



Hello, everyone!
In this week’s episode, don’t forget to join us for Global Graph Celebration Day on April 15! Neo4j is hosting an extended meetup with content and announcements.
Cristina starts us off with a walkthrough of using Django and Neo4j together on the Paradise Papers data set. Sixing covers importing genomes and ontologies with the KEGG data and exploring for research and scientific hypotheses. Christophe shows off the new change data capture connectors by GraphAware for RabbitMQ, AWS SQS, Azure Service Bus, and CloudEvents with Knative.
And finally, help Neo4j improve data import by filling out a survey, Jesús follows up on the video in last week’s newsletter for reconciling taxonomies, Rik explores clickstream data in Neo4j, and Christophe shared a short clip of visualization using Hume with a keywords review demo.
Cheers, Jennifer and the Developer Relations team
Featured Community Members: Andrea Santurbano & Giuseppe Villani
This week’s featured community members are Andrea Santurbano and Giuseppe Villani.

Andrea Santurbano, Giuseppe Villani – This Week’s Featured Community Member
Andrea is a CTO at LARUS Business Automation and has been very involved for several years with the APOC library, creating new functionality and fixing bugs. He has been the mastermind behind many pull requests and has conversed with much of the community in the APOC Github repo. Over the last couple of years, he has also contributed and published content around the Neo4j Streams library that integrates Neo4j with Apache Kafka. Andrea has participated in several Neo4j events, including NODES last year with a session on combining Neo4j with Apache Spark.
Giuseppe is a software developer at LARUS Business Automation and works with Andrea on the APOC library. He has been very active on APOC’s Github repository in recent weeks, also contributing to the code base with new procedures and making updates to existing functionality. He has quite a flurry of activity on Github, so you can be sure to find him there contributing code and making Neo4j users’ lives better. Last year, Giuseppe also spoke at our NODES event with a presentation on Spring, Neo4j, and JHipster.
Thank you, Andrea and Giuseppe, for your contributions to the Neo4j ecosystem and for having such an impact in the community! We appreciate everything you’ve done and look forward to continued collaboration!
Neo4j for Django Developers
Cristina shows us how to use an object-relational mapper like Django and an object-graph mapper like neomodel together to enhance an application with the graph data structure of Neo4j.
We see the Paradise Papers search application as an example of how someone could add Neo4j to an already-existing Django application. Cristina also walks through setting up the example on Neo4j Sandbox, locally in Neo4j Desktop, or with Neo4j Aura! Steps are also included to deploy the application to Heroku. At the end, Cristina guides us to the next steps with resources for exploring the data set and importing your own relational data to Neo4j using the ETL tool, so that you can try Django-neomodel in your own projects. Happy developing!
Analyzing Genomes in a Graph Database
In this post, Sixing shows us how to import and explore the Kyoto Encyclopedia of Genes and Genomes (KEGG) data for KEGG Orthology (KO) numbers. The code is already prepared for us in a Github repository, but Sixing pulls data from the API using a Python script, then import the data as CSV files into Neo4j.
Once imported, we run some queries to find the rarest and most common KO numbers in genomes and find out which genomes are the most similar by comparing the KOs they share. Finally, Sixing shows us how to use Neo4j Bloom to handle the visualizations for this larger data set and understand why Neo4j is such an asset for research to locate hypotheses and test them.
Don’t Miss: Global Graph Celebration Day – April 15!

Global Graph Celebration Day is just around the corner on April 15th! Neo4j is hosting an extended meetup for graph enthusiasts around the globe. We will learn some basics about graphs, hear how people in the community are using Neo4j in their projects and businesses, play games and win prizes for some fun, and wrap up with GraphQL community call where there are sure to be some exciting announcements!
Watch the event live on Thursday and join in on the fun with Neo4j and the community!
Neo4j Change Data Capture with GraphAware Hume
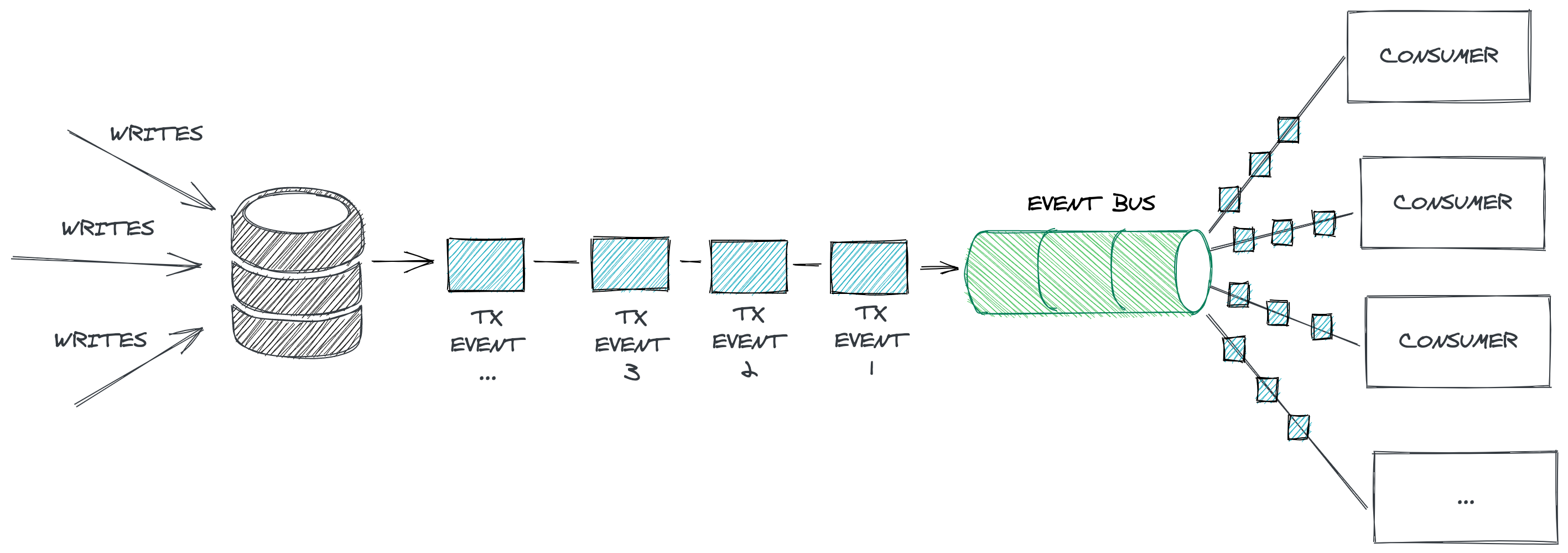
Christophe writes about the connectors they have built for change data capture (CDC). While the Neo4j Streams project with Kafka is good, messaging platforms in businesses are polyglot where all kinds of change data capture is needed. To support their needs and their customers’ needs, GraphAware built connectors for RabbitMQ, AWS SQS, Azure Service Bus, and CloudEvents with Knative.
Christophe briefly explains the integration with CloudEvents, as it is likely the least common, then gives a brief overview of using the Neo4j change data capture with Hume Orchestra. The post concludes that change data capture can help applications react to changes in the database and increase business value.
Data Import Survey, Taxonomy Reconciliation, Analyze Clickstream Data, Hume Visualization

- Neo4j wants to know your experience around data import! Help us improve by responding to the survey.
- If you caught Jesús’s knowledge graph video last week, there is now a continuation blog post honing in on the reconciliation of taxonomies.
- Rik published a blog post that explores clickstream data in Neo4j. Find out how user journeys through page links are a great use case for Neo4j!
- Christophe shared a clip on Twitter demonstrating 3 of Hume’s features for visualization with a keywords review demo. It shows how Hume can do more than data exploration, handling operations and actions from the visualization itself.
Tweet of the Week
My favorite tweet this week was by David Allen:
Launching .@Neo4j Enterprise Edition VMs on @Azure https://t.co/DfQtjW6KOP
— ????? ????? (@mdavidallen) March 31, 2021
Don’t forget to RT if you liked it too!





