A Comprehensive Guide to Cypher Map Projection

CTO at SmartGrid Communications Inc.
6 min read


Cypher is a visual graph query language used by the Neo4j graph database. It lets you write very precise pattern matching queries like:
MATCH (movie:Movie {title: “The Matrix”})
<-[:ACTED_IN]-(person:Person)
WHERE person.born > 1960
RETURN person
This returns the people who acted in the movie “The Matrix&rdquo and were born after 1960.
But a lesser known feature also allows you to determine with equal precision what gets returned by the queryin in a JSON format similar to a GraphQL output. This post is all about this fantastic feature.
The “Classical” Return Statement and Its “Drawbacks”
Let’s start from a very simple example:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie
If you run this query, you’ll get a node object whose representation looks like the following (this is the result as displayed in the Neo4j Browser – you may have different results if running the query through a specific driver):
{
"identity": 0,
"labels": [
"Movie"
],
"properties": {
"tagline": "Welcome to the Real World",
"title": "The Matrix",
"released": 1999
}
}
That’s fine, but maybe your application does not need the tagline? It’d be better to exclude this field in order to reduce the size of data transferred. Then you can replace the preceding return statement with:
RETURN movie.title, movie.released
The result here is quite different: instead of a single column containing a JSON element, you end up with a two-column result:
╒═════════════╤════════════════╕
│"movie.title"│"movie.released"│
╞═════════════╪════════════════╡
│"The Matrix" │1999 │
└─────────────┴────────────────┘
Now, imagine you also want to retrieve the actors involved in this movie in the same query – you have to write:
MATCH (movie:Movie {title: “The Matrix”})
<-[:ACTED_IN]-(person:Person)
RETURN movie.title, movie.released, person.name
which returns a table with a lot of duplicated information:
╒═════════════╤════════════════╤════════════════════╕
│"movie.title"│"movie.released"│"person.name" │
╞═════════════╪════════════════╪════════════════════╡
│"The Matrix" │1999 │"Emil Eifrem" │
├─────────────┼────────────────┼────────────────────┤
│"The Matrix" │1999 │"Hugo Weaving" │
├─────────────┼────────────────┼────────────────────┤
│"The Matrix" │1999 │"Laurence Fishburne"│
├─────────────┼────────────────┼────────────────────┤
│"The Matrix" │1999 │"Carrie-Anne Moss" │
├─────────────┼────────────────┼────────────────────┤
│"The Matrix" │1999 │"Keanu Reeves" │
└─────────────┴────────────────┴────────────────────┘
The movie’s title and release date are repeated as many times as the number of actors in the movie! So, what can we do to avoid these repetitions and always return a consistent data type?
Using Map Projection
Map projection is a Cypher feature inspired by GraphQL. If you don’t know GraphQL, the only relevant characteristic here is the ability to customize the return fields for each query.
With Cypher, you can hence write:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {.title, .released }
This query returns a single row with a single column named movie which contains a nicely formatted JSON:
{
"title": "The Matrix",
"released": 1999
}
You can also use the wildcard * if you want to retrieve all properties of a given node, like this:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {.* }
“Collecting” Results in a Single Array
What if we have several movies matching the query? If we write:
MATCH (movie:Movie)
RETURN movie { .title, .released }
we end up with a result containing several rows, each of them similar to the above object. If you want a single JSON array, you can use collect :
MATCH (movie:Movie)
RETURN collect(movie { .title, .released })
This time, we get an array of JSON elements similar to:
[
{
"title": "The Matrix",
"released": 1999
},
{
"title": "The Matrix Reloaded",
"released": 2003
},
....
]
That’s already a nice result! But let’s go ahead and include the actors.
Traversing Relationships
We now want to retrieve the person who acted in a given movie. This is achieved thanks to the following MATCH statement:
MATCH (movie:Movie {title: "The Matrix"})
<-[:ACTED_IN]-(person:Person)
Collecting Traversed Relationships
Inside the map projection, you have access to previously MATCHed elements, like movie and person :
MATCH (movie:Movie {title: "The Matrix"})
<-[:ACTED_IN]-(person:Person)
RETURN movie {
.title,
actors: collect( person { .name } )
}
In this new syntax, we add a new key called actors in the final result. The value is built by collecting all matched person for a given movie and extracting their property called name (as we did in the previous example retrieving several movies):
{
"title": "The Matrix",
"actors": [
{
"name": "Emil Eifrem"
},
{
"name": "Hugo Weaving"
},
{
"name": "Laurence Fishburne"
},
{
"name": "Carrie-Anne Moss"
},
{
"name": "Keanu Reeves"
}
]
}
Ok, but what if the objects we want to retrieve are not in the MATCH statement?
Traversing Relationships in the Projection (Local Scope)
That’s not a problem, since map projection also has the ability to understand patterns. The preceding query is hence equivalent to the following one:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {
.title,
actors: [(movie)<-[:ACTED_IN]-(person:Person)
| person { .name }
]
}
In the preceding example, we’ve used Cypher list comprehension to parse the result. The bold part of the query actually means: “find all persons who acted in movie and for each of them, extract her name”. The result of this query is strictly identical to the result of the preceding query (the order in which the persons are returned is not guaranteed).
Extracting Relationship Data
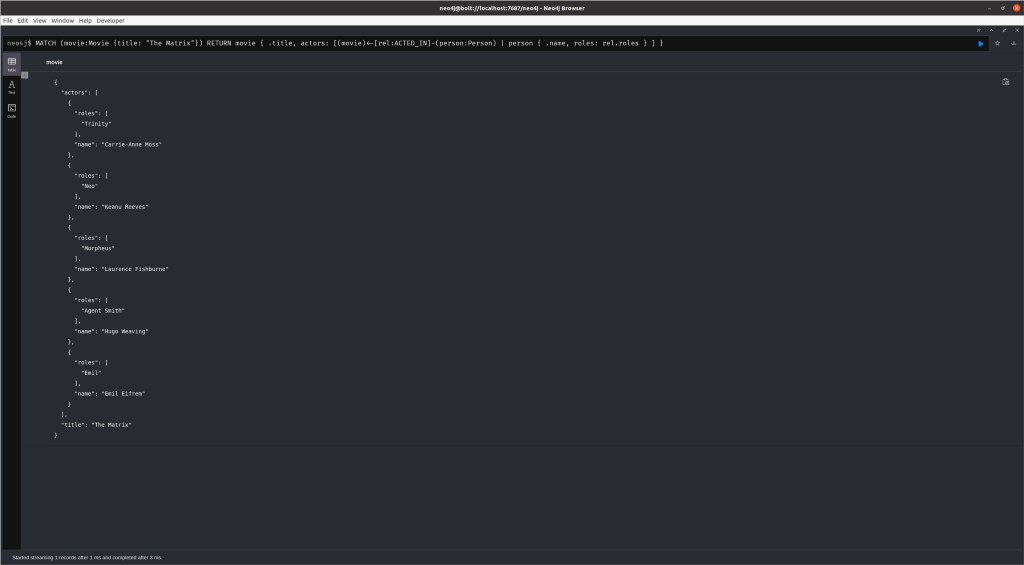
Similarly to the way we retrieved related node data for Person , we can extract relationship properties. In the following query, we’re extracting the roles property of the ACTED_IN relationship between a person and a movie:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {
.title,
actors: [(movie)<-[rel:ACTED_IN]-(person:Person)
| person { .name, roles: rel.roles }
]
}
Limiting Results With WHERE Clause
With normal Cypher, we can add constraints on the related nodes using WHERE conditions:
MATCH (movie:Movie {title: "The Matrix"})
<-[:ACTED_IN]-(person:Person)
WHERE person.born > 1965
RETURN movie, person
This is also doable in a map projection, like this:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {
.title,
actors: [(movie)<-[:ACTED_IN]-(person:Person)
WHERE person.born > 1965
| person { .name }
]
}
In both cases, the result will only contain the actors whose date of birth is greater than 1965.
Pagination: Order by, Limit, Skip (or Offset)
We would like to be able to write:
MATCH (movie:Movie {title: “The Matrix”})
RETURN movie {
.title,
actors: [(movie)<-[:ACTED_IN]-(person:Person)
WHERE person.born > 1965
ORDER BY person.born LIMIT 1 SKIP 2
| person { .name }
]
}
However, as of March 2022 and Neo4j 4.4, this is not (yet?) possible.
The good news is that we can achieve similar result using the APOC plugin, and more specifically the apoc.coll.sortMaps function that will sort a list of maps based on a specific key, “born” in this example:
MATCH (movie:Movie {title: "The Matrix"})
RETURN movie {
.title,
actors: apoc.coll.sortMaps(
[
(movie)<-[:ACTED_IN]-(person:Person)
| person {.name, .born }
],
"born"
)[0..3]
}
The final [0..3] selector lets us return only the first three actors, sorted by date of birth.
When to Use Map Projection?
I introduced map projection in a GraphQL context, making it easier to take full advantage of GraphQL queries by fetching only the required fields from the database (they do not have to transition through another layer of filtering in your backend). But another application of this concept that I like is the ability to write “Object-Graph mappers” (OGM) in an easy way. You can even imagine having a graph schema different from your “domain” schema, and still building proper objects thanks to map projection. Here is an example graph schema featuring products and categories:

With the following Product model containing information about the category it belongs to, you can use map projection in the get_products function in order to build Product objects with all their fields:
NB: in the previous example, I considered a product belongs to only one category, for the sake of simplicity. Feel free to adapt the example for a multiple category case, for instance by changing the type of Product.cateogry to list[str].
Conclusion
That’s all folks! I hope this helped you better understand what map projection is and when it can be useful!
References
- New Cypher Features Inspired by GraphQL [Neo4j 3.1 Preview]
- Cypher map projection documentation
- APOC documentation
- GraphQL, a query language for your API
- The Neo4j Python driver
A Comprehensive Guide to Cypher Map Projection was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Declarative Route Planning With Cypher 25 — Graph Traversal Grows Up
Streamline Data Ingestion With the Neo4j Aura Import API



Find Similar Patient Journeys With Neo4j Aura Graph Analytics