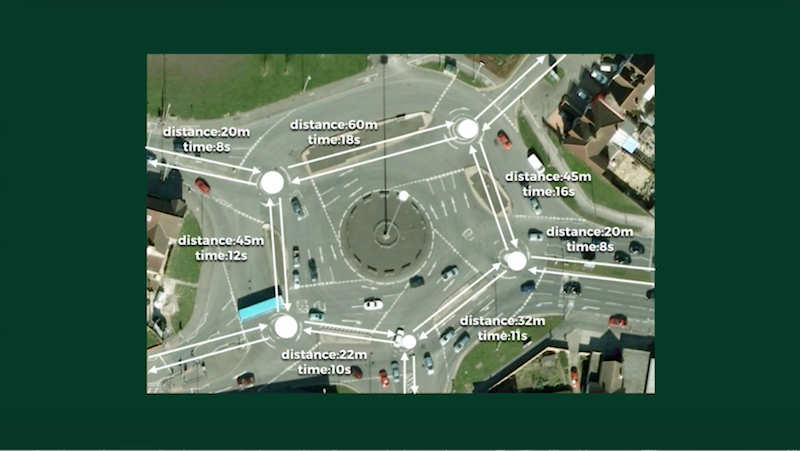
To determine the most efficient route, we can either use the shortest path in terms of number of traversals or by number of seconds. The approach I took to journey planning, in a more broad sense, is very similar, because I essentially just connected the dots between the origin and the destination.
Mining Open Data for Train Stations and Schedule
In researching potential data sources for our trip-planning data, I found a wide range of available information in the form of REST and streaming APIs, listed below:

I started by mapping train journeys, which required two key pieces of information: stations and schedules.
The government’s NaPTAN data set provides location data for all UK transport hubs in a CSV format, which can be easily loaded into our database using LOAD CSV. Network Rail provided our schedule information for all train operations across the country via a schedule API, as well as a real-time stream of train movements via a “Train Movements” API, both of which were in adjacent formats.
My first step was to create a model with train services that were connected to stations via a “CALLS_AT” relationship, each of which has an order:
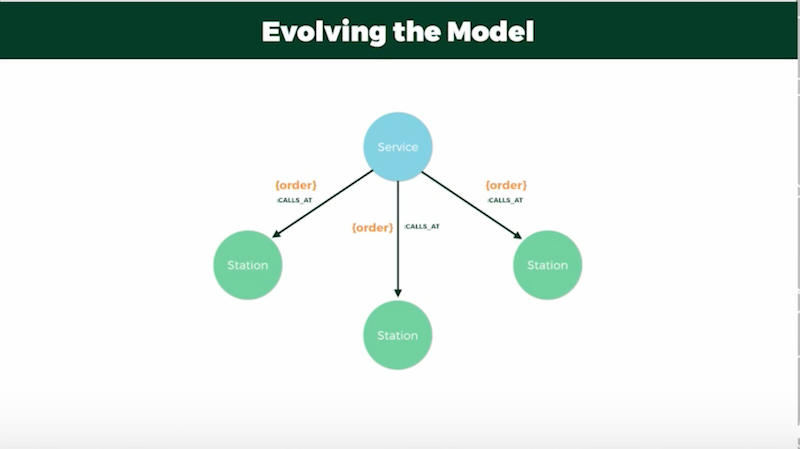
I found this model to be overly reliant on the order of our relationships, so it wasn’t flexible enough to provide the results for a query if the journey required more than one stop or change.
To combat this, I added a set of leg nodes to the graph:
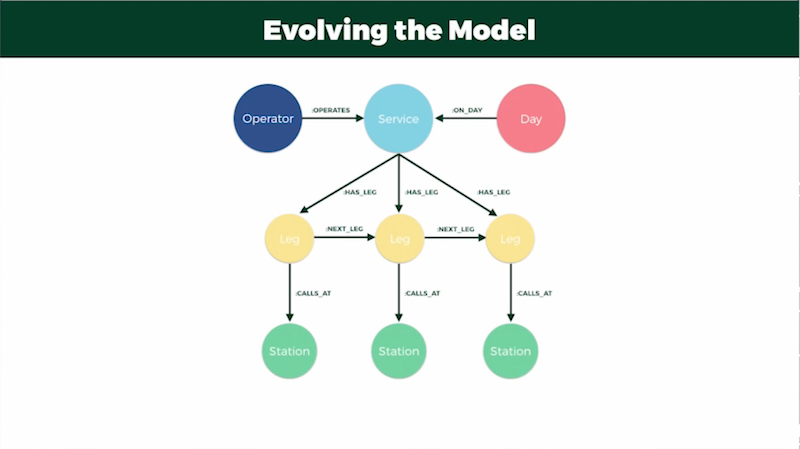
In this model, each service has one or more legs that call out a station.
Adding a next-leg relationship to create a links-list of legs meant I could take advantage of index-free adjacency and cut down on the number of indexes I needed to compare. Adding in relationships for both day and operator allowed me to reduce the number of node scans and index comparisons on those nodes once they were pulled out of the database.
Still, I found this model wasn’t accurate enough when we had to take into account changes between services – i.e. from one train to another – which required that I add platform data to the model:
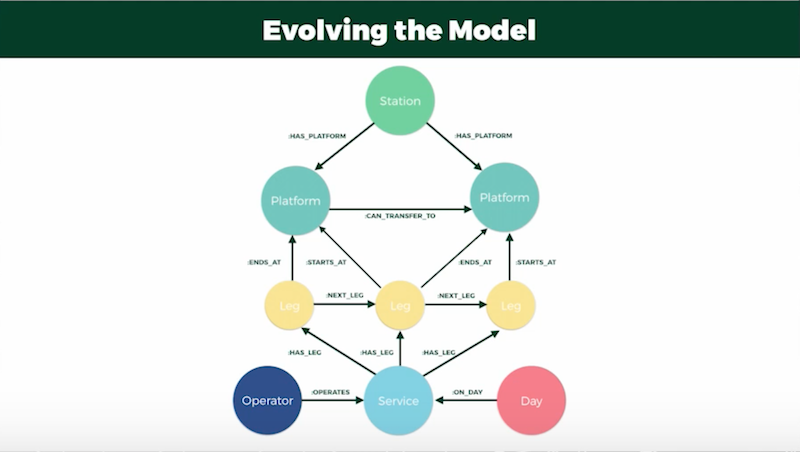
In the updated model, a leg would start and stop at “platform,” and whenever a traveler needed to transfer between platforms, I added a “can-transfer-to” relationship that included properties for both distance and time required for the transfer to ensure the traveler had enough time to make it to their train.
This is really easy in Cypher. All I had to do was create a “variable length” path, which allows you to traverse these different relationship types from the start point to the end point:

Luckily enough, the Cypher engine does this for you right out of the box, without requiring a background in computer science. I dread to think how complex this would be in a relational database.
However, even with this model, the query times were about 30 seconds, which just wasn’t performant enough. I needed to adjust my model to make it more efficient.
As I returned to the whiteboard, I had a bit of an epiphany: I could make the queries more efficient by ensuring all the relationships went in a single direction. By sorting out the “starts at” and “ends at” relationships with new “can-board” and “can-alight” relationships, I could traverse in a single direction and ignore a whole subset of queries:
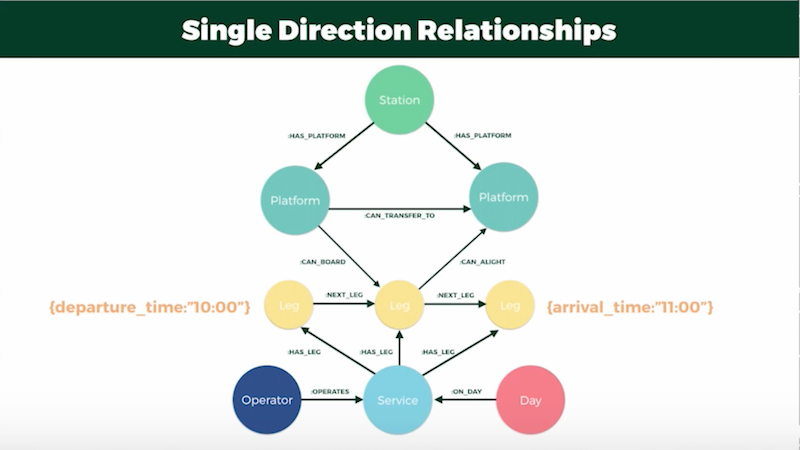
Journey Planning for Bus Routes
I realized this model also lent itself to bus services, the only difference being there’s no real overarching group for most of the bus stops. This meant each bus stop would have stand-alone properties with latitude and longitude labels stored against them. From there on, the model was identical:
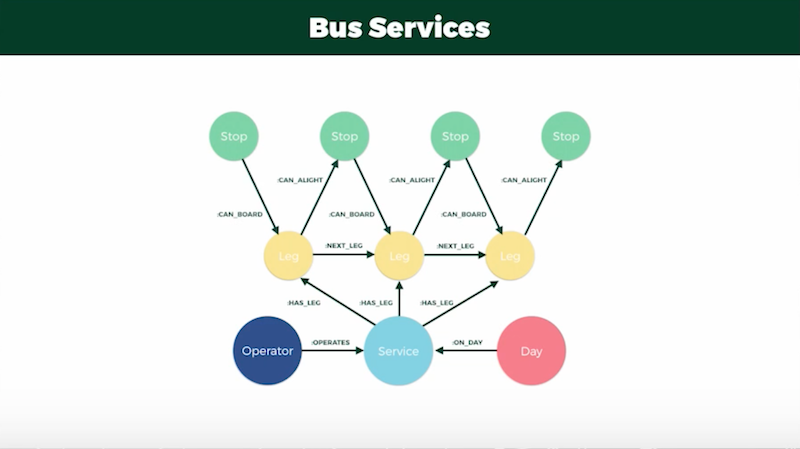
This led the a decision to add point labels to all of the stations and bus stops anywhere the graph traversal would start. Each point would contain latitude/longitude properties, which could be used to calculate the distance from the current user by relying on Neo4j’s built-in spatial functions:
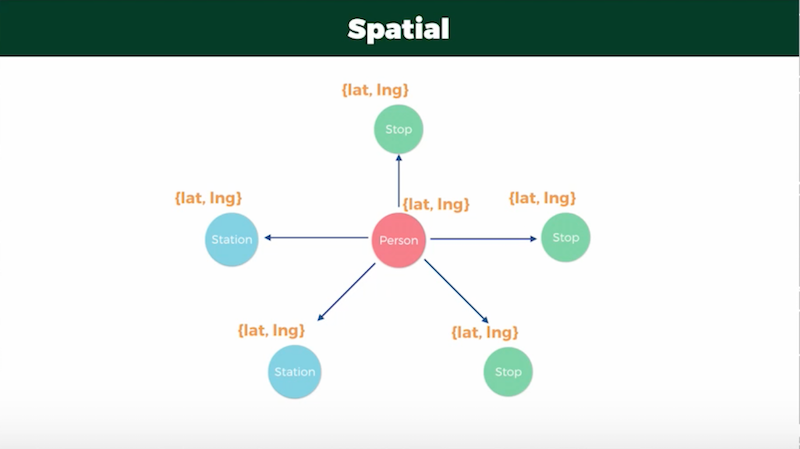
Here I’m using parameters to create a point to represent the user’s the starting position, finding all points in the database that have a latitude/longitude proxy set against them, and taking the closest stop to them to start the traversal:

But when considering switching between one or more service types, for example, from bus to train, there was a “can-travel-onwards-to” relationship created between stops and stations:
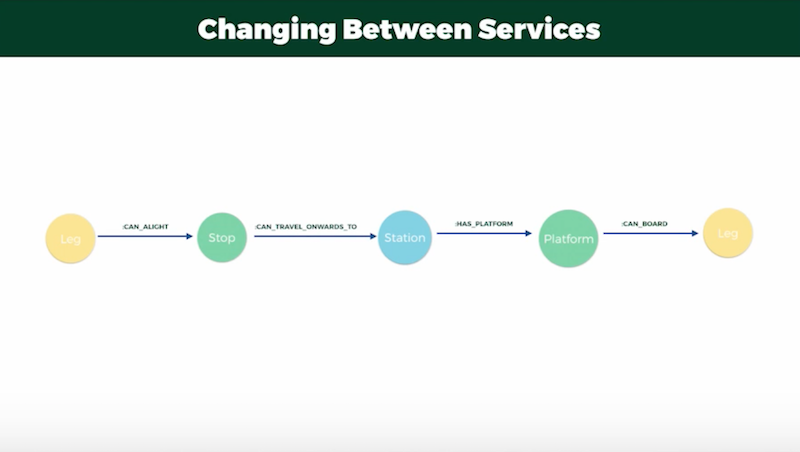
We created this in Cypher by finding all the stops within a reasonable distance of one another and creating a relationship between them with both a distance and time to transfer between the two:

The updated Cypher included the addition of extra relationship types and single-directional relationships:

Unfortunately, at this point, I was still having issues.
Even though this was a simple query to write, I was returning multiple different results that represented the same routes. Because I had defined the long string of relationships, I was getting patterns in which the result had a leg that goes to “next-leg,” then “Alights-to” stop, which folds back on the same leg and carries on:

To fix this, I started to dig down into the results and exclude anti-patterns.
It was at this point that I reached out to Michael Hunger and the Neo4j DevRel team. If you haven’t already done so, head over to Slack – it’s a great resource if you’re ever stuck [Editor’s note: Also, the Neo4j Community page is equally awesome for getting help.].
Below is my updated Cypher query:

Here I’m taking three adjacent nodes in a path with the pattern of leg, stop and leg, and then finding all the nodes where there’s a “next-leg” relationship between them, and using the “None” predicate to filter all of those out in the results.
The below query includes trips that require platform transfers:

With this query, I’m looking for platform transfers that include a leg, platform and platform transfer – and then comparing the arrival time plus the time it takes to transfer in minutes with the departure time. This ensures the user can catch the second leg of their trip, but won’t have to wait more than 30 minutes.
Neo4j made this all very easy, but I encountered an issue that came when I started to implement real-time data. As I had streams of data coming in near real-time, I couldn’t batch it into transactions or combine them. This led to quite a few deadlock areas that went right into the database, and the easiest way to get around these transient errors was to just simply try again.
Thanks to Neo4j and Cypher, this complex problem was solved with a single 200-line query on a sample data set of 50,000 nodes and 75,000 relationships, returning results between two and five seconds.
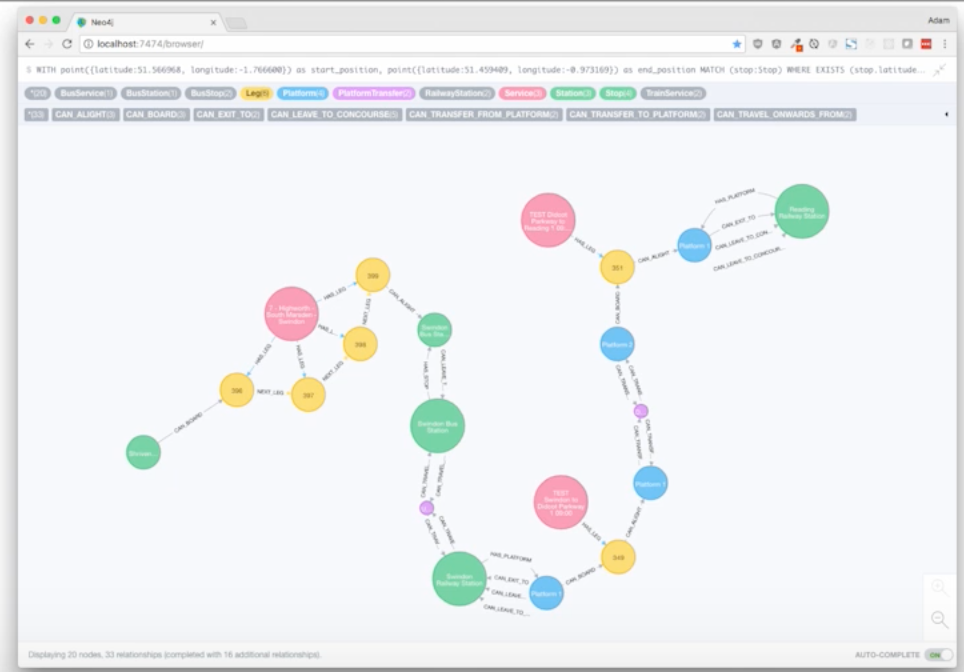
I planned the following trip using our new journey-planning tool, which shows a trip from my house – via bus and then train – to my destination:
Next Step: Java’s Traversal API for Production
To put this into production, I need to use Java’s Traversal API to stop any traversal that doesn’t match my parameters mid-flow. Unfortunately, I’m not a Java developer – but if there’s anyone out there who’d like to team up on this, I’m happy to have a conversation. You can find me on Twitter at @adamcowley and on Slack at @adamcowley.
Share Article


Explore
Related Articles



What Are the Best Graph Database Use Cases in 2025?

Neo4j Text2Cypher: Analyzing Model Struggles and Dataset Improvements
