Neo4j as an Embedded Database: Understanding Embedding and Graph Databases

Vice President, Product Marketing
4 min read

An embedded database is a database used inside another company’s application, providing added value and functionality. It enhances the functionality of the “host” application, usually without the end user realizing they are engaging with the embedded database.
In this blog series, we’ll discuss how Neo4j can be used as an embedded database. This week, we’ll begin from understanding embedding and graph databases.
The Modern Context: OEM and SaaS Basics
As SaaS applications become more dominant, the speed, ease, and flexibility of the embedded approach, i.e., adopting the OEM (original equipment manufacturer) model, becomes an even more compelling strategy for product developers to consider.
The practice, referred to as OEM, is rooted in the hardware market, where physical components are embedded inside a physical product that is shipped to the end user. The OEM is the company that is creating the product. Component suppliers provide their devices to the OEM to help create the product. But over time OEM has become a verb that means to embed.
As the idea has gained popularity in many contexts, the concept of OEM has evolved to be far more general and is used in many realms, not just hardware. One of the fastest growing categories of OEM is embedding software inside someone else’s software.
A cloud-based distribution and hosting model bypasses the OEM concept of “shipping” something physical. OEM in the software realm historically referred to the case where a company incorporates a software component into their installed application, usually as source code or a compiled library. The organization then distributed the application to end users as an entire package, generally as a set of binaries. In the modern SaaS model, the embedded software may also run as part of the cloud infrastructure hosting the application.
The OEM model enables organizations to minimize their investment in product development while shortening the product life cycle. By embedding someone else’s technology in a product, an organization can enhance its product without straying from its core competency.
Using an embedded graph database enables an organization to simplify the code in their product and deliver powerful features that wouldn’t be possible without a graph database.
What Is a Graph Database?
A graph database is a database designed to explicitly capture and store the relationships between data. It is intended to hold data without constricting it to a predefined model. A graph database stores connections alongside the data in the model, showing how each individual entity connects with or is related to others. (If you aren’t yet familiar with what a graph is, check out this blog post.)
A property graph database like Neo4j also stores properties, that is associated data, for nodes and relationships.
The Rapid Growth of the Graph Database Market
The interest in graph technology is rising rapidly. In parallel with the adoption of artificial intelligence (AI) and machine learning (ML), the data science community is turning to graph analytics to uncover hidden insights. Improving ML feature engineering and providing more explainable AI are just some of the uses driven by graph technology.
Graph databases are the fastest growing database category. The graph database market and the world’s understanding of the value of relationships have both grown significantly over the last few years. Graph databases form the foundation of many modern data and analytics capabilities, with more organizations adopting graph databases as the basis for their applications.
Gartner identified graph technology and techniques as one of the top 10 data and analytics technology trends to help organizations respond to the challenges and opportunities resulting from change and uncertainty in 2021 and beyond.
By 2025, graph technologies will be used in 80% of data and analytics innovations, up from 10% in 2021, facilitating rapid decision-making across the enterprise.” Gartner, Top Trends in Data and Analytics for 2021, 16 February, 2021.
Factors Fueling Graph Adoption
Graph technology is quickly emerging as a powerful tool to help the data and analytics community discover relationships, trends, and patterns across disparate and diverse combinations of data. Used in conjunction with graph algorithms and in-graph machine learning techniques, data scientists can find insights across deep relationships with mind-boggling speed.
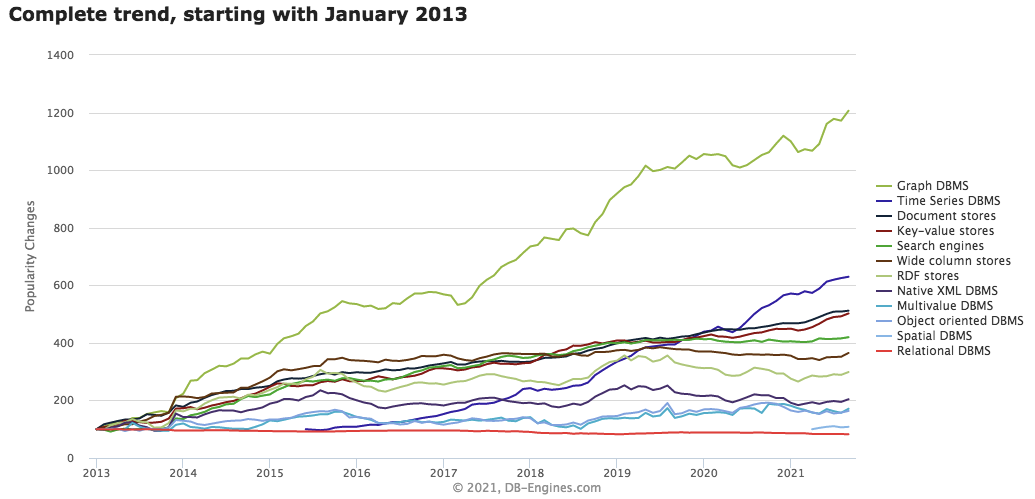
Graph database growth is spiking with market maturity and is creating an appetite for demand. The adoption of graph technology is accelerating due to several factors.
Speed. Critical business questions that used to take weeks to research can now be answered in minutes. Graph databases enable organizations to solve complex business problems that require contextual awareness and understanding of connections across organizations, people, and transactions faster.
AI maturity. Advanced data and analytics and AI capabilities are fueling graph database adoption. Graph capabilities underpin advanced data and analytics, ML models, and explainable AI. The use of graph techniques increases in line with AI maturity.
Ease of use. No-code and low-code tools enable visual exploration and interaction with a graph and allow critical insights to be found.
Cost. Scalability and lower cost processing through cloud-based services are accelerating the adoption of graph databases and graph analytics.
Standardization. Knowledge graphs expose metadata and business rules, enabling data scientists to quickly identify and use the data they need while preserving context and representing all forms of data in a standard queryable format.
Conclusion
By embedding a graph database in a product, organizations can take advantage of this rapidly growing technology and enjoy the benefits – speed, AI maturity, ease of use, cost, standardization – without straying from the core competency of the product.
In the second part of the blog series, we’ll go over the circumstances where embedding a graph database makes sense.
Want to learn more about embedded graph databases? Get this free white paper Neo4j Inside: A Guide to Neo4j as an Embedded Database now.
Get the White Paper
Get the White Paper
Share Article