Maximising Efficiency: The Power of ChatGPT and Neo4j for Creating and Importing Sample Datasets

Customer Success Manager
3 min read


As a Customer Success Manager at Neo4j, I work with customers on a daily basis, helping them achieve their business goals with graph technology.
Our Customer Success Architects spend time reviewing data models, tuning queries, and outlining approaches to optimize their solutions. However, one challenge we often face is access to their data. Reviewing the data model is often possible, but accessing usable data is not always possible.
Can ChatGPT help me to create a set of usable sample data and import it into Neo4j?
Use Case and Data Model
I’ll start with a simple banking data model, where account holders are making transactions between other accounts.

ChatGPT
I knew I wanted to use Visual Studio Code to “write” my scripts and node.js to run them, as I am familiar with both of these. But let’s assume I’m not — can ChatGPT get me started from almost nothing?

Okay, this looks like a promising start.
The First Scripts
I started simply to see what I could achieve, and was also fairly explicit in what I wanted the data to look like…

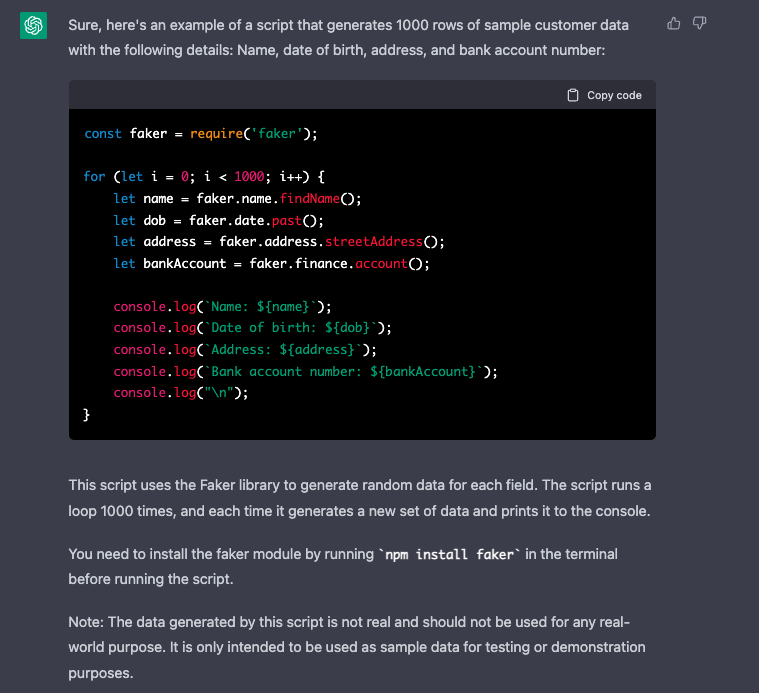
Making a number of revisions to this within the same conversation thread, it’s impressive how the key information is retained throughout the conversation.
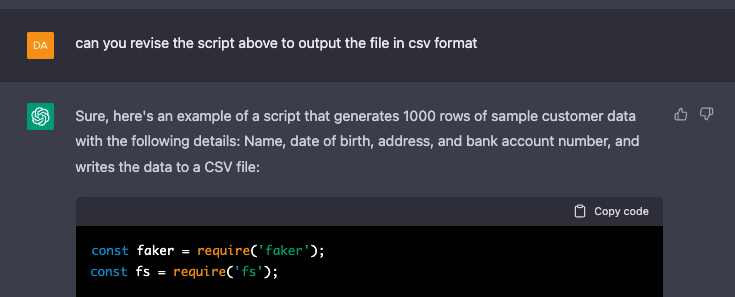
Adding Transactions


What I found impressive here is that I no longer had to ask for the output to be written to a CSV file — it was already included for me
But I have a problem, not with ChatGPT, but with how I’ve approached my scripts — there is no relationship between my random accounts and my random transactions. Thanks to a chat with my colleague (Thanks James!), I realized you still need to have some level of understanding of how the script needs to be structured to get the correct results.

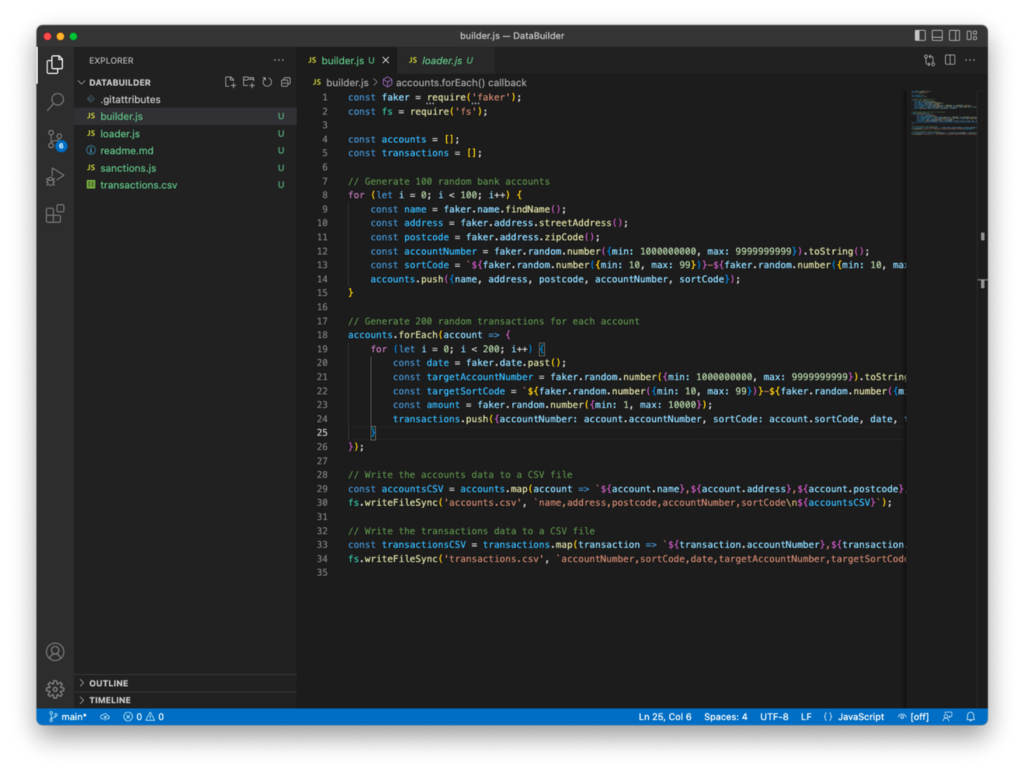
Importing into Neo4j
I looked at two options here, a packaged node.js script to import directly into my local instance of Neo4j and the simple Cypher scripts to import using Neo4j desktop.
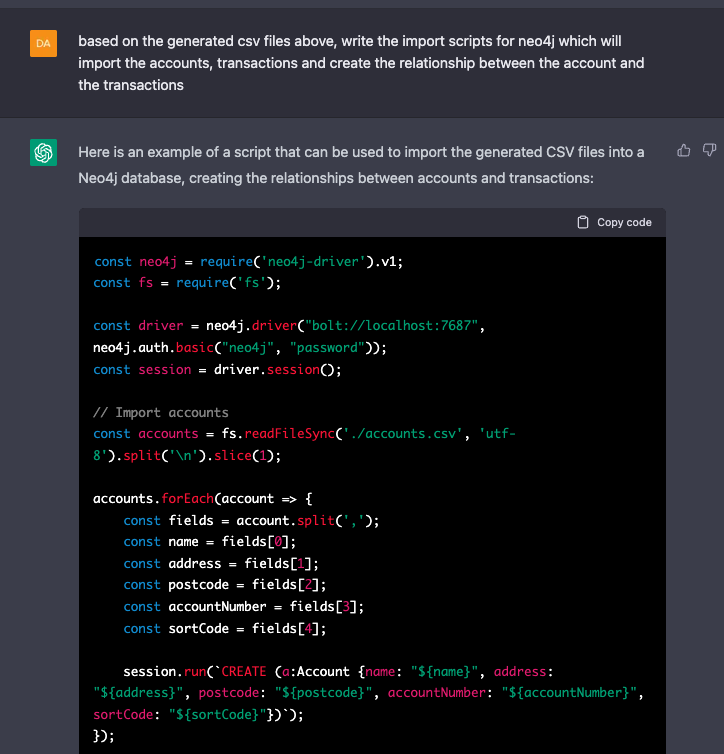
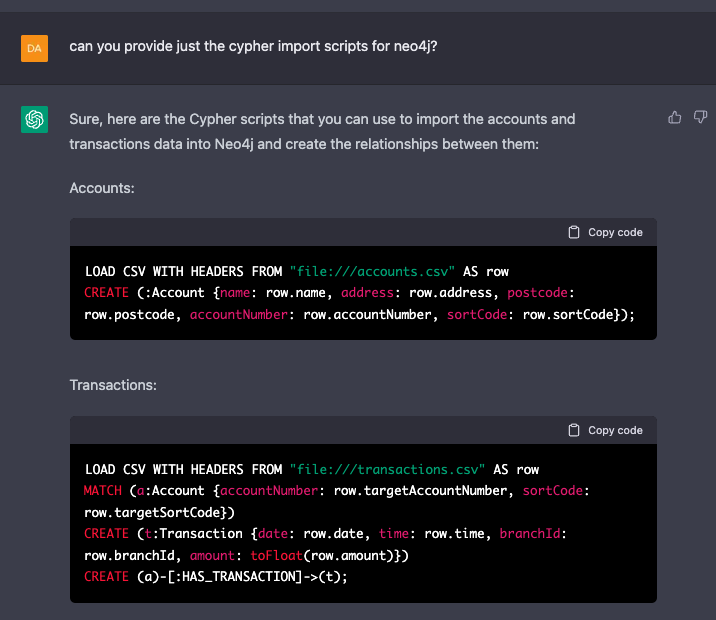
Some Minor Rework
Before importing into Neo4j, I did take some steps of my own, as I knew importing such a large dataset (I had over 1 million sample transactions) without having any indexes in place wasn’t going to work well.
I also updated the larger of the two imports (transactions) to use PERIODIC COMMIT to import as a batch of 1000 rows from the CSV file. The final update was to revise the relationship information to match my target data model.
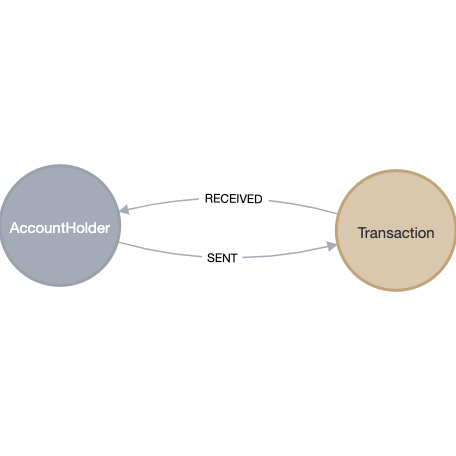
The Results
The sample data loaded without any issues into my Neo4j instance, and the generated schema and a snapshot are shown below.

Conclusion
The current dataset is fairly simple and I could have (if given the time) written the scripts myself, but the speed at which I was able to turn this around is impressive — there is no more than one hour of work here!
However, I think it’s imperative to note that while ChatGPT delivers amazing results, there is still an underlying need for some knowledge of the systems and processes being used. This is from a base understanding of programming to some of the finer details of Neo4j and graph data structures. ChatGPT is very powerful at refining and revising the generated output, but you need to know the areas where improvements can be made.
Next steps for this project are to review the dataset with Cypher and the Graph Data Science library from Neo4j and see if any interesting patterns have been generated, such as potential mule accounts (of course with ChatGPT alongside).
The generated scripts are available on my GitHub account here.
Maximising Efficiency: The Power of ChatGPT and Neo4j for Creating and Importing Sample Datasets was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Find Similar Patient Journeys With Neo4j Aura Graph Analytics
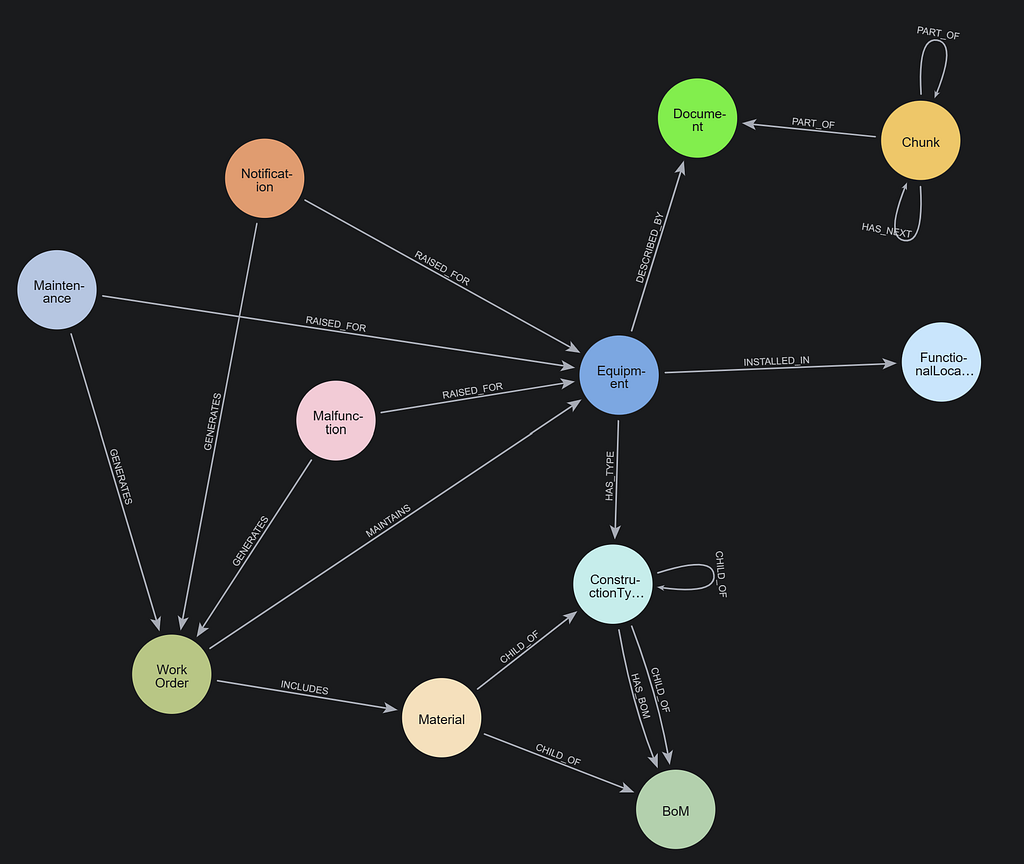
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It