



Welcome to the 3rd edition of This Week in Neo4j for 2019.
We’ve got a variety of different things for you this week. Christophe Willemsen has written an excellent deep dive into the Full-Text Search feature released in Neo4j 3.5, Dr Jim Webber explains how Neo4j can be used for large scale systems using less servers, Emil is interviewed on Azeem Azhar’s podcast, and of course we have the next post in Jennifer Reif’s Marvel Series!
Featured Community Member: Michael Simons
This week’s featured community member is my colleague Michael Simons – Java-Champion, JUG-Lead, conference speaker and book author. Besides his two sons and wife, coding, writing, biking, running and taking pictures are playing a big role in his life. You can more about him on his site.
Michael joined Neo4j as part of the Spring Data team in Summer 2018, and is working with Gerrit Meier to enhance the capabilities of Neo4j-OGM and Spring Data Neo4j which are used by a lot of our users and customers.

Michael Simons – This Week’s Featured Community Member
But it doesn’t stop there. After joining Michael immediately started building examples, writing articles, giving talks at conferences and user groups and contributing to other open source projects.
He recently submitted Neo4j support to TestContainers and wrote about it here. This week Michael gave an JUG talk in Utrecht where he met co-biker Rik van Bruggen, who interviewed Michael on the Graphistania podcast in October.
On behalf of the Neo4j community, thanks for all your work Michael!
Topic Extraction with MeaningCloud and Graphileon
This week in the Neo4j Online Meetup, Tom Zeppenfeldt gave us a fascinating deep dive into some of the capabilities of Graphileon – a tool that can be used to rapidly design and deploy graph-based applications.
Tom showed how to query data from the MeaningCloud text analytics API, and build a graph from the results using Graphileon. If you want to quickly build your first graph app without having to worry about the glue code, this presentation is a pretty good place to start.
Deep Dive into Neo4j 3.5 Full Text Search

One of the major features released in Neo4j 3.5 was support for Full Text Search, and in the months since then Christophe Willemsen has been taking it through its paces.
This week he wrote a blog post explaining how Apache Lucene, the underlying search, works under the covers. With the help of a worked example Christophe explains the data structures used by Lucene, shows how to write fuzzy and wildcard queries, and explains the scores returned by the search engine.
Neo4j for Very Large Scale Systems
Our Chief Scientist, Dr Jim Webber, has been in the video studio this week, explaining how Neo4j can be used for very large scale systems.
Using the example of a system that David Fox and his team at Adobe built, Jim describes how data problems that require 10s of MongoDB or Cassandra instances can be solved with a small Neo4j cluster.
Importing RDFS/OWL ontologies into Neo4j
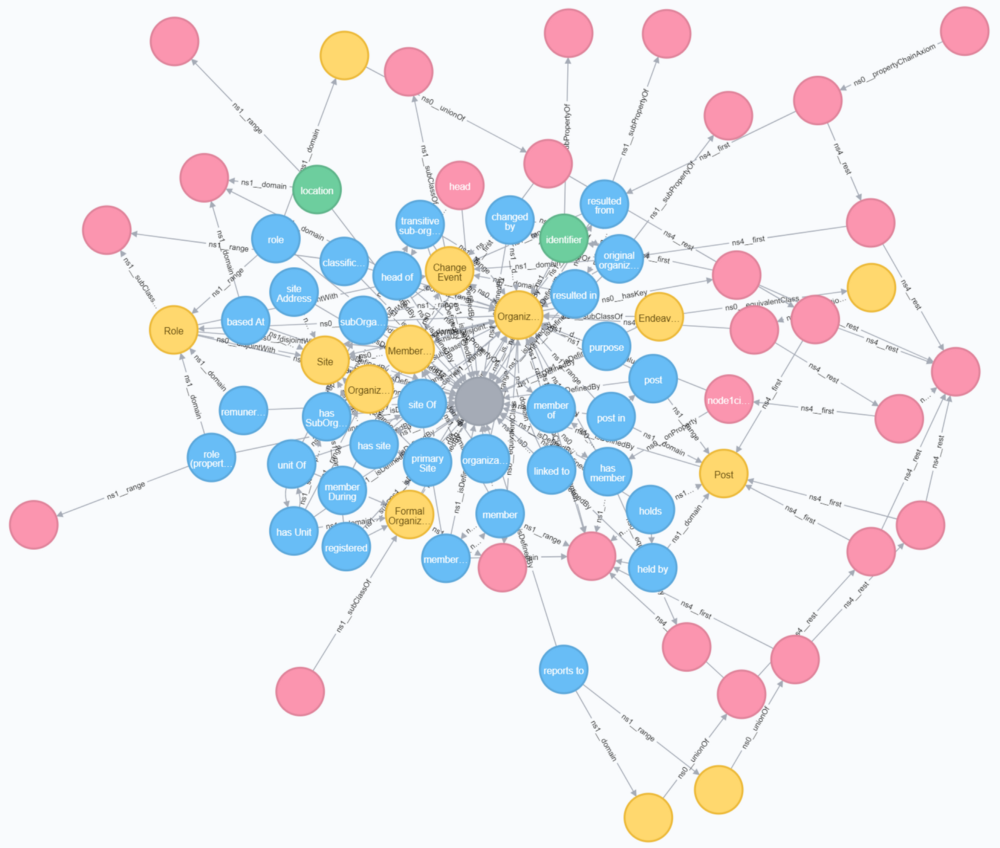
Lju Lazarevic is frequently asked how to import RDFS/OWL ontologies into Neo4j, and this week has written a blog post showing how to import the W3C Organizational Ontology using the neosemantics tools.
After importing the data, Lju explains how the RDF and Label Property Graph models differ, and shows how to make user-friendly views for exploration of the data using the APOC library,
Making Sense of the Data-Rich World with Graph Databases: Emil Eifrem and Azeem Azhar in Conversation

Azeem Azhar interviewed Emil on the latest episode of the Exponential View podcast.
They discuss the origin of graphs and graph databases, the ICIJ’s Panama Papers investigation, and the types of problems that customers are solving with graphs.
Create a Data Marvel: Developing More Entities

In the 6th post in Jennifer Reif‘s series of posts showing how to build a full stack application with Spring and Neo4j, Jennifer create classes for another 4 areas of the graph data model – creator, event, series, and story.
In a code heavy post, Jennifer shows how to remove the majority of boilerplate code using Spring Data Neo4j and Lombok annotations.
Tweet of the Week
My favourite tweet this week was by Joe Depeau:
I told Armstrong if he was going to come to the office with mehe’d have to do some work. So, here he is plugging the #Graph Databases book by @OReillyMedia. He really wants you to download it. You know you can’t resist!! @neo4j https://t.co/iuJIxlYD5V pic.twitter.com/FfIvsV20aF
— Joe Depeau (@joedepeau) January 14, 2019
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark





