



The dream of artificial intelligence (AI) has accompanied our society since the pervasive advent of the digital age.
Existing Approaches
Different approaches have been adopted throughout the years to model different aspects of intelligence. And other models have, instead, been developed to integrate intelligent capabilities simulations to build technological artifacts that exhibit a certain degree of flexibility.
While the ability to communicate has always been associated with intelligence, it is only in recent years that new technologies have made possible a vast diffusion of voice-activated devices.
As in many other fields, it has been the exponential growth in the performance of neural networks, powered by the availability of higher computational power, that has changed the perspective on the field of Natural Human-Machine Interaction (HMI).
This, however, comes with a price: first of all, neural models need a humongous amount of data to reach their performance, thus becoming more and more exclusive to build. They are also hard to interpret, thus posing an explainability problem, which is currently investigated, for example, with probing methods.
The same technological advances that power the race towards machine learning models, however, can actually be used to improve approaches coming from old-school AI, which were undoubtedly rigid, often being rule-based. But this also had the advantage of always providing clear explanations for their behavior.
Combined Model
An attempt to recover positive aspects of older approaches to AI can be made by leveraging modern computational power and relaxing rigid rule-based systems by mixing some statistics in them. This hybrid method, which has been gaining attention recently, avoids a one-wins-all approach to computational model selection for complex behavior simulation and intends to take the best out of multiple models, harmonizing them in such a way that the right tool is used for the right task in an explainable way.
Framework for Natural Tools and Applications With Social Interactive Agents (FANTASIA)
The Framework for Natural Tools and Applications with Social Interactive Agents (FANTASIA) was built upon this concept, and we will talk about it in Part 2 of this article. Here, I will concentrate on how Neo4j supports cross-disciplinary research between technology and humanities researchers.

In this article, I will describe the research conducted in the field of Embodied Conversational Agents (ECAs) at the URBAN/ECO Research Centre of Federico II University in Naples.
Interactive Graph of Knowledge With Neo4j
In particular, I will describe how Neo4j helps bring the massive amount of information possessed by humanities researchers inside technological frameworks for Real-Time Interactive 3D applications (RTI3D) powered by the Unreal Engine.
Being a very natural way to represent data, researchers from fields like linguistics, art history, or architecture easily acquire the basic concepts needed to interpret their data, research procedures, and make conclusions as graphs. Moreover, Neo4j makes graph database technology accessible to create, modify, and query graph data, so that humanities knowledge can easily be represented and investigated inside a framework that lets, at the same time, computer scientists enrich those representations with algorithmic approaches.
For the specific case of linguistics research, graph structures offer the possibility to cross-reference encyclopedic knowledge sources with dialogue corpora, thus jointly representing domain knowledge and the way people communicate about it.
Interdisciplinary Collaboration
Interdisciplinary research can then be conducted with a mutual exchange, as computer scientists add new perspectives to the data using graph data science for linguists to exploit, and at the same time, use analyses conducted by linguists for explainable AI design. Collaboration among groups with different needs and expertise is a classic application case of Neo4j: in our case, graph-based approaches to cross-disciplinary research help computer scientists design dialogue systems, and they bring new tools to humanities researchers, who are directly involved in the interaction design process, rather than just being content providers.
It is worth noting that the presence of humanities researchers is particularly precious to building explainable-by-design systems. These are of interest to the academic community, as they allow testing theoretical models to check if they adequately describe dialogue dynamics, updating an investigation strategy that was popular with logical engines. This also has long-term implications for the industry though, as explainable-by-design systems typically need less data and computational power to work, as only some parts are built by relying on machine learning.
Studying Dialogues With Graphs
From a methodological point of view, analyzing dialogues concerning the domain of interest is the foundational part of the building process of ECAs we adopt.
The goal is to represent how people talk about the domain of interest, preferably in the same context where the ECA should operate. Knowledge graphs are a popular choice to represent domain information supporting technological applications and dialogue-based applications are often based on knowledge graphs, so it is useful to use them to represent and study the relationship between how people make use of the domain during human-human dialogues.
This supports modeling how a machine should mimic their behavior. Explainable-by-design systems do not rely only on machine learning to make these strategies emerge so it is important to cross-reference recorded dialogues with the background knowledge concepts they use. One of the case studies we adopt to explore how linguistics research methods can be directly linked to ECAs development is the movie recommendation task.
This has been deeply explored, in the past, and there are a lot of available resources on which to test data collection, annotation and analysis. In our case, our ongoing work aims at formalizing a methodology to organize both data and linguistic knowledge as graphs connecting multiple resources, to extract more information from the combination of the resources. We refer to this methodology as “Linguistically Oriented Resources and Insights as Expressive Graphs” (LORIEN).
Data Sources
Typically, we start by importing common knowledge from Linked Open Data (LOD) sources, using Wikidata as a starting point. Alternative sources are, then, cross-referenced with the Wikidata graph to support bridging and analyses. In the movie recommendation domain, we extract movies, people that worked in those movies, the genres they belong to, the awards they won and the people they were awarded to.
This subgraph represents what, in linguistics, is referred to as the Communal Common Ground (CCG): the set of background knowledge that is possessed by people belonging to a community. Briefly, it represents encyclopedic knowledge about the domain that can be considered objective and generally available. Next, we import human-human movie recommendation dialogues coming from the Inspired corpus¹, representing utterances, in each dialogue, as nodes and linking them through relationships chains.
Linking Utterances to the Common Ground
Also, we link the utterances to the elements of the CCG they refer to. Since dialogues collected from a corpus of actual Human-Machine interactions cannot be considered common domain knowledge, they represent the Personal Experience (PE) the system has about dialogue management in the domain of interest. The dialogues sub-graph, once again, corresponds to a linguistic concept to support theoretical explainability of the model and, later, of the application behavior. A simplified extract of the graph is shown in the Figure.
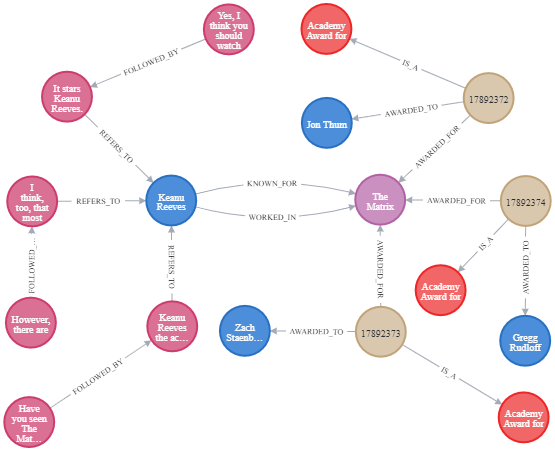
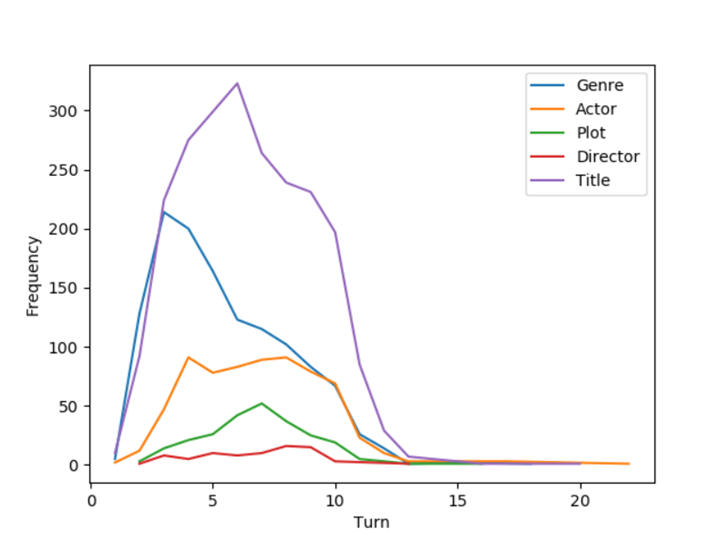
With such a structure, it is possible to jump between the collected dialogues and the CCG to explore more deeply the dialogue strategies followed by the parties involved in the Inspired corpus. First of all, it is possible to analyze the use of CCG items throughout the dialogues to extract some interesting patterns. From the following Figure, for example, it can be observed that people, in the first phases of the dialogue, tend to talk more about genres than they do in the latest parts.
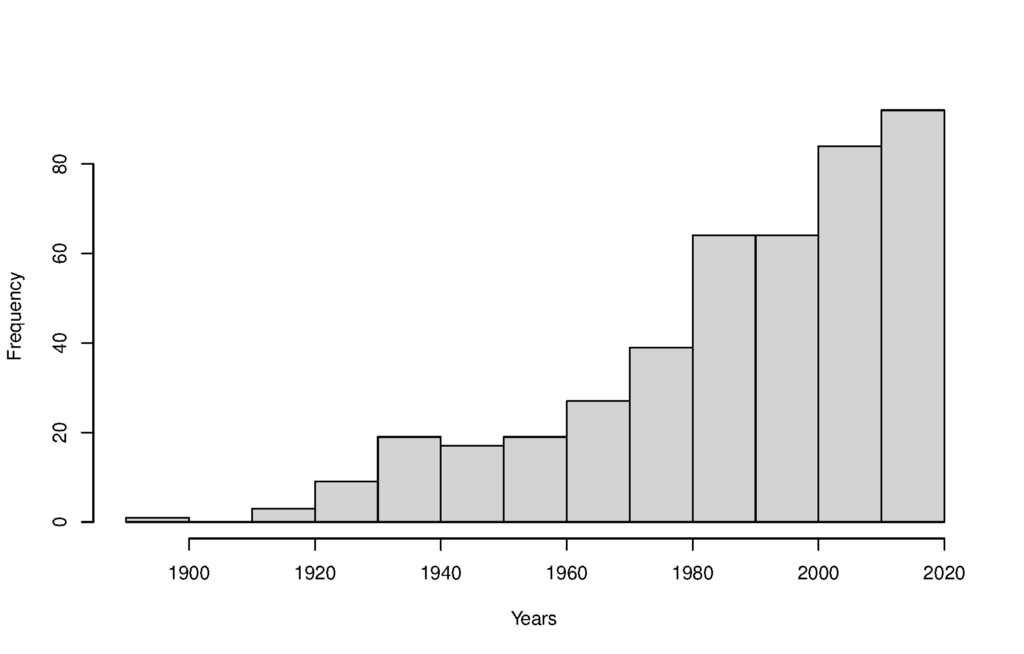
Another interesting pattern that emerges from the resources cross-referencing is that people tend to talk about recent movies, as shown in the following Figure.
These, in general, are intuitive strategies as restricting the search field by focusing on categories first and talking about recent movies are natural choices but having a machine automatically adopt these strategies by itself is not trivial.
You should consider, in fact, that we are not interested in the movie recommendation task per se, but rather on the general dialogue management strategies that hold independently of the domain.
We do not seek to solve the movie recommendation task alone: we rather investigate the underlying dialogue management mechanisms that let domain-specific strategies emerge. Our goal is to find the general principles that would let a conversational agent move through the domains with minimal reconfiguration effort.
Contextual Information
In linguistics, many concepts are context-dependent, meaning that the same utterance may have different meaning or even be understandable depending on how the dialogue has been evolving. By connecting dialogues and the CCG, it is possible to adopt disambiguation strategies by considering the sub-graphs representing interactions up to the point of interest.
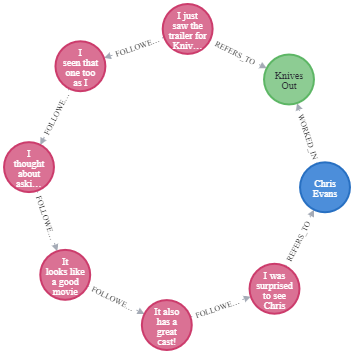
For example, in the case of movies, the CCG built from Wikidata contains more than a hundred people named Chris Evans so, when a person refers to a Chris Evans, performing entity linking becomes easier if we consider that, a few turns before, people were talking about Knives Out, in which Chris Evans appeared.

This kind of ring-like pattern, shown in the following Figure, can be used for disambiguation or to investigate more in depth dialogue dynamics and understand how people are using the domain to negotiate a common set of shared beliefs, which is called Personal Common Ground (PCG). You can find out more about how this database was built and analyzed in the dedicated paper².
Graph Analysis Processing
LORIEN is meant to extend research methods based on corpus linguistics by introducing a set of analysis tools that draw from graph theory to support better understanding of dialogue dynamics.
After the data representation step, graph analysis tools allow to find regularities that can be exploited both to form new background theories and to support technological approaches built upon them.
For the case of the movies, for example, after detecting that people talk about genres in the first phases of the dialogue, we perform network analysis with the HITS algorithm, implemented in the Neo4j Graph Data Science library, to discover which network characteristics genre nodes have that can explain why they are preferred in that phase.
Since nodes representing genres emerge from the network as having a very high authority score, this suggests the general dialogue management principle that, while collecting information about the interlocutor, their position concerning authoritative nodes should be discovered first. Other information comes from sources like Movielens, to estimate how popular movies are for the general public or IMDB for catalographic information and plot texts.
Results obtained through LORIEN are meant to be used in dialogue systems for ECAs so, in the next part of this article, I will describe the technological framework we develop on the basis of LORIEN structures.
This includes FANTASIA, an Unreal Engine plugin to support development, and a computational model to reinterpret linguistic knowledge in a general framework for argumentation-based dialogue we call Artificial Neural and Graphical Models for Argumentation Research (ANGMAR).
Get Your Free Copy
References
¹Hayati, S. A., Kang, D., Zhu, Q., Shi, W., & Yu, Z. (2020). INSPIRED: Toward sociable recommendation dialog systems. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 8142–8152
²Origlia, A., Di Bratto, M., Di Maro, M., & Mennella, S. (2022). A Multi-source Graph Representation of the Movie Domain for Recommendation Dialogues Analysis. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 1297–1306).
Conversational Artificial Intelligence with Neo4j and the Unreal Engine — Part 1 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





