


Benchmarking Using the Neo4j Text2Cypher (2024) Dataset

Machine Learning Engineer, Neo4j
3 min read

Authors: Makbule Gulcin Ozsoy, Leila Messallem, Jon Besga
In our previous post (Introducing the Neo4j Text2Cypher (2024) Dataset), we introduced the new Neo4j Text2Cypher (2024) Dataset and took an in-depth look at it.
Here, we’ll dive into how various previously fine-tuned and foundational LLM-based models perform on it for translating natural language questions to Cypher queries.
Let’s see how these models stack up!
Models Used
After diving into resources like HuggingFace (HF) models and academic papers, we uncovered four fine-tuned models and 10 foundational models (e.g., GPT-4o, CodeLlama) that stood out as strong candidates for comparison and benchmarking. These models, highlighted in the figure below, will be the focus of our analysis as we explore their performance side by side.
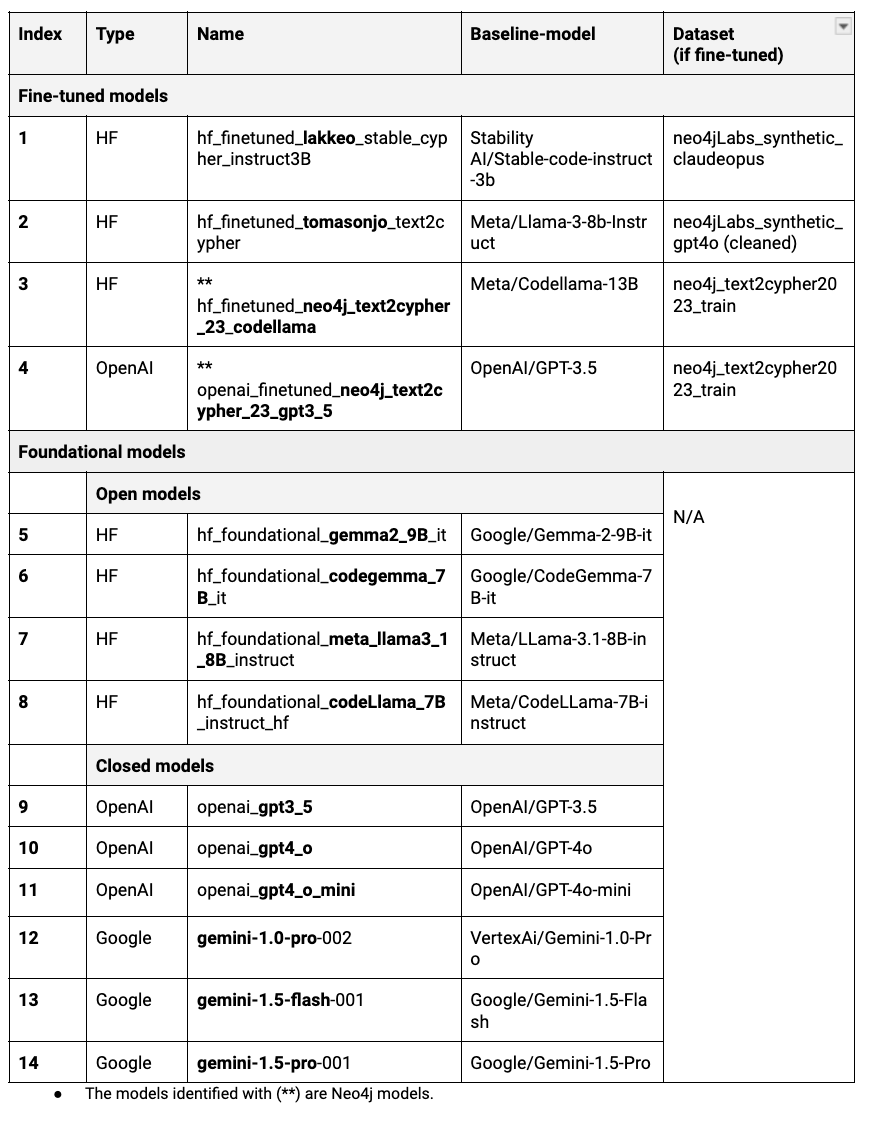
For benchmarking the models, we used the test split of the Neo4j Text2Cypher (2024) Dataset. Where applicable, we used the following instructions (from LangChain Cypher Search: Tips & Tricks):

Evaluation Metrics
To evaluate the performance of the Text2Cypher translation task, we used the following metrics:

We introduced two evaluation procedures:
- Translation — This approach compares the predicted Cypher queries to the reference queries based purely on their text, followed by applying the evaluation metrics mentioned above.
- Execution — This approach runs the Cypher query on the target database and collects the execution results. Once the execution outputs from both the predicted and reference Cypher queries are collected, they are converted to strings (using the same order and format). We then apply the same evaluation metrics as in the translation approach.
Both methods help us assess the performance of the predictions.
Evaluation Results
While all metrics were calculated, this post focuses on the Google BLEU score for translation-based evaluation and ExactMatch for execution-based evaluation. The evaluation results of the models are presented in the figure below. The best-performing models:
- Execution-based evaluation:
– ‘OpenAI/Gpt4o’ and ‘HF/tomasonjo_text2cypher’
– Both of these models achieve about 30 percent of match ratio.
– Note that ExactMatch is a very sensitive metric, which is impacted by simple changes like a newline or an extra space. - Translation-based evaluation:
– Closed-foundational: OpenAI/Gpt4o, OpenAI/Gpt4o-mini and Google/Gemini-1.5-Pro-001
– Open-foundational: Google/Gemma2–9B-It
– Fine-tuned: HF/tomasonjo_text2cypher

The closed-foundational models delivered the best overall performance. While they are easy to use through their dedicated APIs, they can be costly. Although fine-tuned models (i.e., fine-tuned with a different dataset) may not perform as well as closed-foundational models, they demonstrate that performance can be improved through techniques like fine-tuning.
Summary
With our newly released Neo4j Text2Cypher (2024) Dataset, we explored how various fine-tuned and foundational LLM-based models perform in translating natural language questions to Cypher queries.
The results? The closed-foundational models — like OpenAI’s GPT and Google’s Gemini — showed strong performance, with user-friendly APIs and reliable output, though they can be costly. Previously fine-tuned models haven’t quite matched the giants, but they demonstrate real potential. We’re just getting started, and while we haven’t surpassed these top-tier models, our initial results hint at significant potential. Further comparisons remain open for exploration.
Be sure to check out our next blog post, where we’ll explore the performance of fine-tuned models and share the results using the same dataset.
Benchmarking Using the Neo4j Text2Cypher (2024) Dataset was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles


Everything a Developer Needs to Know About the Model Context Protocol (MCP)
25 min read

A Practical Experimentation of GraphRAG and Agentic Architecture With NeoConverse
13 min read
Graphiti: Knowledge Graph Memory for a Post-RAG Agentic World
5 min read