Neo4j on Mesosphere DC/OS


9 min read

Don’t miss Johannes present on scaling out Neo4j using Apache Mesos and DC/OS at the next Neo4j Online Meetup!
(dcos)-[:MANAGES]->(instance)<-[:RUNS_ON]-(neo4j)
The same day that Neo4j 3.1 was released in December 2016 it also became available as a Mesosphere Universe package. This is the story behind that joint effort which also explains the why and how.
Johannes is a long-time Neo4j user and community contributor who recently joined Mesosphere in Hamburg. To make Neo4j’s scalability available to more users, he and Michael devised a plan to publish the database as a package to be run on the versatile cloud operating system DC/OS utilizing its Marathon scheduler. With the release of the new Causal Clustering architecture as part of Neo4j 3.1 this became a breeze.
Instead of having to write a custom scheduler, all it needed was a little bit of config, and a slight variant of Neo4j’s official Docker image. The rest is history.
Our big thanks goes to Johannes working out how to put the pieces together and creating the configuration, package and surrounding material.
If you already know Marathon and Neo4j, you can install and scale the package(s) with the following CLI commands or the universe UI:
dcos package install neo4j dcos package install neo4j-replica dcos package install neo4j-proxy

Neo4j Clusters
The release of Neo4j 3.1 introduced a new, scalable clustering infrastructure called Causal Clustering.

It consists of two types of cluster members:
- Core Servers that accept quorum writes via a consensus commit protocol
- Any number of Read Replicas that serve read requests
The core servers implement the Raft consensus algorithm for cluster membership, leadership election, and agreement on successful commits after a quorum write.
Read replicas can be used to scale out reads or as reporting and/or analysis instances.
This version of Neo4j is available for download in multiple formats including an official Docker image.
DC/OS & Marathon
DC/OS is an open source platform enabling users to easily deploy and orchestrate applications across large clusters and keep them available despite task, node or network failures. DC/OS provides typical operating system features as a UI, init system, cron scheduling, and security and hence enables users to treat their entire data center as a single computer.
DC/OS is built around the long established Apache Mesos project. Mesos is used by companies such as Twitter, Netflix and Airbnb to manage their cluster having several 10000 nodes. Mesos itself is very flexible and allows scheduler running on top to make the application-specific scheduling decisions.
Marathon is one of those most-used schedulers running on top of Mesos. Marathon supports containerized applications, but its main purpose is to support long-running services–both containerized and non-containerized. Hence Marathon is actually used as the init system for most other services on DC/OS.
In order to make it as simple as possible to install those additional services, DC/OS brings along its own app store, the universe which allows you to install distributed services such as Apache Spark, Apache Kafka, or Neo4j with a single click – or command if you are using the DC/OS command-line interface. As it is an open platform and anyone can submit new packages to the universe, it currently contains over 35 community-maintained packages.
Putting Neo4j on DC/OS using Marathon
Utilizing Marathon’s Resource Configuration
As the Neo4j 3.1 cluster handles it’s own membership and Neo4j official drivers provide smart routing, we don’t need to implement a custom scheduler. That reduces the effort needed to make Neo4j available as a universe package by several orders of magnitude.
The only information Neo4j needs to start up and form a cluster are the addresses of the initial members. DC/OS provides this information by serving A-Records in DNS for all Neo4j nodes. Therefore it is possible to use the official Neo4j 3.1 Enterprise Docker image as a base and extend it with a basic functionality to resolve DNS entries for service discovery.
The basic trick at this point is, to use the advanced DC/OS networking feature for overlay networks. By connecting to an overlay network, each container is assigned its own IP address and all its ports are exposed. This is a perfect match for the causal cluster, because the default management and protocol ports can be used and no load balancer is involved in container communication.
As explained, the default Neo4j Enterprise Docker image is used with only one additional entry-point shell script. This script first does a DNS lookup for the other cluster members on the dedicated network and then it adds the configuration for the causal cluster:
- Type of instance (
CORE,READ_REPLICA) - Advertised and listen-addresses (only for
CORE) - A seed of initial instances from DNS to contact to join the cluster
- Initial username and password
That’s it, more or less. With some additional documentation metadata the packages for CORE (neo4j) and READ_REPLICA (neo4j-replica) servers are ready to be used.
You can find all relevant bits and pieces in our repository.
Installation
You can easily install Neo4j from the universe.
Currently, three universe packages are available:
- One package for Neo4j core instances
- One for Neo4j read replication instances
- One for the Neo4j proxy, which is needed when accessing the Neo4j cluster via the Neo4j Browser from outside the DC/OS cluster, a.k.a. your local machine
During installation of each of the packages you can define several configuration parameters, e.g., Neo4j credentials, allocated resources (CPU, memory, disk), and overlay network name.

By installing a package from the universe, a Marathon configuration will be generated.
This can be done interactively or as a JSON file. Here is the example for a CORE server:
{
"id":"/neo4j/core",
"cpus":2,"mem":8000,"instances":3,"disk":2000,
"container":{
"type":"DOCKER",
"volumes":[
{
"containerPath":"data",
"mode":"RW",
"persistent":{
"type":"root",
"size":2000
}
},
{
"containerPath":"/data",
"hostPath":"data",
"mode":"RW"
}
],
"docker":{
"image":"neo4j/neo4j-dcos:1.0.0-3.1-RC1",
"network":"USER",
"forcePullImage":true
}
},
"env":{
"NEO4J_AUTH":"neo4j/dcos",
"NEO4J_dbms_mode":"CORE",
"NEO4J_causalClustering_expectedCoreClusterSize":"3"
},
"ipAddress":{
"networkName":"dcos"
},
"healthChecks":[
{
"protocol":"HTTP",
"path":"/",
"port":7474,
"timeoutSeconds":10,
"gracePeriodSeconds":240,
"intervalSeconds":10,
"maxConsecutiveFailures":10
}
]
}
Alternatively you can use the CLI and run a command like:
`dcos package install neo4j``dcos package install neo4j-replica``dcos package install neo4j-proxy`
Scaling
Scaling core nodes or read replication nodes is really easy. You can easily go to the service section in the DC/OS UI and scale the /neo4j/core or /neo4j/replicata application, like shown below:

The equivalent command from the CLI would be:
`dcos marathon app update /neo4j/replica instances=20`
During installation, the DC/OS dashboard looks like this:

And the output of the Neo4j `:sysinfo` command would look like this:


Health Checks
As part of the package, we also wanted to make sure that you know when your Neo4j servers are not just started but also when they’re ready to serve user requests. That’s why we added a Marathon Health Check setting which is a simple URL to call on the instance. For Neo4j we just used the root URL which acts as discovery URL for the available protocols:
GET https://host:port/ ->
{
"management" : "https://host:port/db/manage/",
"data" : "https://host:port/db/data/",
"bolt" : "bolt://host:7687"
}
If the health check fails ten times in a row, Marathon will replace the unhealthy Neo4j instance with a newly started one.
Persistent Data
As shown in the Marathon configuration, Neo4j receives a persistent local volume. If the task fails or stops, Marathon will try to restart the replacement container on exactly the same host with exactly the same data again. If the whole host fails, Marathon will start the replacement task on another host.
Following this strategy, Neo4j can decide if the given data should be reused or if an internal Neo4j cluster replication is needed. The big advantage of this strategy is that Neo4j can utilize the full performance of a local file system. You probably do not want to use a distributed file system for running a high performance database.
Accessing Your Cluster from the Outside
Your own application would be deployed in the trusted network on DC/OS with full access to Neo4j both via the binary Bolt protocol as well as the HTTP protocol. You’ll see an example later on.
But to access our shiny and new running cluster with the Neo4j Browser from our local machine, we have to route (at least) the HTTP protocol from outside of the DC/OS network. We do that using a simplistic (Node.js-based) HTTP proxy which we also provide as package (neo4j-proxy).
After starting a single instance of that proxy, your Neo4j Browser will be routed to the leader instance of the cluster, so that you can execute all operations needed (the same goes for the command-line tool cypher-shell).
Getting Up and Running
Set Up a DC/OS Environment
If you have never used DC/OS with Marathon before, now is the time to install a cluster either on one of the cloud providers (AWS, GCE, Azure, etc.), or locally on your machine using Vagrant. The DC/OS installation documentation guides will help you there.
If you have your DC/OS cluster up and running, you can launch the Neo4j services either with the Universe UI or with the DC/OS cli.
Johannes recorded a quick two-minute screencast that demonstrates this:
Start Your Neo4j Cluster
You find the packages in the UI by searching for “Neo4j”. First start the “Neo4j” service with three instances to launch the minimum for a cluster. You can see the instances starting and then become available after a few seconds.
Next we start the proxy so that we can access the Neo4j Browser of the cluster LEADER from our machine. We can create some data by entering :play movies and clicking and running the statement in the box.

Example Application
Now that you can deploy your application to the DC/OS, it is easiest if it is packaged as a Docker image. One small example that reproduces a Twitter-like setup, was published by Johannes as a Docker image to the Docker Hub and can be deployed to DC/OS with this configuration file:
twitter-load.json
{
"id": "/neo4j-twitter-load",
"cmd": null,
"env": {
"NEO4J_BOLT_URL":
"bolt://neo4j:dcos@core-neo4j.marathon.containerip.dcos.thisdcos.directory:7687",
"CONCURRENCY": "4",
"MAX_OPERATIONS": "100000"
},
"instances": 1,"cpus": 2,"mem": 4000,"disk": 500,"gpus": 0,
"container": {
"docker": {
"image": "unterstein/neo4j-twitter-load",
"forcePullImage": true,
"privileged": false,
"network": "HOST"
}
}
}
You can deploy the JSON config via the UI or via this CLI command:
dcos marathon app add twitter-load.json
It reads the initial cluster URL (NEO4J_BOLT_URL) from this special DNS name (core-neo4j.marathon.containerip.dcos.thisdcos.directory) of our cluster and starts sending read and write load (including using the bookmarking feature for causal consistency) to the cluster to simulate a number of Twitter users interacting on the platform.
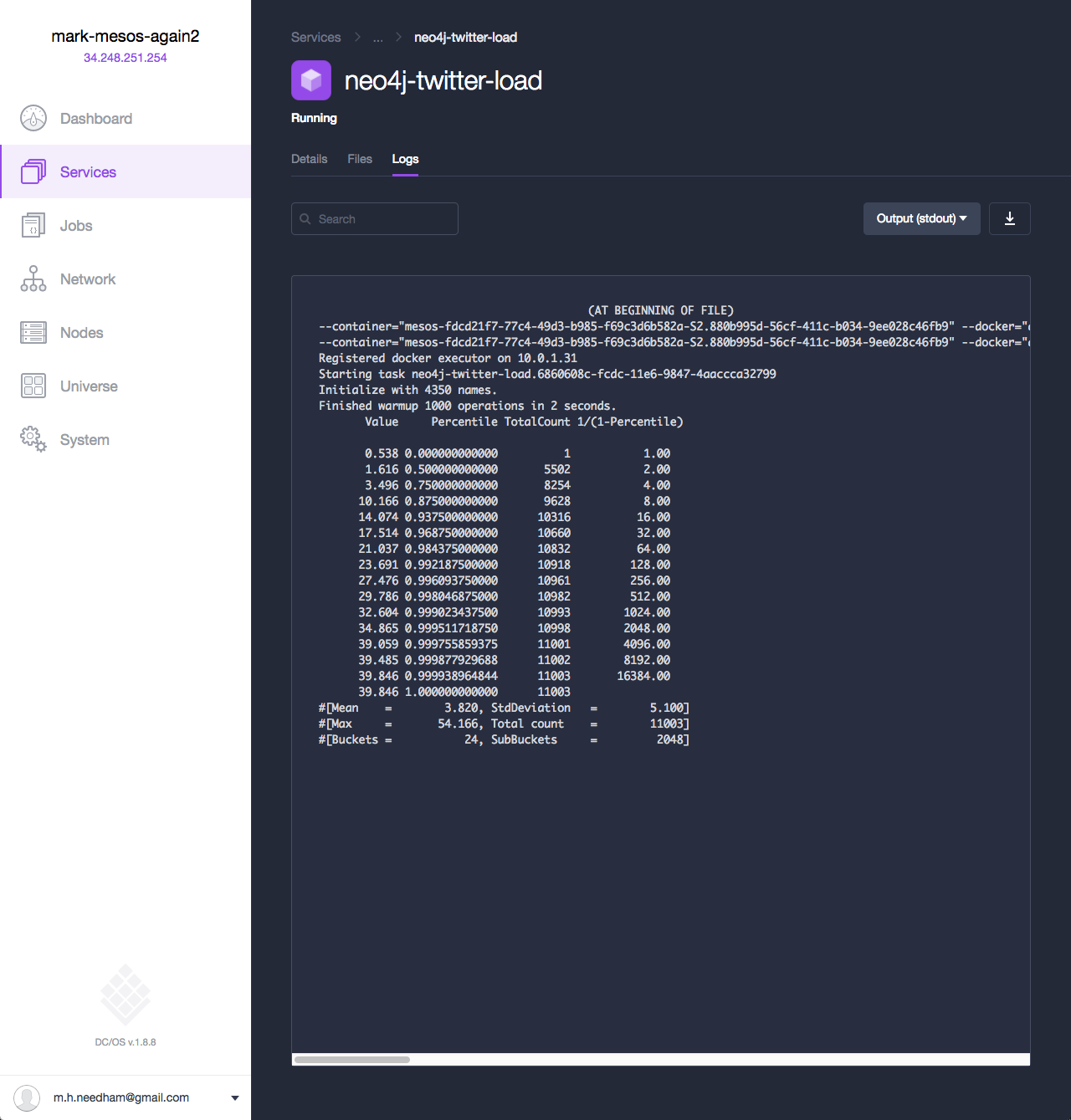
If we now navigate to the neo4j-twitter-load service, we can see that it’s now importing data into our Neo4j cluster:
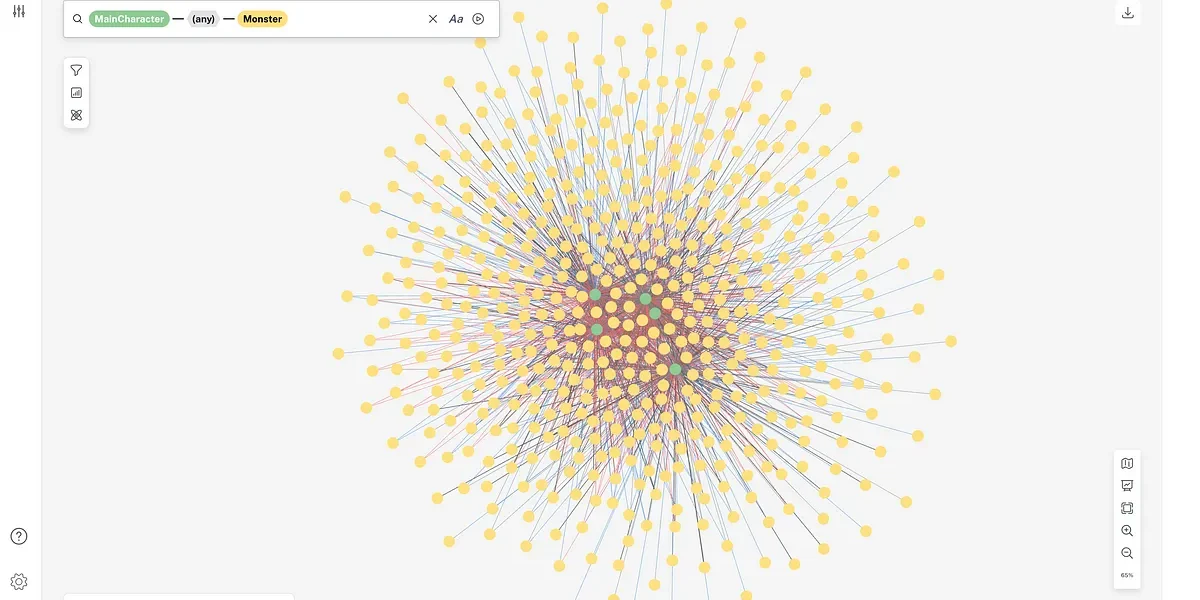
We can also see what that data looks like by browsing to the proxy IP address:

Resources
If you want to learn more and ask direct questions, please join our next Neo4j Online Meetup with Johannes and Mark, where they will demonstrate these steps (setting up Marathon, installing and scaling a Neo4j cluster, and deploying an example application) live. There you’ll also be able to ask any questions around DC/OS, Marathon and the Neo4j Causal Clustering architecture.
Mark Needham and Michael Hunger from Neo4j Developer Relations also contributed to this article.
Share Article



Explore
Related Articles

Bolster Your Cybersecurity by Visualizing Attack Graphs With Neo4j & G.V()



Top 10 Graph Database Use Cases (With Real-World Case Studies)

15 Best Graph Visualization Tools for Your Neo4j Graph Database