


Neo4j Graph Database 3.4 GA Release: Everything You Need to Know

Chief Technology Officer, Neo4j
7 min read

Author’s note: What a hectic week in the world of Neo4j! In addition to finalizing the delivery of Neo4j 3.4, we simultaneously built the GQL Manifesto, a call to support a common, unified Graph Query Language. Thank you to the graph community for your strong vote of support! If you have not already voted, please do so.
The Neo4j graph database has always been the technology closest to the core of our mission: to help the world make sense of data.
With today’s general availability release of Neo4j Graph Database version 3.4, we believe that mission is advanced further than ever before.
The native graph database is the foundation around which the rest of the Neo4j Graph Platform is built, and we’re proud to be releasing this version that will delight both longstanding community developers and enterprise DBAs alike.
3.4 Features By Edition |
Community |
Enterprise |
|---|---|---|
| Data Types | ||
| Date/Time data type | ||
| 3D Geospatial data types | ||
| Performance Improvements | ||
| Native String Indexes – up to 5x faster writes | ||
| Fast Backups | 2x Faster | |
| Enterprise Cypher Runtime up to 70% faster | – | |
| 100B+ Bulk Importer | Resumable | |
| Enterprise Scaling & Administration | ||
| Multi-Clustering (partition of clusters) | – | |
| Automatic Cache Warming | – | |
| Rolling Upgrades | – | |
| Resumable Copy/restore cluster member | – | |
| New diagnostic metrics and support tools | – | |
| Property Blacklisting | – | |
Here is a closer look at the release-defining features of Neo4j Database 3.4:
Multi-Clustering
Multi-Clustering is the flagship feature of Neo4j Database 3.4, advancing the Graph Platform in scale, expanded uses and performance.
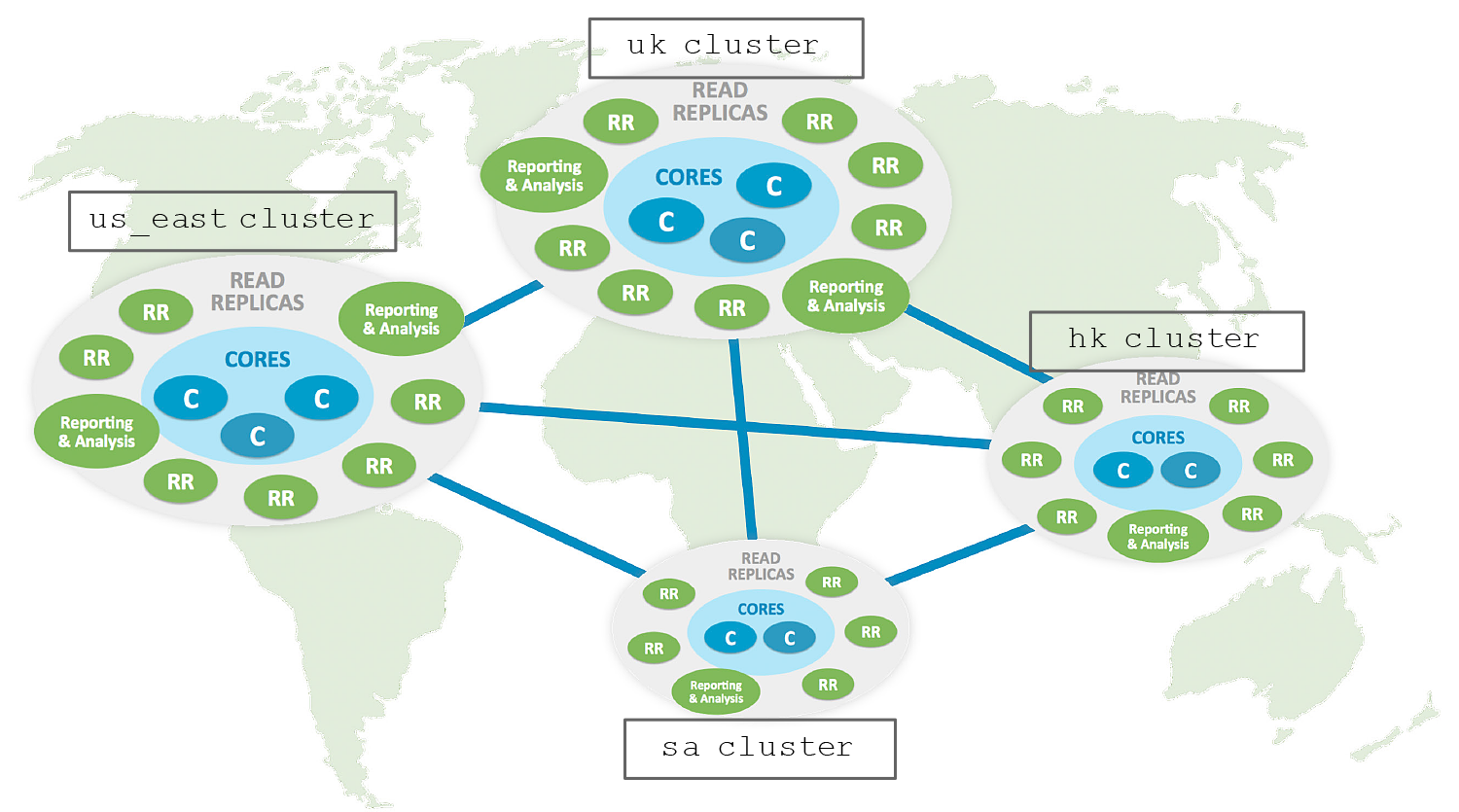
With Multi-Clustering, you can create and manage multiple domain-specific database clusters, effectively partitioning the graph into independent parts. We view this as a step in our march toward fully-sharded horizontal scaling of graph data.
Multi-Clustering can be used to logically partition graphs; create highly-available, large-scale multi-tenant SaaS systems; or oversee multiple graph implementations across the enterprise. For example, Multi-Clustering is perfect for building GDPR-compliant data lineage systems by country, or segmenting a graph database according to product line or division.
Directory Service
Multi-Clustering comes with a new directory service that manages a routing table of locations for each named database cluster. The directory service lives within lower levels of Bolt drivers at the same level as cluster load balancing and routing logic, all of which saves developers innumerable headaches.
Multi-Clustering Scalability Use Cases & Strategies
Here are just a few scalability use cases of Multi-Clustering we initially imagined (we’re sure you’ll surprise us with even more):
1. Physical Graph Partitioning
For the horizontal scaling of databases with logically distinct graphs, Multi-Clustering can be used to adopt a strategy of physical graph partitioning.
Physical graph partitioning might include naming and managing graphs according to geography (e.g., country), customer ID, products, use cases, versions, or data center as individual clustered instances. Or, you could use this approach for the creation and storage of multiple analytic graphs derived from graph-based analysis.
Physical graph partitioning is a cloud-friendly model, especially considering server-to-server encryption, multi-data center or zone support in conjunction with the above-mentioned strategies.
2. Cluster-Based Multi-Tenancy
Using Multi-Clustering for a cluster-based multi-tenant strategy allows you to define baseline schemas and data templates independent of a given tenant. You can also name graph data according to tenant ID and route it accordingly.
This strategy allows SaaS providers to deploy tenants as triplets of cloud instances that both separates individual customer data and provides high availability and customer-centric security – all without disturbing the top-level behavior and operation of the application or service.
3. Multi-Graph Operations within the Enterprise
Finally, Multi-Clustering can be used to combine oversight of use-specific graphs within an enterprise organization, such as metadata, GDPR compliance services, identity management, network topology management and Customer 360 experience data.
New Data Types
Neo4j Database introduces two brand-new data types: date/time data and three-dimensional geospatial data. These new data types enable optimized Cypher queries for searches across time or space.
Temporal Data in Neo4j
The introduction of date/time data expands graph-based thinking into other types of temporal (time-situated) logic and queries that matches modern research happening at leading universities across the globe. Temporal data is also important for Internet of Things (IoT) use cases, versioning and other changes-over-time implementations.
With the new date/time data types, you can more easily tap into a variety of use cases, such as:
- Time trees
- Change logs
- Temporal incentives (“Offer this coupon until this date.”)
- Complements to spatial queries (“Optimize route based on commute hour.”)
The new date/time data includes a variety of formats and conforms to a familiar SQL-like model.
3D Spatial Data in Neo4j
In addition to traditional latitude and longitude, the new geospatial data types in Neo4j also include Cartesian coordinates (x, y, z), radial distances, altitude, depth and slope.

Neo4j Database 3.4 now supports three-dimensional geospatial search as a data type and in Cypher queries.
These new data types greatly expand the types of searches and use cases for graph data, including location-based searches (“Find me a coffee shop within 100 meters”) and 3D routing requests (“Route the delivery to the 3rd floor”).
Another example: Using these new data formats, you could build a real-time bike-messenger delivery system that could not only locate addresses, but also specify time of delivery and elevation changes for the rider.
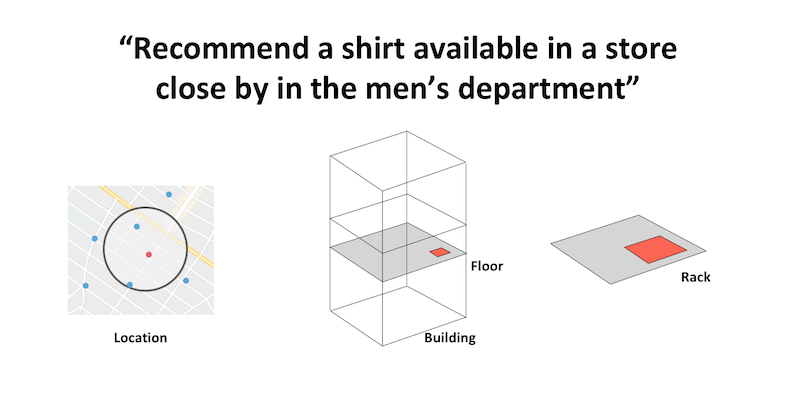
Another 3D geospatial search example: Recommend a shirt available in a multi-floor store close by in the men’s department. In Neo4j 3.4, Cypher queries now support the data types necessary to complete such searches and recommendations.
Performance Improvements
Neo4j 3.4 is faster in terms of both reads and writes, and these overall performance improvements are proportionally reflected in both Community and Enterprise Editions (with some differences).
The 3.4 release removes multiple layers of APIs between the kernel, interpreters and compilers, producing impressive performance improvements that other graph-layered products will find challenging to reproduce.
Blazing-Fast Writes
- Writes are now up to 5x faster for nodes with indexed string properties, thanks to native string indexes and lessening dependence on third-party libraries.
- A new kernel API streamlines internal instructions.
- Bulk imports can handle over a 100 billion nodes and relationships.
- Transaction states consume less memory thanks to various efficiency improvements (including native indexing) working together.
Writes with Native String Indexes

Writes are now up to 5x faster for nodes with indexed string properties, thanks to native string indexes. This reduces Neo4j’s dependency on the popular external indexing library Lucene, and gives Neo4j finer-grained control over index response times.
Speedy Reads
- Internal testing shows that Cypher runtime is 20% faster than for Neo4j 3.3 Community Edition and Cypher runtime is 50-70% faster than Neo4j 3.3 Enterprise Edition.
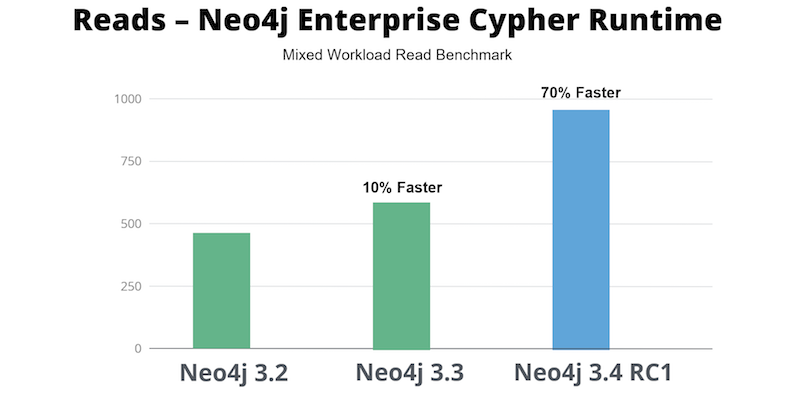
Internal testing shows that Cypher runtime is 50-70% faster in Neo4j 3.4 Enterprise Edition than in Neo4j 3.3 Enterprise Edition.
New Administrator Features
Database administrators, DevOps and other support staff have had an important voice in strengthening Neo4j both in the past and in the 3.4 release. Some of the key highlights include:
- Hot backups are now twice as fast as in previous releases.
- After restart or restore, active cache warming now automatically warms the page cache to its previous operational state, getting servers back online in record time. This active warm-up exercise also cascades to Read Replicas within that Causal Cluster. The effect is that applications enjoy the peak operational responsiveness – immediately.
- A new diagnostic utility (dump tool) improves the speed and accuracy of collaboration support cases between customers and Neo4j Support.
Cluster Member Management
- Data store copy and catch-up features to enable a new empty instance to join a cluster and become operational in no time. This feature adds full transaction history as well as bulk-load historic data and transaction leftovers.
- Catch-up functions can be stopped and resumed, and also include ongoing raft log updates to complete making a new instance fully armed and operational.
Rolling Upgrades
- Rolling upgrades allow for updating older instances while keeping other members stable and without requiring a restart of the environment.
- All new patch, minor and major versions will support rolling upgrades starting from Neo4j 3.4.
- Rolling upgrades will operate with both read-only and read/write instances.

Neo4j 3.4 now supports rolling upgrades so you can update older instances while keeping other members stable and without requiring a restart of the environment.
Database Security Advancements
As with past releases, the Neo4j Database 3.4 release continues to robustly uphold modern database security principles, often not available in competing graph stores or other NoSQL databases.
Our current database security features include:
- User- and role-based security within the database
- LDAP and AD directory integration
- Kerberos authentication (ticket-based)
- HTTPS access to all user-facing interfaces
- TLS encrypted traffic among cluster routing, cluster members, including through Bolt application drivers and across data centers
- Encrypted data at rest via file-system encryption
With Neo4j 3.4, administrators can now implement property blacklisting by name or role, securing property visibility. This feature is similar to SQL-centric column level security without impacting performance.

With Neo4j 3.4, administrators can now implement property security by name, blacklisting properties for users.
Conclusion
As the core of the Neo4j Graph Platform, this 3.4 release of the Neo4j Graph Database indicates an upgrade for the entire platform that relies on it. We’re confident that the upgrades in Neo4j 3.4 will deliver stunning spillover results into all of the new products and features of the Graph Platform as they roll out later this year.

Neo4j Database 3.4 is just one of many recent or soon-to-be-released upgrades to the Neo4j Graph Platform.
We encourage you to download Neo4j Database 3.4 and try it out for yourself – whether as part of Neo4j Desktop or as part of your Enterprise Edition license.
While we know some of the most clear and obvious ways that this release will help you harness your data connections, we’re even more excited to hear how our millions of users worldwide will use these new features to build applications beyond the limits of our wildest imagination.
For all of the Neo4j team,
Download Neo4j Desktop right now and see for yourself what you can do with the leading platform for connected data.
Share Article


Explore
Related Articles


Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces


