


Neo4j: A Reasonable RDF Graph Database & Reasoning Engine

Managing Director & Co-Founder, derivo GmbH
6 min read

[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
It is widely known that Neo4j is able to load and write RDF. Until now, RDF – and certainly OWL – reasoning have been attributed to fully fledged triple stores or dedicated reasoning engines only. This post shows that Neo4j can be extended by a unique reasoning technology to deliver a very expressive and highly competitive reasoning engine for RDF, RDFS and OWL 2 RL. I will briefly illustrate the approach and provide some benchmark results.
Labeled Property Graphs (LPG) and the Resource Description Framework (RDF) have a common ground: both consider data as a graph . Not surprisingly there are ways of converting one format into the other as recently demonstrated nicely by Jesús Barrasa from Neo4j for the Thomson Reuters PermID RDF dataset.
If you insist on differences between LPG and RDF, then consider the varying abilities of representing schema information and graph reasoning.
In Neo4j 2.0, node labels were introduced for typing nodes to optionally encode a lightweight type schema for a graph. Broadly speaking, RDF Schema (RDFS) extents this approach more formally. RDFS allows to structure labels of nodes (called classes in RDF) and relationships (called properties) in hierarchies. On top of this, the Web Ontology Language (OWL) provides a language to express rule-like conditions to automatically derive new facts such as node labels or relationships.
Reasoning Enriches Data with Knowledge
For a quick dive into the world of rules and OWL reasoning, let us consider the very popular LUBM benchmark (Lehigh University Benchmark).
The benchmark consists of artificially generated graph data in a fictional university domain and deals with people, departments, courses, etc. As an example, a student is derived to be an attendee if he or she takes some course, thus when he or she matches the following ontological rule:
Student and (takesCourse some) SubClassOf Attendee
This rule has to be read as follows when translated into LPG lingo: every node with label Student that has some relationship with label takesCourse to some other node will receive the label Attendee. Any experienced Neo4j programmer may rub his or her hands since this rule can be translated straightforward into the following Cypher expression:
match (x:Student)-[:takesCourse]->() set x:Attendee
That is perfectly possible but could become cumbersome in case of deeply nested rules that may also depend on each other. For instance, the Cypher expression misses the subclasses of Student such as UndergraduateStudent. Strictly speaking the expression above should therefore read:
match (x)-[:takesCourse]->() where x:Student or x:UndergraduateStudent set x:Attendee
It’s obviously more convenient to encode such domain knowledge as an ontological rule with support of an ontology editor such as Protégé and an OWL reasoning engine that takes care of executing them.
Another nice thing about RDFS/OWL is that modelling such knowledge is on a very declarative level that is standardized by W3C. In addition, the OWL language bears some important properties such as soundness and completeness.
For instance, you can never define a non-terminating rule set, and reasoning will instantly identify any conflicting rules. In case of OWL 2 RL, it is furthermore guaranteed that all derivable facts can be derived in polynomial time (theoretical worst case) with respect to the size of the graph.
In practice, performance can vary a lot of course. In case of our Attendee example, a reasoner – regardless of whether a triple store rule engine or Cypher engine – has to loop over the graph nodes with label Student and check for takesCourse relations.
To tweak performance, one could use dedicated indexes to effectively select nodes with particular relations (resp. relation degree) or labels as well as use stored procedures. At the end of the day, it seems that this does not scale well: when doubling the data, you double the amount of graph reads and writes to compute the consequences of such rules.
The good news is that this is not the end of the story.
Efficient Reasoning for Graph Storage
There is a technology called GraphScale that empowers Neo4j with scalable OWL reasoning. The approach is based on an abstraction refinement technique that builds a compact representation of the graph suitable for in-memory reasoning. Reasoning consequences are then incrementally propagated back to the underlying graph store.
The idea behind GraphScale is based on the observation that entities within a graph often have a similar structure. The GraphScale approach takes advantage of these similarities and computes a condensed version of the original data called an abstraction.
This abstraction is based on equivalence groups of nodes that share a similar structure according to well-defined logical criteria. This technique is proven to be sound and complete for all of RDF, RDFS and OWL 2 RL.
Here is an intuitive idea of the approach. Consider the graph above as a fraction of the original data about the university domain in Neo4j. On the right, there is a compact representation of the undergraduate students that take at least some course.
In essence, the derived fact that those students are attendees implicitly holds for all source nodes in the original graph. In other words, there is some one-to-many relationship from derived facts in the compact representation to nodes in the original graph.
Reasoning and Querying Neo4j with GraphScale
Let’s look at some performance results with data of increasing size from the LUBM test suite.
The following chart depicts the time to derive all derivable facts (called materialization) with GraphScale on top of Neo4j (without loading times) with 50, 100, resp. 250 universities. In comparison to other secondary storage systems with reasoning capabilities, it occurs that the Neo4j-GraphScale duo shows a much lower growth ratio in reasoning time with increasing data than any other system (schema and data files can be found at the bottom of this post).
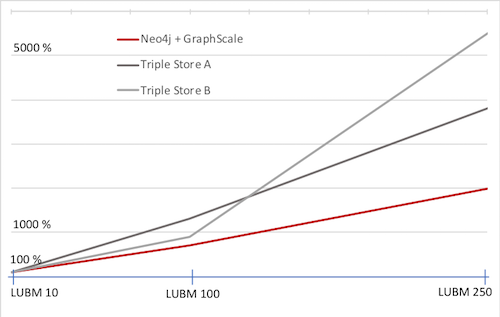
Experience has shown that materialization is key to efficient querying in a real-world setting. Without upfront materialization, a reasoning-aware triple store has to temporarily derive all answers and relevant facts for each single query on demand. Consequently, this comes with a performance penalty and typically fails on non-trivial rule sets.
Since the Neo4j graph database is not a triple store, it is not equipped with a SPARQL query engine. However, Neo4j offers Cypher and for many semantic applications it should be possible to translate SPARQL to Cypher queries.
From a user perspective this integrates two technologies into one platform: a transactional graph analytics system as well as a RDFS/OWL reasoning engine able to service sophisticated semantic applications via Cypher over a materialized graph in Neo4j.
As a proof of concept, let us consider SPARQL query number nine from the LUBM test suite that turned out to be one of the most challenging out of the 14 given queries. The query asks for students and their advisors which teach courses taken by those students – a triangular relationship pattern over most of the dataset:
SELECT ?X ?Y ?Z {
?X rdf:type Student .
?Y rdf:type Faculty .
?Z rdf:type Course .
?X advisor ?Y .
?Y teacherOf ?Z .
?X takesCourse ?Z
}
Under the assumption of a fully materialized graph, this SPARQL query translates into the following Cypher query:
MATCH (x:Student)-[:takesCourse]->(z:Course), (x)-[:advisor]->(y:Faculty)-[:teacherOf]->(z) RETURN x, y, z
Without a doubt, the Neo4j Cypher engine delivers a competitive query performance with the previous datasets (times for resp. count(*) version of query nine). Triple store A is not listed since it is a pure in-memory system without secondary storage persistence.

There is more potential in the marriage of Neo4j and the GraphScale technology. In fact, the graph abstraction can be very helpful as an index for query answering. For instance, you can instantly read from the abstraction whether there is some data matching query patterns of kind (x:.
Bottom line: I fully agree with George Anadiotis’ statement that labeled property graphs and RDF/OWL are close relatives.
In a follow-up blog post, I will present an interactive visual exploration and querying tool for RDF graphs that utilizes the compact representation described above as an index to deliver a distinguished user experience and performance on large graphs.
Resources
GraphScale:
- GraphScale: Adding Expressive Reasoning to Semantic Data Stores. Demo Proceedings of the 14th International Semantic Web Conference (ISWC 2015): https://ceur-ws.org/Vol-1486/paper_117.pdf
- Abstraction refinement for scalable type reasoning in ontology-based data repositories: EP 2 966 600 A1 & US 2016/0004965 A1
Data:
- LUBM OWL 2 RL schema and RDF data (https://www.semspect.de/lubm-neo4j-graphscale.7z) used in the evaluation
Share Article


Explore
Related Articles
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI


A Practical Experimentation of GraphRAG and Agentic Architecture With NeoConverse

