
Uber Powers Cross Domain Config Validation With Neo4j Graph Intelligence
Uber’s Config Knowledge Graph supports validation of onboarding related business configurations
7
Business domains onboarded, spanning critical areas of Earner onboarding
27
critical cross-domain config safeguards added by domain teams

A driver in Paris completes Uber’s onboarding process: background checks passed, vehicle registration submitted, hours invested. Yet no ride requests arrive. The vehicle meets onboarding requirements, but doesn’t meet dispatch rules for premium products in that market. The driver loses the opportunity, and Uber loses a potential customer.
With 8 million+ earners across Uber’s platform, even small configuration mismatches compound into millions in lost opportunity and customer dissatisfaction. A mismatch between how onboarding defines “qualified driver” and how dispatch assigns rides can leave approved drivers stranded without passengers, making configuration alignment critical.
Today, Uber’s Config Knowledge Graph on Neo4j works on preventing conflicts before they happen.
When Configuration Becomes Crisis
Uber’s microservices architecture allowed the business to grow fast. It also created what Senior Staff Engineer Vignesh Murugesan calls “configuration sprawl”: 3,000+ microservices and 3,500+ feature-flag namespaces across 15,000+ cities with unique rules and regulations. Each team maintained its own configuration behind APIs, creating isolated silos of business logic.
Consider one rule: Uber Comfort in NYC requires vehicles newer than five years. This requirement spans three separate systems. The Onboarding service collects vehicle registration. Documents service extracts the manufacturing year. Dispatch enforces product eligibility. When these systems misalign, drivers get caught in the gap.
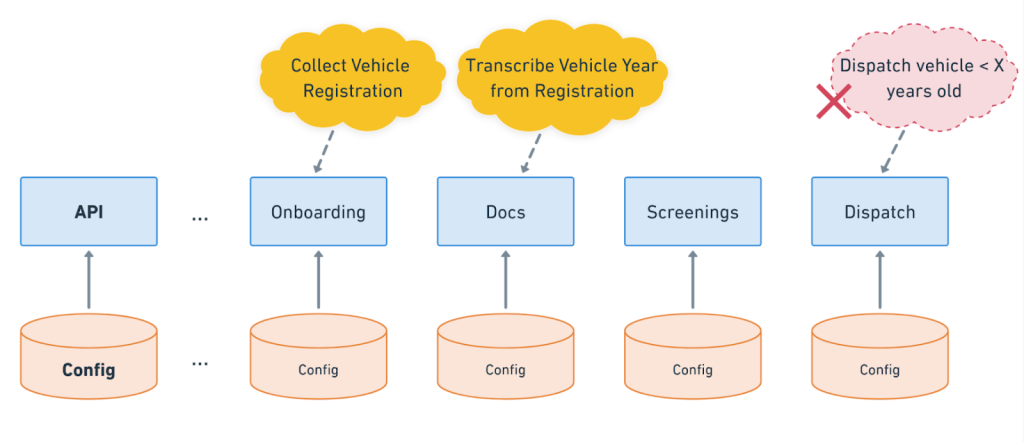
Above: Uber’s Onboarding, Docs, Screenings and Dispatch services
Document-based RAG systems could retrieve text chunks, but couldn’t traverse relationships between configuration entities. They treated each configuration as isolated text rather than interconnected business logic.
“We tried modeling this using SQL,” Murugesan explains. “It exploded in complexity.” A simple validation query became a maze of recursive common table expressions (CTEs), self-joins, and nested subqueries. Key-value stores required multiple network round trips for each relationship traversal. Document databases forced data duplication, creating consistency nightmares.
Neo4j’s graph intelligence platform offered a different approach. The Neo4j knowledge graph gives AI agents directly traversable relationships they can explore incrementally. Instead of constructing complex queries, agents navigate the graph like a map, building contextual understanding as they query the data.
“The choice of using a knowledge graph had the biggest impact on accuracy of LLM queries on the knowledge graph, way more than what we could do with prompt engineering,” Murugesan shares. The graph transforms configuration from isolated data points into navigable knowledge that humans and machines understand.
Building on Google Cloud With Neo4j AuraDB
Uber deployed Neo4j AuraDB on Google Cloud Platform. The architecture uses GCP infrastructure with vector indices enabling semantic search capabilities that AI agents use to find similar configurations and patterns.
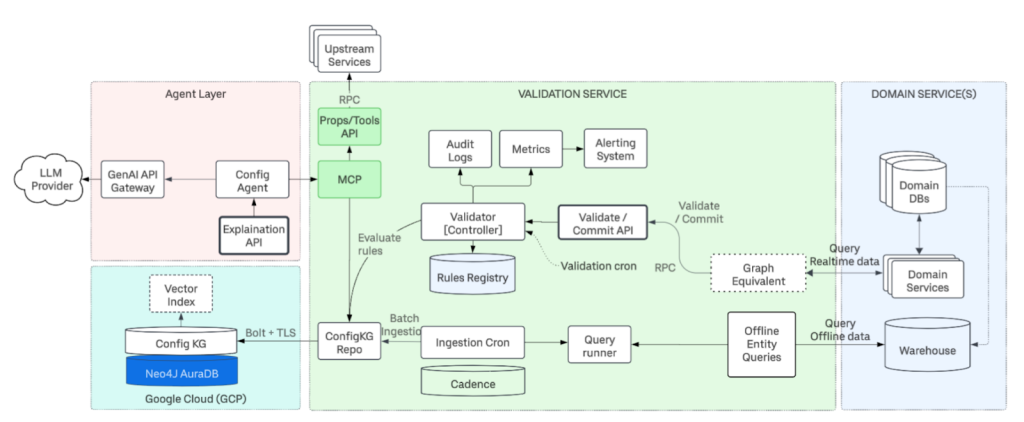
A team of just two engineers built this production-ready infrastructure in under twelve weeks. Neo4j AuraDB handles scaling, backups, and availability, letting the team focus on business logic.
“ACID compliance is critical because tens of changes are being made across the system and we want validation isolated from each other,” states Murugesan.
A database that is ACID-compliant ensures that all transactions are processed as single, complete units, preventing corruption even during system errors or crashes. Each proposed change to Uber’s graph runs within its own transaction. If validation fails, everything rolls back, leaving the graph consistent.
“Graph DBs are a natural way to express interconnected config data,” Murugesan concludes. “The simplicity extends from humans to LLMs.”
The graph model now mirrors Uber’s reality. Nodes represent real entities: OnboardingGraph for driver requirements, DocumentType for paperwork, BGCTrigger for background checks. Edges capture relationships: REQUIRES links onboarding to documents, EVALUATES connects triggers to checks, CAN_LAUNCH_IN maps products to cities. Business rules become traversable paths. Asking “What documents does a Boston driver need for Uber Comfort?” translates to simple graph traversal.
Navigating the Knowledge Graph
Uber exposes the Config Knowledge Graph via MCP (Model Context Protocol) for users and LLMs to query.
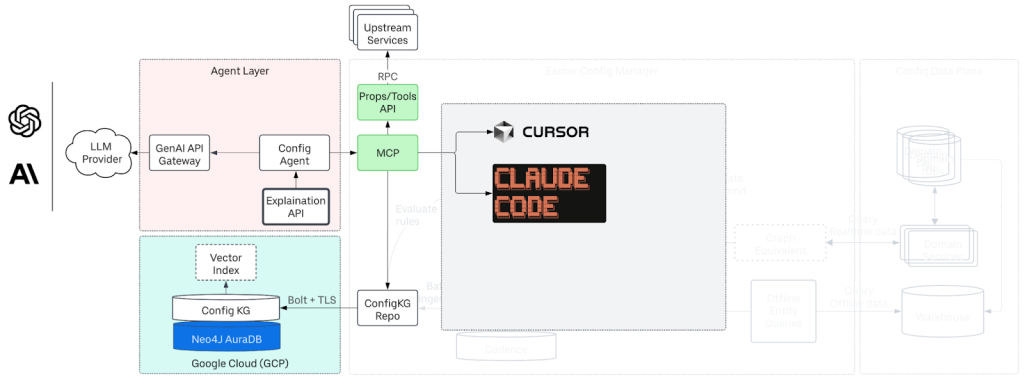
Above: Engineers access the MCP server from development tools or from the command line interface (CLI)
“Developers who work in one domain can naturally probe and explore adjacencies,” notes Murugesan. Graph makes relationships explorable, providing navigable context. New applications can plug in without disrupting existing ones. Each specializes while sharing a foundational knowledge graph.
Validation rules prevent cross-domain conflicts before reaching production. Neo4j’s index-free adjacency means traversing from city → products → requirements → documents happens in milliseconds.
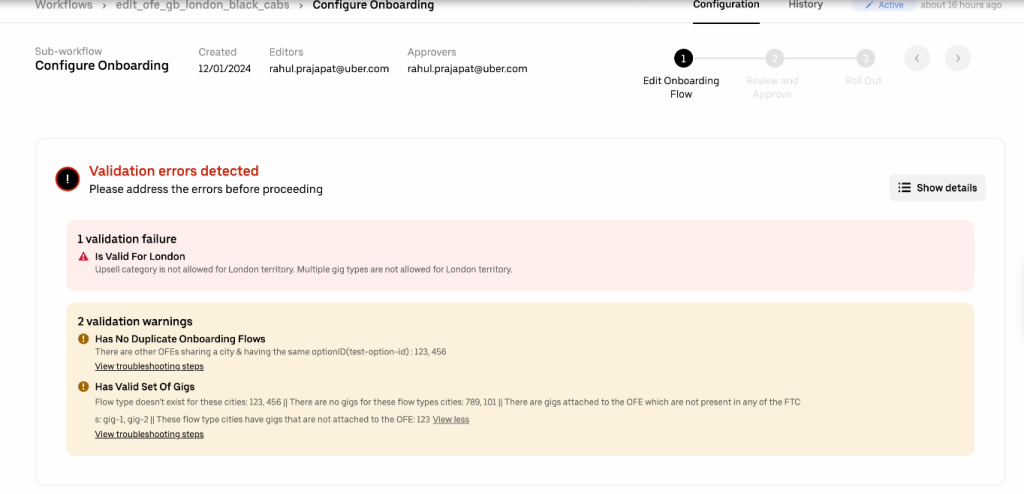
Above: The Uber configuration service detects and flags a validation error
In the future, configuration agents could even automate actions. They can accept high-level intent (“Launch Comfort Electric in Boston”), query the graph for dependencies, identify configurations needing updates across services and draft the complete changeset.
Above: Uber’s Northstar: A seamless, automated configuration experience
Every automated query could save hours that engineers can spend building. Each successful configuration means thousands of drivers earning livelihoods and millions of riders reaching destinations.
-
 Google Cloud Platform
Google Cloud Platform