Best Practices to Make (Very) Large Updates in Neo4j

Field Engineer, Neo4j
7 min read

Editor’s Note: This presentation was given by Fanghua Joshua Yu at NODES 2019.
Presentation Summary
Fanghua Joshua Yu, Neo4j Pre-Sales & Field Engineer answers an age old question in his NODES 2019 presentation: What do you do when Neo4j is slow to update?
First, it is valuable to understand how Neo4j handles updates. Yu reviews strategies to optimize updates in Neo4j.
Next, Yu reviews a case study of a Stack Overflow dataset. The Stack Overflow database has around 31 million nodes and 78 million relationships holding hundreds of millions of properties.
Lastly, Yu demonstrates how to make large updates for tens of millions of nodes and elude the dreaded OutOfMemory error. These updates could include deleting millions of nodes and relationships at one time. In our example, Yu cuts our processing time from 8.5 hours to 10 minutes.
Following that, Yu shares examples of Cypher tuning and how to keep it efficient.
Full Presentation
First off, let me introduce myself. My name is Fanghua Joshua Yu.

I’m a Neo4j Pre-Sales & Field Engineering Lead in the APAC region.
Today’s session theme is based on a question. The question is: Have you ever complained that it is very, very slow to make updates in Neo4j?

Sometimes, Neo4j’s database just stops responding with something like a Java OutOfMemory error.

If you relate to these cases, I think you have found the right blog.
First, we are going to understand how Neo4j handles updates and the strategies to optimize updates in Neo4j.
Then, we are going to review a case study with very limited resources available on our server.
Finally, we are going to learn how to make large updates for tens of millions of nodes without having the OutOfMemory issues. After that, we will finish off with more on Cypher tuning.

We’re going to have some Neo4j handles, updates and transactions. This means, if you’re trying to make very large updates in one transaction or in one Cypher statement, Neo4j will store all the entrance steps into memory. That ensures that if the transaction fails, everything is able to be rolled back. This guarantees consistency of the database. That’s a very common idea.

The larger the updates are, the larger the memory we require. That memory is actually sitting in JVM Heap memory.
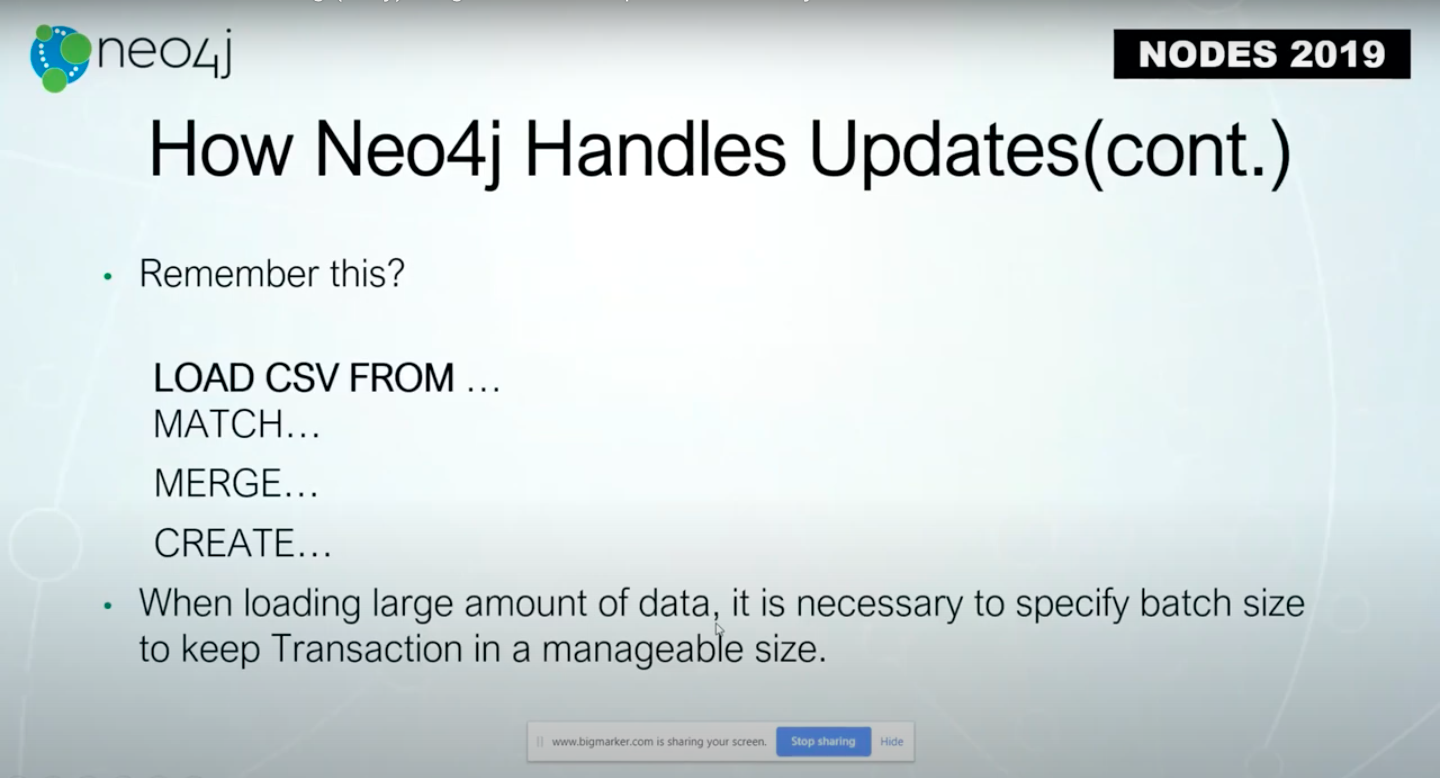
If you have ever used LOAD CSV FROM from a very large data file, you’re recommended to use PERIODIC COMMIT with a number like 1,000.

That means every 1,000 lines you read from the data file, Neo4j would do a commit to complete the transaction, and then the next 1,000, and the next 1,000.
By doing this, you reduce the size of transactions, or the number of updates made within a transaction. This reduces the memory required to read a transaction.
In another Cypher statement, we use APOC procedures like apoc.periodic.iterate to do similar things.

Within the apoc.periodic.iterate procedure, there are several parameters you could use. The first one is a Cypher query to return a collection of things.

These things could be a collection of node IDs, objects, nodes, relationships, paths or anything.
The second parameter is for the Cypher statement to update the database based on the results returned by the first query.

As seen above, if we return one million node IDs, then the second statement will update one million nodes.
The batchSize controls the size of transactions.

Every 2,000 statements, the second statement, will be bundled and committed as one transaction.
Also, the parallel parameter defines whether I want my processes to be executed in parallel or in zero of the sequential operations.

Next, we have iterative lists.

Whether you have the whole list executed as one transaction or not, the default should always be true.
There are a lot of things that could affect the performance of updates.

For example, hardware like a disk, could affect the performance of your updates. What type of disk are you using?
Be sure to monitor how the CPU threads are used when you update transactions.
Execute a Cypher statement where it’s most optimized, and check if there are any heavy operations used within a transaction.
How big is your data? How many nodes or relationships are you updating within one transaction within a Cypher statement? Know your data volume.
Parallel processing should be enabled, but it does not largely impact results.
Query tuning asks if the query is most optimized – there could be another way to further tune the query.
Plus, we have other considerations, like whether you’re running those updates in a single instance of Neo4j or updated in your cluster which also has a lot of implications.
Case Study
Let’s go through a quick case study using the Stack Overflow dataset.
The Stack Overflow database has about 31 million nodes and 78 million relationships of some hundreds of millions of properties.

Our data model of Stack Overflow is very straightforward.

Above we have a blue post node, a yellow user node, and then a green Tag node. The user posted a post and that post has a tag.
The post could be a parent of other posts, or the post could answer another post. The Cypher statement we are going to test is pictured above and is about making large updates.
We match our post with the ID. Then we’ll match the user(s) who posted the post.
Then, we will set a property called postedby to be the userId from the user node.
We want to test how this Cypher update performs. We store the user who posted the post and the ID of the user to the value of the property post.
Our testing environment is a laptop. Our limit is 12 gigabytes RAM, and the local disk is a mechanical disk.

To compare the performance, we also attached a SSD drive via USB 3.0 port.
The key thing here is a Java page cache will allocate two gigabytes, and Java Heap is a maximum of four gigabytes. The database size is about 17 gigabytes.
You may have seen this before in the Neo4j.conf configuration file. We are able to specify the initial heap size,the maximum heap size, and also page cache.

Page cache is mainly used to load content like nodes, relationships or indexes in memory to improve the read performance. The heap, as I mentioned before, is for keeping all entrance states of the transactions committed.
Hardware
The first thing is hardware: How quick is a disk?
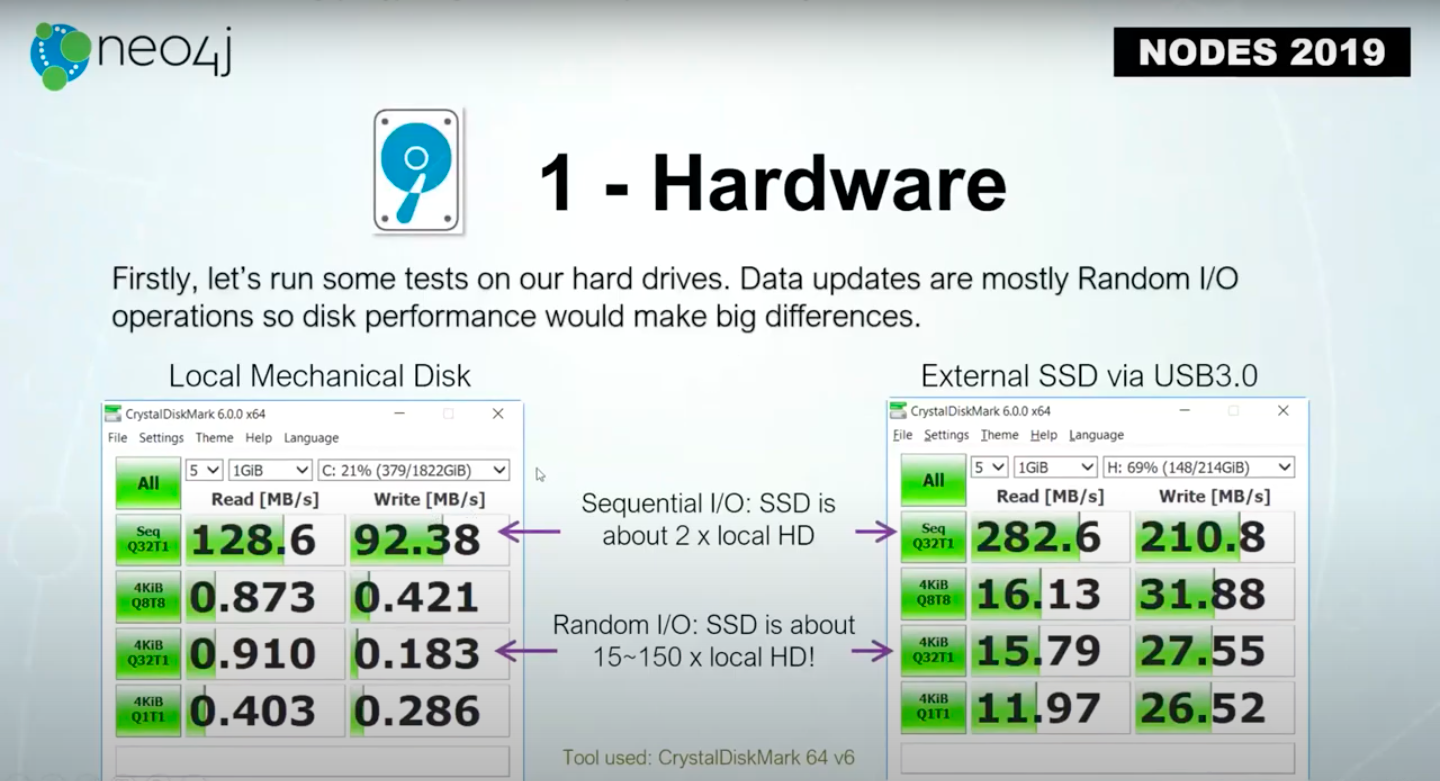
Because database updates are mostly Random I/Os, the performance of Random I/O read and writes are pretty important to the overall performance.
The comparison is above, even an external attached SSD is much faster than the local mechanical disk. It could be 15 or 150 times faster than the local drive.
The Neo4j Enterprise Edition exposes metrics of how a database server is running and how to configure a data server.
Monitoring

With monitoring, we check the disk usage, error response time, read speed and write speed.
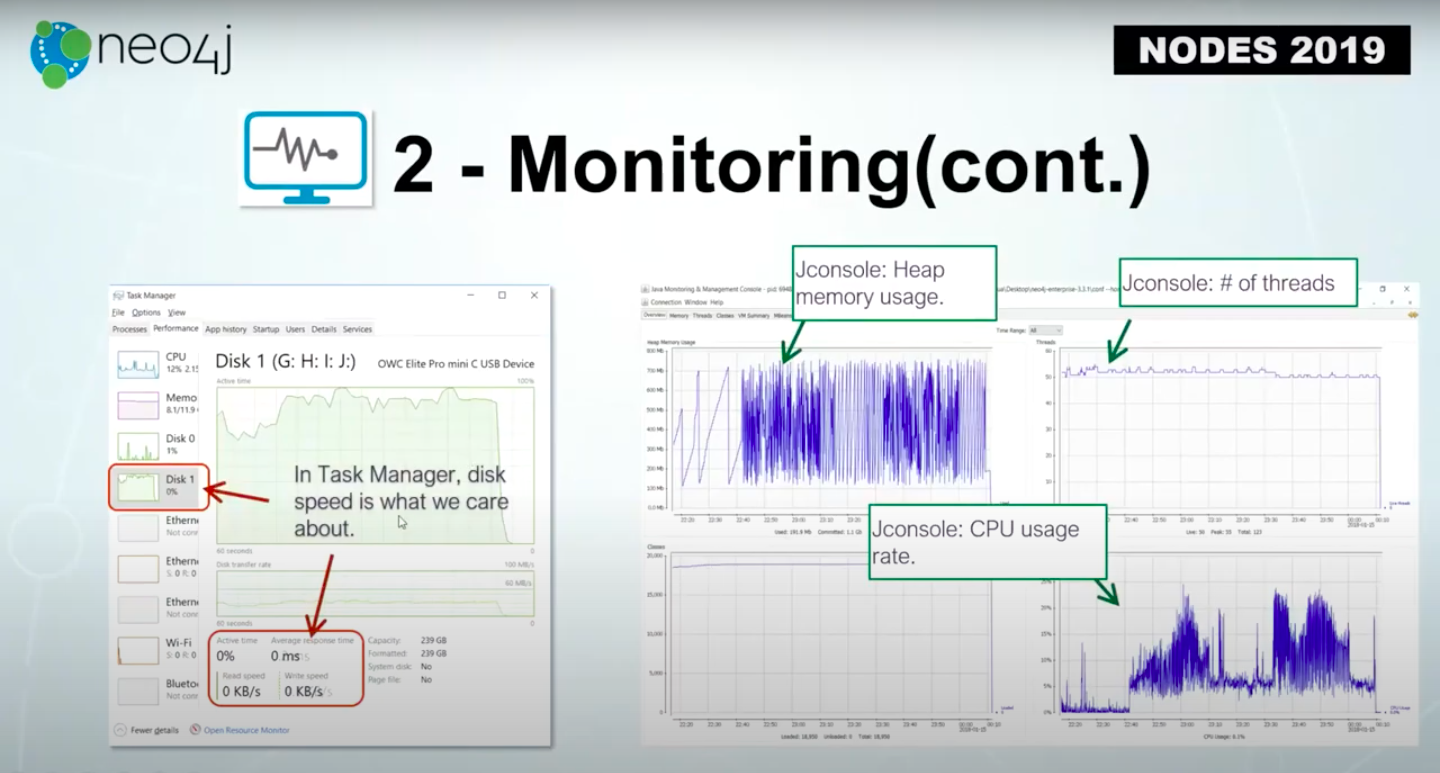
If you open the Jconsole, we also check the heap memory usage in monitoring, the number of threads and the overall CPU usage rate.
While we do the test, we monitor those metrics to see how the system resources are used.
Execution
Let’s start with updating one million nodes.

Luckily, in this database, the ID of the post is sequential. From zero to one million is one million post nodes, we’ll just update them. While running the execution, we check the CPU use, the RAM disk speed and those kinds of things.
One important aspect of the Neo4j database is the most efficient method to access any node relationship is internal ID, which is accessible by function ID.
Below, we have the results from updating one million nodes.

With the Cypher statement, we’ve just seen it takes about 46 seconds. Additionally, the heap memory usage is well below two gigabytes, which is good. CPU usage is around 25 percent, which is also good. The write speed is about 20,000 nodes per second, and that’s not bad.
However, when we change the size of the updates to be from one million to 1.5 million, we notice the Java heap memory has increased 3.5 times.

You could still update 1.5 million nodes using pure Cypher. However, when we try to update too many nodes simultaneously in one Cypher transaction we run into the same issue.

Our execution fails because the heap memory is out of memory.
In that sense, it means if we update all of the data which is 25 million nodes, that would require 65 gigabytes of heap memory. That’s not going to happen.
APOC
The secret is to use APOC.

Here’s how we’re going to do it.

We’re going to use apoc.periodic.iterate, and we’ll control the batchSize to be 2,000 updates in one transaction.

Then, we run the APOC procedures with the updated batchSize and compare results.

Our batchSize went from 2,000 to 20k, and above are the results.
The important thing to look at is the Java Heap memory. It’s very well controlled beneath our upper limit. We are able to see that the bigger the batchSize, the more Java Heap memory used – which makes sense. As long as it’s below the maximum allocated Java Heap size, that’s all we want.
We are very well under the limit and the CPU usage is okay.

In a larger batchSize, we want less transactions to commit. But, on the other side, if the batchSize itself is too large, that might slow down the overall performance.

We picked 2,000 as our batchSize. This is based on the maximum throughput it reaches, and also the CPU usage.
The other thing we should look at is whether the transaction could be processed in parallel.

We changed Parallel from false to be true, and then we’ll run again.

The batchSize was four, because the computer has four cores. Every transaction is still 2,000 with four cores to run four parallel drops.
We have a higher write speed that almost doubled, to 55,000 nodes per second. The heap memory usage is within the range we’re looking for and the CPU is fine.
We tested different combinations of updates with the two million, four million, 10 million, 15 million – everything looks fine.

Now we see that parallel processing improves performance.

The important thing we need to be aware of is locking conflicts. That means, if we run drops in parallel in multiple threads – on multiple Cypher statements or on multiple processing drops – there will be conflicts when we try to update the same nodes or same relationships.

Locking conflicts are something you need to be aware of and be careful of when you use parallel processing.
Another thing to consider is query tuning.

If in the first cases, we return the PostID and Internal ID of the nodes before we return the objects, the objects contain more information. That increases our data volume, and the CPU’s usage will be higher.

The Java Heap memory use is also higher than the previous case where we only returned the ID number in the drop.

Query tuning takes more time and it takes more memory. That’s something we need to consider. Below are the results of the full updates.
Image: Query tuning (4)
Twenty-six million nodes were successfully updated by using APOC procedures, without getting an OutOfMemory error or breaking the database stories.

There are a couple of more points on query tuning. Much like the hardware, the infrastructure is also fixed. Other than adding more memory or CPU power, how you choose to compose your query is very critical.

Sometimes, even if you say USING PERIODIC COMMIT, it could still cause an OutOfMemory error. It could be because you are trying to do too many steps at once. What you should do in that situation is reduce the number of PERIODIC COMMIT.
The second way is more interesting, and that is if you have an eager operator who will disable PERIODIC COMMIT.
Eager commit example
Let’s look at an example of an eager commit.
The eager operation is the definition of the execution plan, pretty simple.

Within the eager operation, the Cypher will try to store all the previous results in memory for the later steps.

Let’s say, we’re trying to load a movie database. We create MOVIE nodes, we take the MOVIE nodes, and then we create Person nodes. Finally, we return the MOVIE nodes created in the previous steps.
In the Cypher below, if we profile the execution, we will see an eager operator.

That means, even if we specify this using PERIODIC COMMIT 500, because we need to return a variable defined in the previous step, the execution has to keep all the results previously done in order to return it at the end. That’s why there’s eager operators.
Even if the transaction is 500, the results will be stored and will be kept to be returned later.
The solution to this is since you’re updating the database, you don’t have to return anything if it’s not necessary, or you return no property.
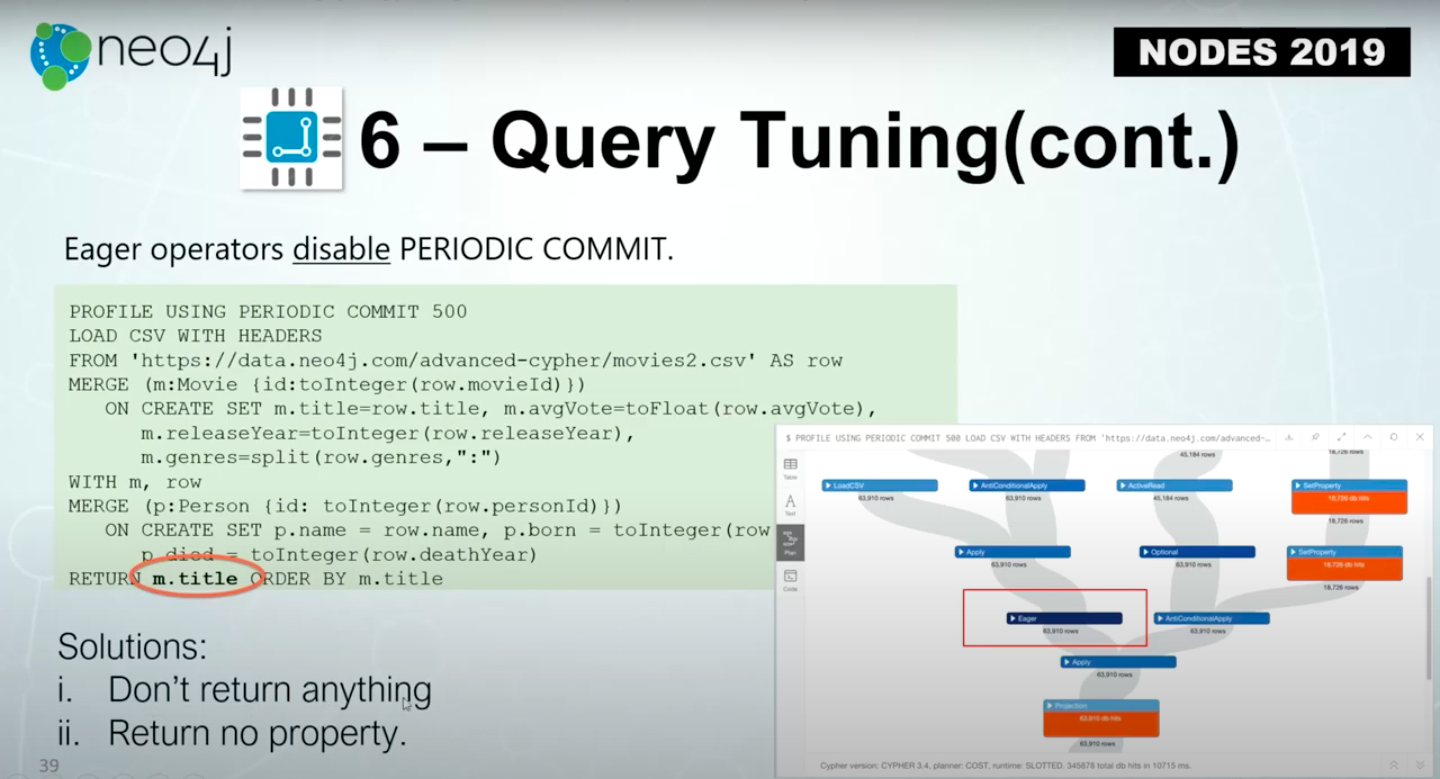
Let’s try this. If we click RETURN M without the Title property you won’t see the eager operator here.
Also, it’s possible to use APOC procedures to do a periodic commit by using a load.csv. Using a load.csv APOC procedure is an iterative procedure.
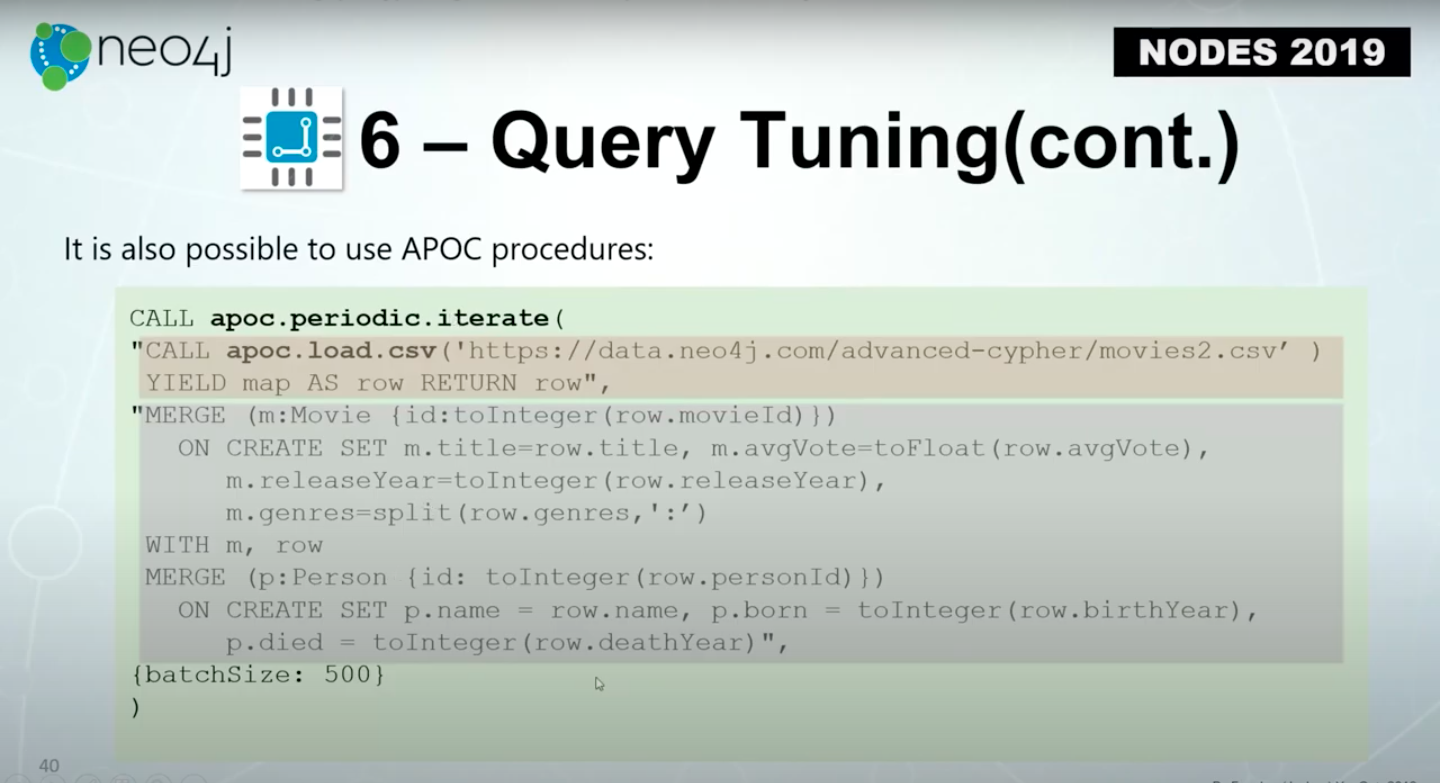
In Cypher statements, you cannot specify that you want to use a variable for your label, node label or the relationship type.
However, in query tuning, you are able to construct your Cypher. You could specify the movie, the value of a movie, which is a label from another parameter from a field in your source file. That’s another benefit of using an APOC procedure to load data.
Deleting large data
Sometimes, we need to delete large amounts of data. Let’s say we want to delete all of the PARENT-OF relationships. Below we have about 16 million of them.
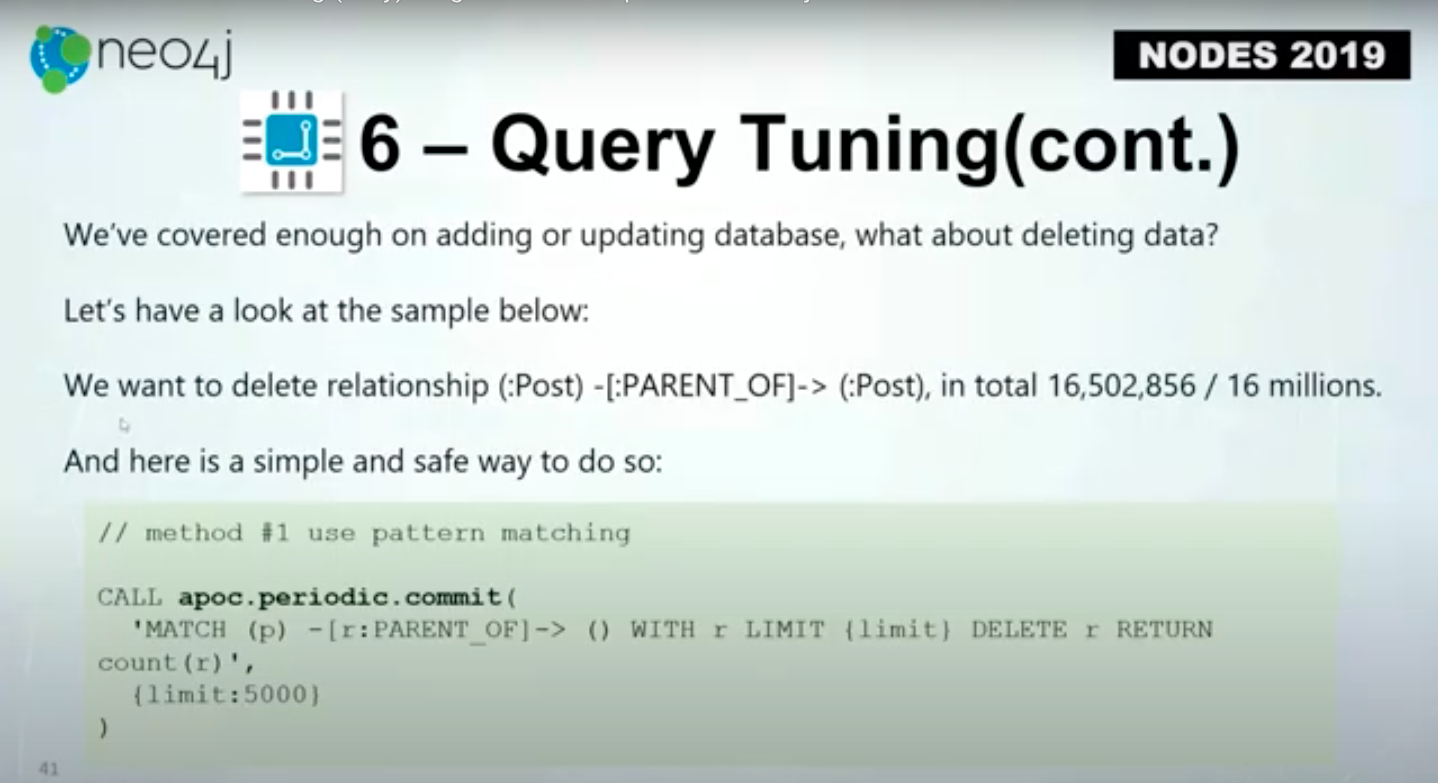
This is the recommended way.
First, you use apoc.periodic.commit. You match P through Relationship, R, with R.Then you set a limit of 5,000, and use a delete and return count. That means we will delete 5,000 of PARENT_OF relationships in a transaction.
This is the right way to do things instead of the pure Cypher way which is to match P PARENT_OF with R DELETE R.
Using pure Cypher might get you the OutOfMemory error. However, by using periodic commit, you will not encounter that issue.
To do the job and delete 16 million relationships it took 8 1/2 hours. You could test it on your own computer. On my computer, it took 8 1/2 hours.

That’s roughly 500 deletes per second and it is not good enough. We could do better.
Remember, the internal ID-the way Neo4j organizes data, all the nodes are stored in a node store. Every node has a fixed width, so do relationships. That’s why the Internal ID becomes very useful.
The internal ID actually is the logical location of the node or relationship in the node/relationship store. Accessing a node or relationship via it’s internal ID is the most efficient way. This is the most efficient way because, if an ID is 1, then we know the node storage address of the node is from the position of 15 bytes to 29 bytes in the storage. It’s simple math.

Let’s try the second way to do this.
First, let’s figure out the Maximum ID and the Minimum ID of the relationship PARENT_OF.

In this case, it’s sequential, very likely because we import data into the database.
The second step, because we are deleting 16 million relationships, we write a Cypher query like below.

We construct IDs, with a Range of 1,650 drops. We call apoc.periodic.commit to view the ID of the relationship or find the relationship by its ID and delete relationship. The batchSize is 10,000.
If there are relationships where the nature of the relationship is not PARENT_OF, we’re not going to touch it. By changing updates in this way, we actually improve our performance.

This only takes less than 10 minutes as compared to 8 1/2 hours on the same machine. That’s more than 50x improvement.
The key thing here is, sometimes, you are able to use internal ID to do updates in a much faster way.

The last thing you might consider is whether you’re updating your database in a cluster or in a single instance.
In a cluster, all database updates in a cluster will be coordinated and sent to the leader node. Then, the leader node will manage and will make sure more than half of the core members have committed the updates before a transaction is considered to be committed.
If there’s a very large commit or update, the leader could become very busy and unable to respond to communications from other nodes. Other nodes might think the leader is offline and re-elect a new leader. This causes instability of the whole cluster. The solution here is to make sure the transaction size is smaller so this won’t happen.

You change the batchSize when you use an APOC procedure to make it small enough for each transaction. This way the leader will not get too busy to respond to the pinging from other nodes and the cluster will remain stable.
Summary

To summarize, disk speed is very important. Use an SSD – this is always recommended. If you want to do parallel processing, using an SSD is the only choice.
The transaction sizes matter because there is a limit. The entrance state of all transactions is stored in the Java heap memory, and the larger a transaction is, the larger memory you will require. If there isn’t enough memory, then you get a Java OutOfMemory error and the database source might be terminated or inaccessible.
Use APOC procedures to iterate or commit, you are able to control the batchSize and make the transaction update parallel-y.

I always recommend, before making large updates, make sure you do some tests to understand the profile of your updates. This is most critical in the production environment.
Try to tune your Cypher as much as possible to make sure it’s the most efficient.
If you need more help, the Neo4j community is always there. Also, we have training modules like the Advanced Cypher graph database modeling, and the APOC library . These are good sources for you to have a better understanding.
Finally, you are always welcome to talk to us anytime and through any channel!
Share Article



Explore
Related Articles