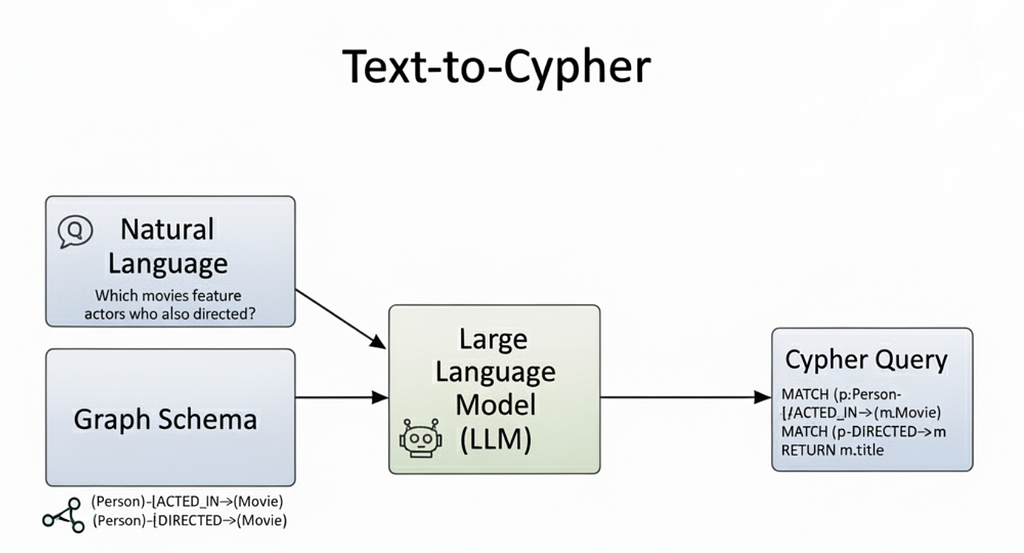
Written by Rik Van Bruggen. Originally posted on his blog.
- the HR function could really benefit from a more real world understanding of how information flows in its organization. Information flows through the *real* social network of people in your organization – independent of your “official” hierarchical / matrix-shaped org chart. Therefore it follows logically that it would really benefit the HR function to understand and analyse this information flow, through social network analysis.
- In recruitment, there is a lot to be said to integrate social network information into your recruitment process. This is logical: the social network will tell us something about the social, friendly ties between people – and that will tell us something about how likely they are to form good, performing teams. Several online recruitment platforms are starting to use this – eg. Glassdoor uses Neo4j to store more than 70% of the Facebook sociogram – to really differentiate themselves. They want to suggest and recommend the jobs that people really want.
- In competence management, large organizations can gain a lot by accurately understanding the different competencies that people have / want to have. When putting together multi-disciplinary, often times global teams, this can be a huge time-saver for the project offices chartered to do this.
For all of these 3 points, a graph database like Neo4j can really help. So I put together a sample dataset that should explain this. Broadly speaking, these queries are in three categories:
- “Deep queries”: these are the types of queries that perform complex pattern matches on the graph. As an example, that would something like: “Find me a friend-of-a-friend of Mike that has the same competencies as Mike, has worked or is working at the same company as Mike, but is currently not working together with Mike.” In Neo4j cypher, that would something like this
match (p1:Person {first_name:"Mike"})-[:HAS_COMPETENCY]->(c:Competency)<-[:HAS_COMPETENCY]-(p2:Person),
(p1)-[:WORKED_FOR|:WORKS_FOR]->(co:Company)<-[:WORKED_FOR]-(p2)
where not((p1)-[:WORKS_FOR]->(co)<-[:WORKS_FOR]-(p2))
with p1,p2,c,co
match (p1)-[:FRIEND_OF*2..2]-(p2)
return p1.first_name+' '+p1.last_name as Person1, p2.first_name+' '+p2.last_name as Person2, collect(distinct c.name), collect(distinct co.name) as Company;
- “Pathfinding queries”: this allows you to explore the paths from a certain person to other people – and see how they are connected to eachother. For example, if I wanted to find paths between two people, I could do
match p=AllShortestPaths((n:Person {first_name:"Mike"})-[*]-(m:Person {first_name:"Brandi"}))
return p;
and get this:

Which is a truly interesting and meaningful representation in many cases.
- Graph Analysis queries: these are queries that look at some really interesting graph metrics that could help us better understand our HR network. There are some really interesting measures out there, like for example degree centrality, betweenness centrality, pagerank, and triadic closures. Below are some of the queries that implement these (note that I have done some of these also for the Dolphin Social Network). Please be aware that these queries are often times “graph global” queries that can consume quite a bit of time and resources. I would not do this on truly large datasets – but in the HR domain the datasets are often quite limited anyway, and we can consider them as valid examples.
//Degree centrality
match (n:Person)-[r:FRIEND_OF]-(m:Person)
return n.first_name, n.last_name, count(r) as DegreeScore
order by DegreeScore desc
limit 10;
//Betweenness centrality
MATCH p=allShortestPaths((source:Person)-[:FRIEND_OF*]-(target:Person))
WHERE id(source) < id(target) and length(p) > 1
UNWIND nodes(p)[1..-1] as n
RETURN n.first_name, n.last_name, count(*) as betweenness
ORDER BY betweenness DESC
//Missing triadic closures
MATCH path1=(p1:Person)-[:FRIEND_OF*2..2]-(p2:Person)
where not((p1)-[:FRIEND_OF]-(p2))
return path1
limit 50;
//Calculate the pagerank
UNWIND range(1,10) AS round
MATCH (n:Person)
WHERE rand() < 0.1 // 10% probability
MATCH (n:Person)-[:FRIEND_OF*..10]->(m:Person)
SET m.rank = coalesce(m.rank,0) + 1;
I am sure you could come up with plenty of other examples. Just to make the point clear, I also made a short movie about it:
The queries for this entire demonstration are on Github. Hope you like it, and that everyone understands that Graph Databases can truly add value in an HR Analytics contect.
Feedback, as always, much appreciated.
Rik
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles


Find Similar Patient Journeys With Neo4j Aura Graph Analytics
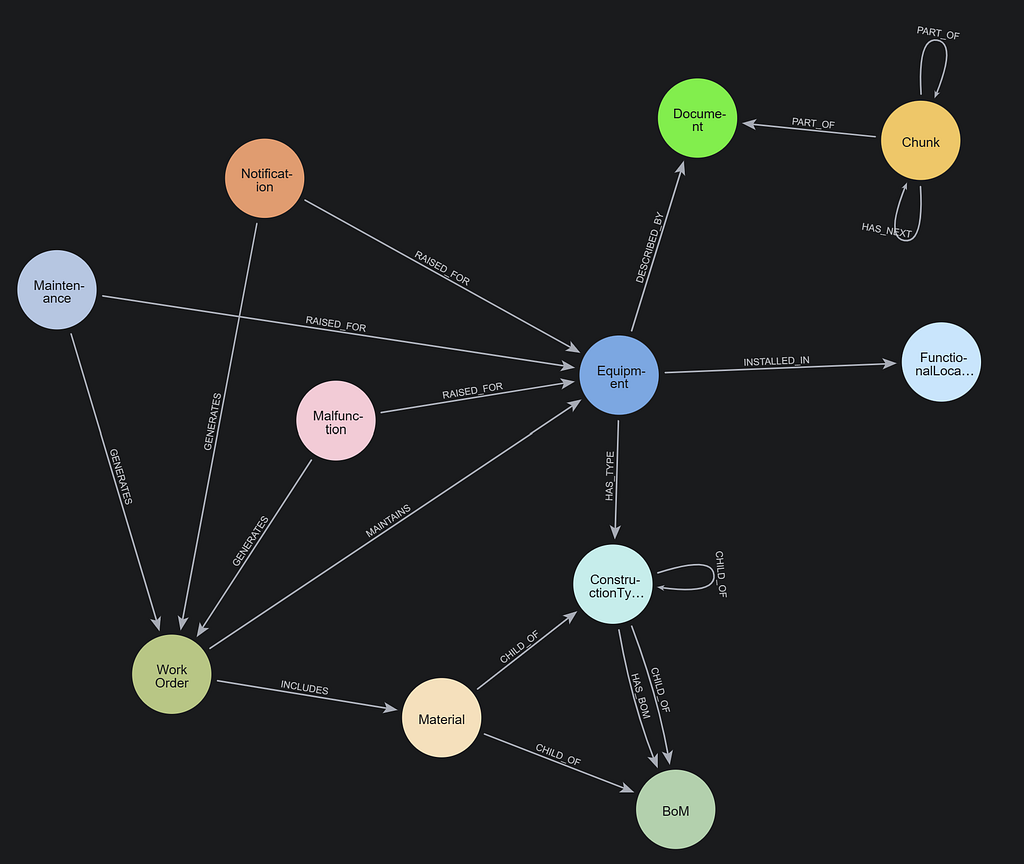
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It