

Introducing Neo4j Graph Database 4.0 [GA Release]

Chief Scientist, Neo4j
8 min read

I feel particularly pleased to be able to announce the GA release of Neo4j Graph Database 4.0.
I’ve been with the Neo4j codebase since 2009 and have to tell you: 2009 Jim Webber couldn’t imagine the way 2020 Neo4j would look. “2009 me” was building a REST API (if you’ve ever seen such a thing) so that the database could become a server. Now I look at 2020 Neo4j, and it’s an incredible leap forward that is astonishing to me.
Neo4j 4.0 is the culmination of more than a year’s worth of our work, from the biggest engineering team ever invested in graph technology. To put that in more developer-friendly terms, we’ve invested around a century’s worth of human effort into this release.
Those of you who know me, I’m not usually at a loss for words. But when I look at the amount of software that’s been carefully and conscientiously developed, when I look at the amount of time we have spent harming the database and watching it recover – because we value your data – it beggars belief.
So what’s new in Neo4j 4.0?
Literally thousands of things happened over the course of the last year. But ultimately, this release boils down into four fundamental pillars:
- We now have Neo4j Reactive Architecture, so the database is very responsive, elastic and robust.
- We have extended Neo4j into a multi-database world so that you’re able to run multiple databases online in your cluster or server concurrently.
- We have a brand new feature called Neo4j Fabric, which allows us to do distributed queries over multi-databases.
- And because I know every developer loves security, we now have an interesting and innovative schema-based security model.
Let’s dig into each new feature a bit deeper.
Reactive Architecture Across the Whole Stack
The Neo4j 4.0 release takes a big step forward in terms of making Neo4j reactive. We’ve designed Neo4j to be a very responsive database, a database that’s elastic, a database that’s robust.
Many of these things have already been in the products. Neo4j is responsive. It’s the fastest graph database on the market. Trust me, I’ve benchmarked several others – Neo4j is ridiculously quick. Neo4j is elastic. You can scale clusters up and down. Neo4j is resilient. If you decide to crash instances of Neo4j, they will recover. If you crash instances in a cluster, the cluster will continue running. And I have crashed enough of these clusters myself to know that they are bulletproof.
But the one thing we didn’t quite have was in the Reactive Manifesto, the notion of being more message-oriented, more message-centric. In Neo4j 4.0, we’ve done this. In fact, we have introduced a set of technology called Reactive Architecture.
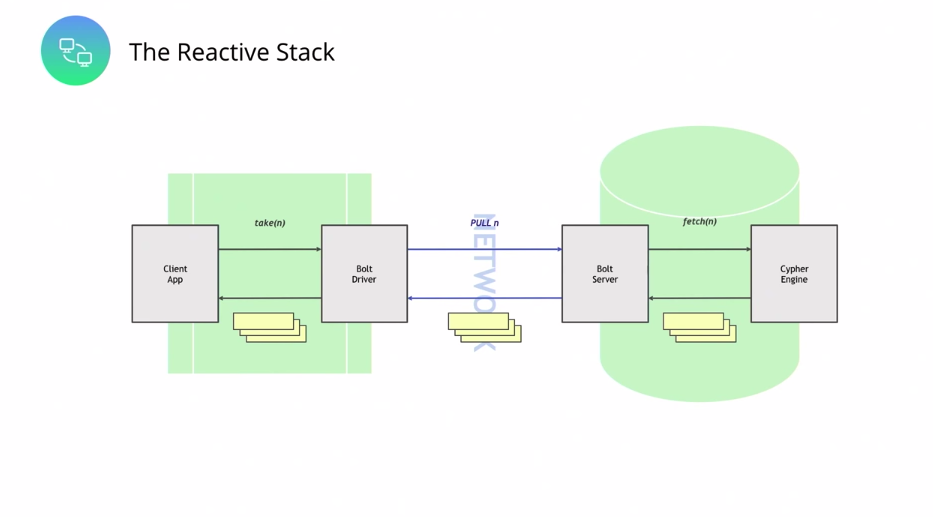
As a client developer of Neo4j, you now have the ability to take control over the whole stack in terms of resource usage. A client application fully controls the flow of records, which a server or cluster produces, so there’s no longer a tsunami of records flowing back. Now we have control flow that goes all the way through the stack, whether it’s synchronous or asynchronous execution. This is based on reactive streams with a non-blocking, back-pressure library, and it’s exposed through the reactive API in version 4.0 of the Drivers.
In terms of the stack, we have a new infrastructure for this. So the client uses what’s called a reactive session in the Drivers codebase, and this is bound to a producer via a flow API in JDK9 onwards, or the equivalent in your programming language. And then you can plumb that into whichever reactive framework you’re most comfortable with. But what’s critical is that at every part in this journey, every part of this architecture, the client can choose to pull more records through or gracefully terminate when sufficient data has reached the client. This is a much cleaner experience for a developer.
In Java, we’re already nicely integrated this way into Spring Data, and therefore into Spring Boot. So if you’re a Java developer, this stuff feels very natural to you. (Big thanks to Gerrit, Michael, Nigel and Zhen for doing all of this work.) The developer experience out of the box is just lovely.

If we just take a slight peek back in time to Neo4j 3.x, here’s some Java code talking to a Neo4j 3.x instance, this all kinda looks okay, right? So I’ve got a very simple query, which is to get me all the people from the database, and I start a session with the driver and I get a statement result back. And then I’m gonna iterate over that result doing next, next, next, and every record that I get, I’m gonna get a property out of it and I’m gonna look for a name.
And this all looks fine. All we’re doing is printing out these names until we get to Emil Eifrem, and then we’re stopping. And, if you read the code, you’d be like, “Yeah this is fine, everything’s fine here.” Except no, syntactically it looks fine, but under the covers there is no way for this break to signal back to the server to stop producing results. In fact, the server will continue to produce results, they will continue to be flowed across the network and into the client, which can be problematic.
The only way really out of this is to kill the connection to the server and then rebind, which is a bit, bit harsh.

In 4.0, the experience is way, way nicer. So in this case, same query, we’re gonna look for, not very graphy, but we’re going to pull all of the people out of the database. And then, using Flux in this case, we are going to create a reactive session, and we are gonna pull these records from the server to the client at the rate that we can deal with.
So in this case, we’re limiting rate to 10. That means that we’re pulling, in this case, 10 records from the network at any time. We’re gonna then map, and we’re again extracting the name out of that stream, and we’re gonna continue to do this until we find Emil Eifrem as the name in that record. Then we’re going to stop. And what we’re going to do here, unlike in the previous example, is the server’s also going to know to stop. So it’s not going to continue executing that query and sending data back to you, it’s gonna gracefully stop, as well.
Across the whole stack, the execution of resources is governed by the rate at which the client can process, which is really neat. It means you get optimal use of resources, the client gets an optimal experience, and no longer are we storing up big buffers and sending tsunamis of data over the wire. This is a very mechanically-sympathetic model. We’re not prescriptive about which reactive framework you use – bring your favorite one; we’re pluggable, bring it along, get coding.
A Bright New Multi-Database World
Working my way in through our tech stack, the next thing that I’m just genuinely thrilled about is that we have moved Neo4j into a multi-database world.
With Neo4j 3.x, we were able to host multiple databases per server, but only have one live database at any given time. And you may have done this by rebooting the server or using Neo4j Desktop or other scripts at your disposal. It’s convenient, but it doesn’t quite compare to the idea of multiple live databases. In fact, in Neo4j 4.0 with multi-database, we have multiple live databases per cluster with strong isolation. So the databases are physically separate despite the fact they execute on the same cluster of servers.
Say you’ve got B2B Software as a Service, so you’re delivering software to your end-users and you want to be able to keep their data separate. With Neo4j 4.0, you can now create on a single cluster a database per customer of yours. You could implement multi-tenancy, so a single Neo4j cluster may serve multiple users within an organization. You can also do things like conveniently use the infrastructure to have your test instances versus your dev instances. You can also decide to use the aggregate throughput of this stuff to scale out. Or indeed, it’s very cloud-friendly, so you could choose to bring up machines, bind and rebind them to storage under the cup.
So we’ve taken, I think, quite a great leap forward from Neo4j 3.x, where you could, with some effort, bring up multiple databases if you dockerize them, or you took care to remap ports and so on in the config. But none of this really gave you a pleasant ops experience; as a developer, you’re always kind of scrabbling around to make sure you got the right database at the right time on the right ports.
Conversely, if you’ve tried to deal with this model in the database, if you’ve tried to create multiple databases by convention, using labels and relationship types and so forth, the isolation there is relatively weak.
That’s completely changed in 4.0, where if you create a database in a cluster of Neo4j, it’s physically separate from the other databases. That physical separation holds true not only for the data files that hold the database data, but also across the internals of the database, such as logs. Many of you will know that we have a log-oriented protocol called Raft that does dependable, reliable replication for Neo4j and it’s an individual replication, instance of the replication algorithm per database. So this stuff is strongly isolated.

Now, because all of your databases are live in the cluster, the system database understands – and is itself, by the way, replicated around the cluster – so you get a universal view of your data. To administer it, you’ve got commands that seem humane and sensible to you. You can create, drop, start and stop databases. You can address them through HTTP, you can address them through the Cypher Shell, and in drivers, you can just create a session to a named database.
In fact, those sessions from a driver are super lightweight, so there’s nothing really to stop you from using multiple sessions to talk to multiple databases cheaply. It just works.
Neo4j Fabric: Distributed Runtime for Horizontal Scalability
This notion of a single application talking to multiple databases nicely brings me to another brand-new feature in Neo4j 4.0. A piece of kit that we call Neo4j Fabric.
Neo4j Fabric provides multi-database distributed queries. Effectively, you write Cypher code and Fabric figures out how to transmit the query around the network – it targets your databases and executes them in parallel, and collects the results for you.

The contract is really straightforward – we’re trying to take the hard stuff away from you. As a developer, you model and store graphs in individual Neo4j databases as per your business need, just as you do today. What do we do? Well, Neo4j Fabric distributes and parallelizes queries and aggregations over those databases and combines the results together. It’s that simple.
So if you have many databases, you have multiple databases that support your business in this world, and run queries across them very conveniently, very humanely.
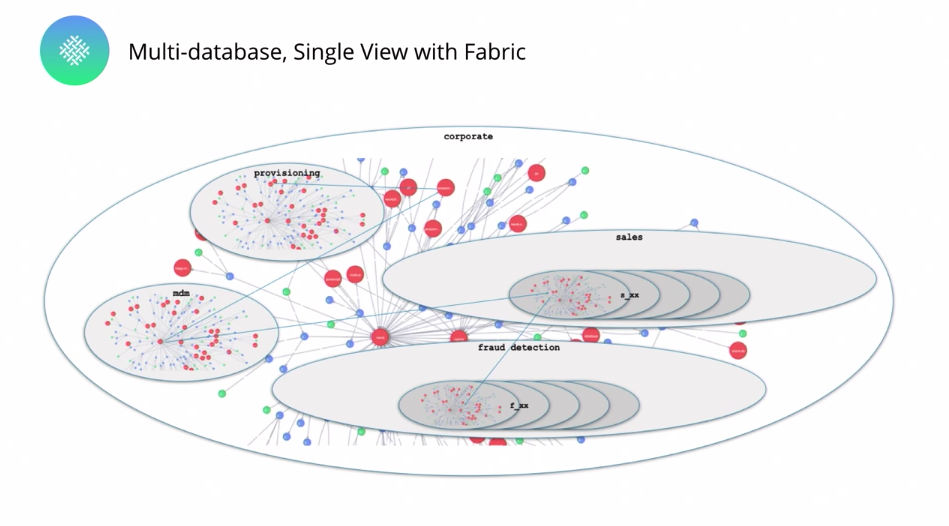
For example, if you want to report on levels of unpaid invoices for certain products in certain geographies – and that happens to span multiple databases – Neo4j Fabric helps you do that.
Below is a very simple example, although it comes from a real live Neo4j customer (hi, you know who you are). In this case, we are trying to get the top 10 users by photo count, so it’s a photo website, a photo app, and we want to know who’s photographing the most. The dataset is very large, but the model is trivial. I’ve got users, their own photos – so I’ve got photos that belong to users.

And what we’re doing here is a very simple aggregation example. We’ve got photographs and users spread around multiple database instances, depending on their geography. So I’ve got a multi-database for geography split like that. And now this query is going to aggregate across all of those databases giving me some results.
So what’s happening here?
We’re saying CALL, and that’s allowing us to dispatch out a query to those databases. Inside that database, we’re then gonna find photos for users and we’re going to return them. And then the last part, the return, the aggregation stuff, is going to take all of those responses from all of those multiple country databases and order them by photo counts, by the number of photos per user, and return. Join or otherwise get all excitable about parallel and distributed computing.
Don’t get me wrong, I have a PhD in parallel computing – I’m excitable about it. But that shouldn’t be your problem. If you want to attain my level of hair loss, then get involved in it. If you want to maintain your good looks, this is zero-stress parallel distributed computing in friendly Cypher query language that everyone knows and loves. It’s actually really, really cute. Like, you can feel empowered by this rather than baffled. Leave the bafflement to me, I’ve got the face for it.
One other thing I really like about Fabric is that it’s non-invasive – the Neo4j clusters that you’re running to support your business continue to run. They’re blissfully unaware of the distributed queries run over them by Fabric, because the Fabric Runtime sits outside of the Neo4j cluster.
Neo4j Fabric is, itself, a fully-fledged Neo4j instance, by the way. But from the point of view of your clusters, it’s just another client sending queries to be evaluated, collecting up the results, doing some aggregation work and passing them back to the user.
So under the covers, there’s a bunch of clever stuff going on, but you don’t have to worry about this technology being complex to deploy or invasive to your existing line of business systems. Plug existing business systems in and then Fabric does the aggregation work for you.
Security That’s Sympathetic to Structure and Property
Look, don’t tune out – this is good.
I know we’re developers, and unless you’re that particular brand of developer that can factor prime numbers in their head, security stuff is a bit challenging.
We’ve had a long time to think about what security means for a graph database. And I believe we’ve developed something you’re actually going to like in terms of security, which is an unusual and rather wonderful thing to say.

If we look back at Neo4j 3.x, I think very fondly of this release as the version in which Neo4j “grew up” and became enterprise strength – particularly around those things we did to secure the database. Everything was encrypted on the wire, we had users and roles, you could plug into directory services, we enabled you to blacklist properties so certain properties couldn’t be read by certain users or roles, we had Kerberos, we had security event logging, we put access controls around calling procedures, and all of the back-end stuff in Neo4j clustering was encrypted, as well as standard things like encryption-at-rest through Vormetric.
All of this made Neo4j good enough to be enterprise ready. And we see this, right? So many of you now deploy Neo4j in your businesses because you trust it from a security point of view. But very little of this speaks to graph technology. You could take the same set of icons and you could say oh, well this is a relational database or this would work for a key-value store.
So what is it that we’ve done for graphs?

We’ve taken a step back and thought: Relational databases have things like row-level security – it’s not very meaningful in graphs. What is meaningful in graphs?
Well, graphs have structure and data. So we need a security system that’s sympathetic to that. What we came up with is a role-based access control approach, which is permission on entities for user, where we grant access for database, and then we have very granular commands around GRANT/DENY and REVOKE, targeted at any level of granularity – from graph, node, relationship, property, all the way through the database and cascading downwards.
What I’m particularly proud about is that we’ve thought about graphs and structure, and we’ve got facilities in our schema-based security that deal with that structure.
I’ve gotta live up to my job title as Chief Scientist, so I’m gonna bring up a famous scientific paper. Fakhraei et al. in KDD 2015, they did an ML analysis on a graph structure, looking for spam in a network. And without looking at any of the content of messages, only looking at the transmission graph, they were able to identify, with very high confidence, which messages were spam and which messages were not.
What does that mean? It means that inside a graph, the structure, the relationships and nodes themselves, are information even before you get down to the properties. And so our security system takes that into account.

To drive that home, we have a very simple example of data privacy. It’s a fictitious example, but hopefully, as a learning exercise, this will make sense to you.
So, patient records visibility: Above is a meta graph, a schema, and what we have here are a patient who has a diagnosis, a doctor who’s established that diagnosis, the diagnosis is for a particular disease or condition, and we see that a patient can call into a call center. And the snippet of the real graph you can see below.

I’ve got a couple of patients who’ve called our call center. Those patients have diagnoses of diseases that have been given to them by various doctors. I have a constraint, which is that the call center agent needs the doctor details, but isn’t privileged to read the diagnosis. In the first schema, you can see that in between patients and doctors, there are indeed diagnoses.
So what do we do? Well, now we have this really lovely, granular way of specifying security.

So in this case, this is some security config for Neo4j 4.0, we’re gonna create a role_agent, and we’re gonna grant the ability to match, and matches are to traverse and read on all graphs for all elements to role_agent. But then we’re going to deny read access on all graphs all elements to role_agent, but we’re going to grant a traverse on all graphs, all elements to role_agent and grant read permissions to Doctor {name}, CallcenterAgent {name}.
Here traverse is the coolness, because traverse says you can go across a relationship or visit a node, but you are not necessarily given permission to read that structure or the data therein. Great, because it prevents leakage of information through structure on the one hand; and on the other hand, it preserves correctness of queries because you can traverse the graph in its completeness to get the correct answer, without revealing or leaking data from structure or properties.

If we now run this simple Cypher query above, we’re asking the database for CallcenterAgent Alice, which a patient has called, which has a particular diagnosis established by a doctor. We will get answers back for the patient’s name and the doctor’s name, but we will not be able to get any answers back for the diagnosis name. And structurally, you can see that.
What our rules do is they proscribe rather than prescribe (because that’s the doctor’s job), against going across the diseased relationships and the diseased nodes.
One More Thing
There’s one more thing you should know about Neo4j 4.0.
This is a very big release. Lots of internal APIs have changed, which means that if you’re running Neo4j and using procedures, unmanaged extensions, plugins or embedded mode, there’s some work to be done to adapt to the low-level changes. (A post on this will be forthcoming.)
To that end, I want to share which of Neo4j’s own products already support Neo4j 4.0 and which ones are still a work in progress. I’ve included the breakdown below.
Ready today and fully support Neo4j 4.0:
- Drivers for Java, .NET, JavaScript and Spring Data Neo4j
- Neo4j Desktop
- Neo4j Browser
- The APOC library
- GRANDstack
- Halin monitoring tool for Neo4j
Still in progress and don’t yet support Neo4j 4.0 capabilities:
- Drivers for Python [expected in Q2] and Go [expected in Q4]
- Neo4j Bloom [expected in Q2]
- Neo4j AuraDB [expected in Q2]
- Apache Kafka integration
- Neo4j ETL tool
Conclusion
To recap: The new reactive data architecture allows you to build faster. For unlimited scaling, there’s a multi-database and sharding through Neo4j Fabric. And we have schema-based security.
With Neo4j 4.0 you can build faster, scale bigger, be more secure, and essentially launch easier. We heard the call for these features loudly and clearly from the real-world users of Neo4j.
Likewise, there are other Neo4j highlights that we didn’t get into here, and you can find more information in our official release notes.
Get your hands on it, play with it. We love to hear your feedback. Tell us what you like, tell us what you need to change – we’re always ready to listen.
I hope Neo4j 4.0 is an astonishing release for you. It’s been an absolute blast building these features for you, and in turn, we can’t wait to see what you build with it.
Share Article



Explore
Related Articles


Reflections on the 2025 Gartner® Cloud DBMS Magic Quadrant™ and the Future of AI-Ready Data


