



With spring in full swing and summer just right around the corner, I wanted to take a moment to reflect on the Neo4j Hackathon we ran last year, where we encouraged you all to compete in your Cypher skills.
Similar to the classic code-golf where the shortest solution to a problem wins, we wanted to see who can write the most efficient and shortest Cypher query to solve one of available three challenges in “Cypher Code-Golf,” where the level of difficulty ranges from Beginner, Intermediate, and Advanced Cypher skill levels.
The efficiency was measured as “Database Hits,” a metric returned from using PROFILE with your query, and the query length in characters counted for the shortest. For ties on both metrics, we used the first submission.
By the numbers, more than 1000 people registered, and over 5,000 queries were submitted. At the conclusion of the hackathon, 18 winners were selected to take home hard-earned cash prizes, and we couldn’t be more thankful to have so many participants in this challenge. More on those 18 winners below!
Our first-ever hackathon would only be complete with some learnings and challenges. We quickly realized that not having a result verification tool led to a lot of invalid queries with an unusually high number of database hits that simply didn’t make sense. Zero db-hits was an obvious one, and we got plenty of those! Next time we’ll apply the approach from Advent of Code that executes the statement with parameters for another set of input parameters and validates the correctness of the results that way.
Here’s a quick rundown of the user interface of Code-Golf:

After signing up and picking an avatar, you could start swinging.
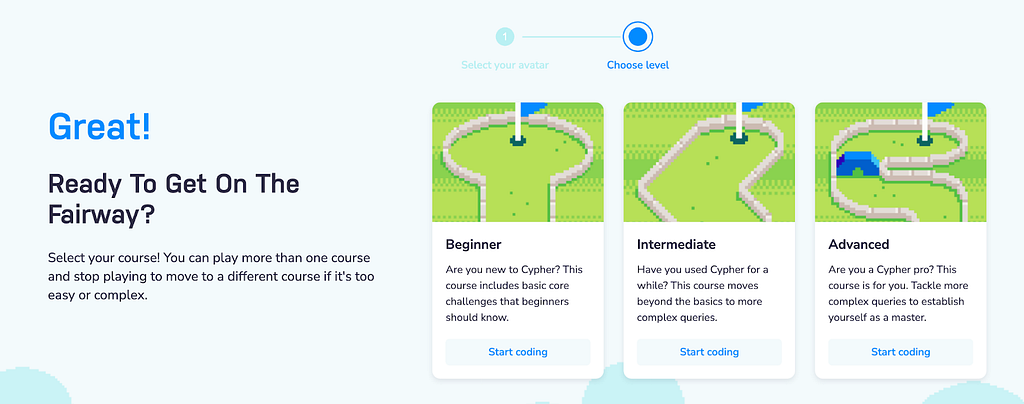
We provided three difficulty levels to accommodate different skills, one of which you could compete in.
Stack Overflow Dataset
Being developers, we felt that a Stack Overflow dataset would be easy to understand and fun to query for everyone. Based on our previous work, we used the import of the whole Stack Overflow dump from 2018 (55M nodes, 123M relationships), which provided us with this data model:
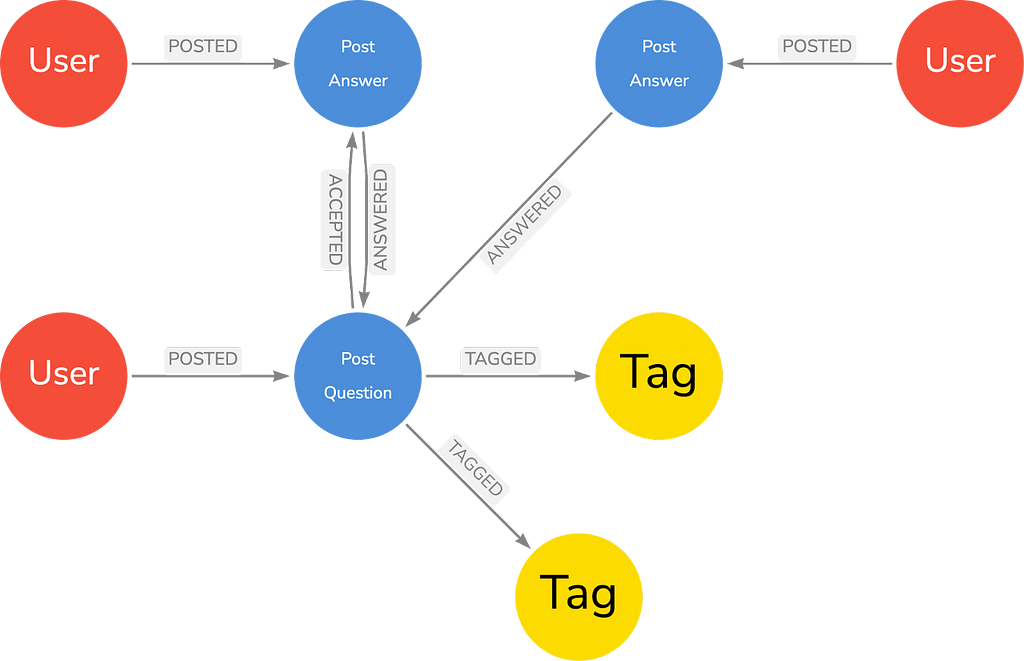
So effectively, the elements we are looking at are:
- Labels: Tag, Question:Post, Answer:Post, User
- Patterns
- (:User)-[:POSTED]->(:Post), (Tag)-[:SIMILAR]->(Tag)
- (:Question)-[:TAGGED]->(:Tag)
- (:Question)-[:ACCEPTED]->(:Answer), (:Question)<-[:ANSWERED]-(:Answer)
For the 3 levels, we had a question each.
Level 1: Beginner
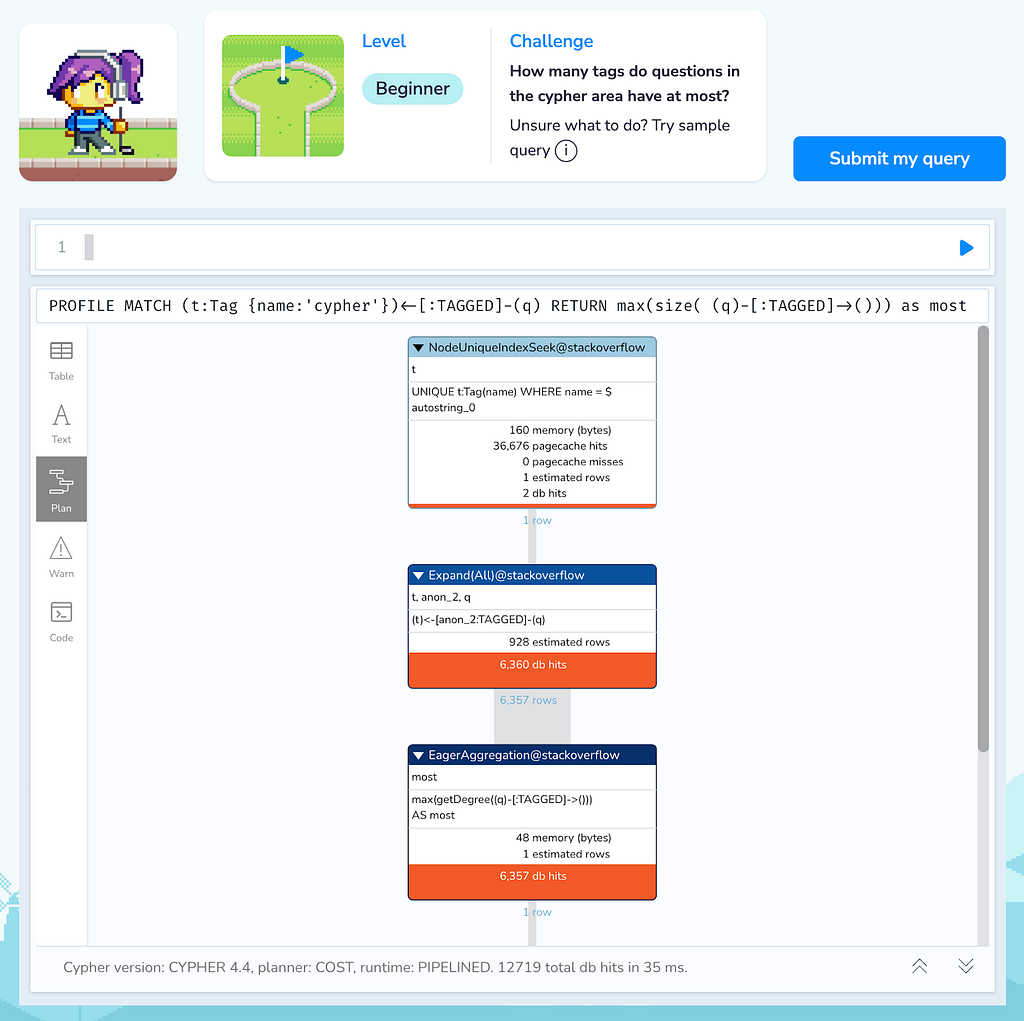
Question: How many tags do questions in the Cypher area have at most?
This question could be solved in these steps
- Find the “cypher” tag
- Find questions tagged with that tag
- Return the max degree (relationship count) of those questions
We got the most submissions in this category, 1197 in total.
There were a number of cheats e.g. just returning the number or sneakily creating a statement that just hit 1000 db-hits and then returning the fixed results or similar.
An efficient statement that meets the criteria with 12719 db-hits is:
MATCH (t:Tag {name:'cypher'})<-[:TAGGED]-(q)
RETURN max(size( (q)-[:TAGGED]->())) as mostWith Neo4j 5.x you would replace the size(pattern) with a count { pattern } expression instead.
Winners
Our 6 winners in this category are
- Chris Zirkel
- Paweł Gronowski
- Ertan Kabakcı
- Benjamin Malburg
- Joren Van de Vondel
- Paul Billing-Ross
Here’s an example query of one of our winners that’s different from the minimal query:
MATCH (:Tag {name: "cypher"})<-[:TAGGED]-(q)
RETURN max(apoc.node.degree(q,"TAGGED"))
MATCH (t:Tag)<-[:TAGGED]-(q)
WHERE t.name = "cypher"
WITH q, size((q)-[:TAGGED]->()) as ts
RETURN max(ts)Level 2: Intermediate
Question: What is the title of the most highly voted question posted on April 1st in the Perl category?
This question was also pretty straightforward, you can access the components like month or day of date(-time) property individually.
- Find the “perl” tag
- Find questions with that tag
- Filter those questions by day 1 and month 4
- Sort by score DESCending
- Return the title
Again in the 932 submissions, we got a lot of cheats that just looked for the question on that single date, or with the question-id or only within that single year and not all years, or just blatantly returned the expected title.
A reasonable solution would be:
MATCH (t:Tag {name:'perl'})<-[:TAGGED]-(q)
WHERE q.createdAt.month = 4 and q.createdAt.day = 1
RETURN q
ORDER BY q.score DESC LIMIT 1;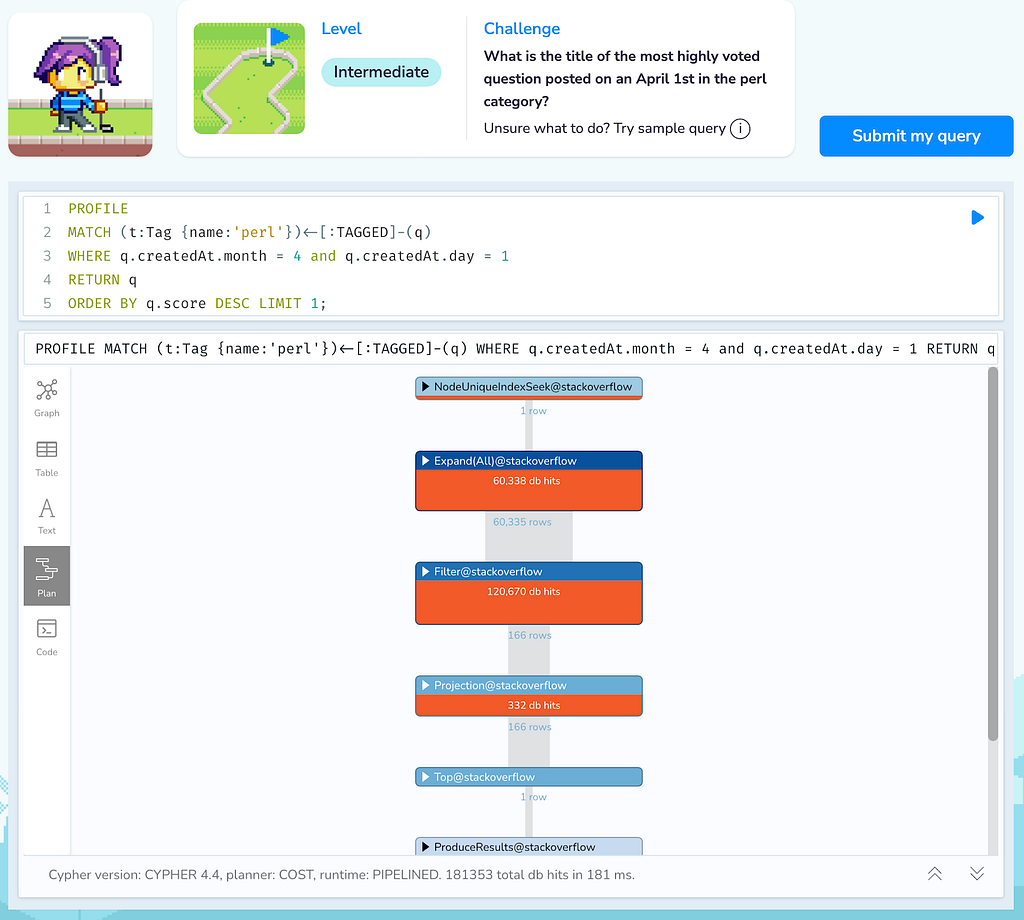
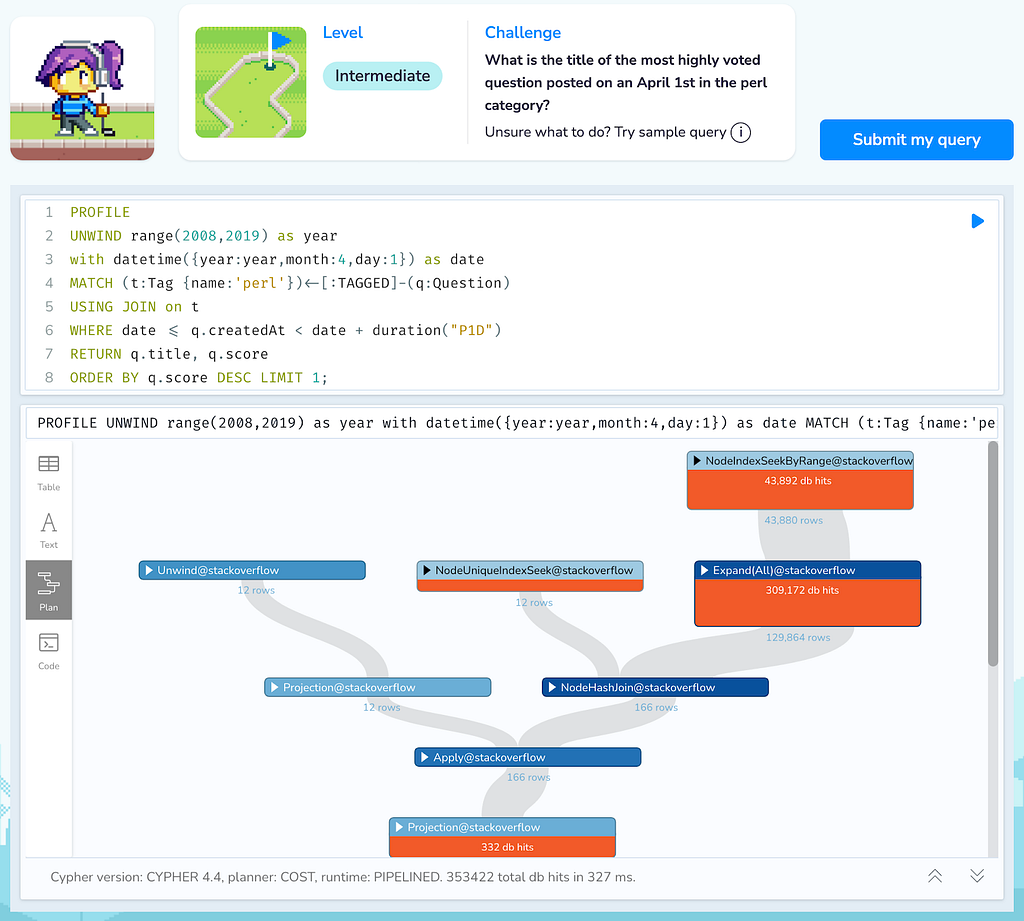
An alternative solution could be iterating over the years and then using a range (between) for using the index on the date field and a hash-join between the tag and the question.
But that one had higher db-hit costs (353k) as it had to filter all questions for that date, and not just the ones within the perl tag.
UNWIND range(2008,2019) as year
WITH datetime({year:year,month:4,day:1}) as date
MATCH (t:Tag {name:'perl'})<-[:TAGGED]-(q:Question)
USING JOIN on t
WHERE date <= q.createdAt < date + duration("P1D")
RETURN q.title, q.score
ORDER BY q.score DESC LIMIT 1;
Winners
The winners for this category are:
- Justin B
- Brian Lee
- Belinda Dhamers
- Carmi Raz
- Venkatesh Prasanna
- Camille Caulier
Some of their different solutions:
CYPHER runtime=interpreted
MATCH (t:Tag{name:'perl'})<-[:TAGGED]-(q:Question)
USING INDEX q:Question(createdAt)
USING JOIN ON t
WHERE datetime({year:2008, month:4, day:1}) <= q.createdAt < datetime({year:2008, month:4, day:2})
OR datetime({year:2009, month:4, day:1}) <= q.createdAt < datetime({year:2009, month:4, day:2})
OR datetime({year:2010, month:4, day:1}) <= q.createdAt < datetime({year:2010, month:4, day:2})
…
day:2})
OR datetime({year:2022, month:4, day:1}) <= q.createdAt < datetime({year:2022, month:4, day:2})
RETURN q.title ORDER BY q.score DESC LIMIT 1
Or with a regular expression:
MATCH (:Tag {name: 'perl'})<-[:TAGGED]-(q)
WHERE apoc.convert.toString(q.createdAt) =~ '.*04\-01T.*'
RETURN q.title
ORDER BY q.score DESC
LIMIT 1Or via date components:
MATCH (:Tag {name:"perl"})<-[:TAGGED]-(q) WHERE EXISTS {
MATCH(q) WHERE q.createdAt.month=4 AND q.createdAt.day=1
} RETURN q.id ORDER BY q.score DESC LIMIT 1Level 3: Advanced
Question: Given the top 10 tags in the Lua community (except Lua), which other tags most frequently co-occur with them. For those tags, find the 25 people who most frequently answered those questions and see what are the top 10 question tag names they had that were not in the original 10-element list.
This question was a bit more involved but you can just follow the steps one at a time to build it up.
- Find the “lua” tag
- Find questions tagged with that tag, and other tags for these questions
- Aggregate the other tags by their frequency, sort descending and select the top 10
- Turn the 10 top other tags into a list
- Find the users who posted answers to questions with those top 10 tags
- Aggregate by frequency, sort descending, and collect the top 25 users
- For those users find what the tags were for questions they answered
- Filter out the tags that were in our top 10 tags list
- Return the remaining tags, ordered by frequency descending, and pick the top 10
An example query on how it could be solved is:
MATCH (:Tag {name:'lua'})<-[:TAGGED]-()-[:TAGGED]->(o)
WITH o, count(*) as c ORDER BY c DESC LIMIT 10
CALL { with o return collect(o) as all }
MATCH (o)<-[:TAGGED]-()<-[:ANSWERED]-()<-[:POSTED]-(u)
WITH u, all, count(*) as c ORDER BY c LIMIT 25
MATCH (o)<-[:TAGGED]-()<-[:ANSWERED]-()<-[:POSTED]-(u)
WHERE not o in all
RETURN o, count(*) as c ORDER BY c DESC LIMIT 10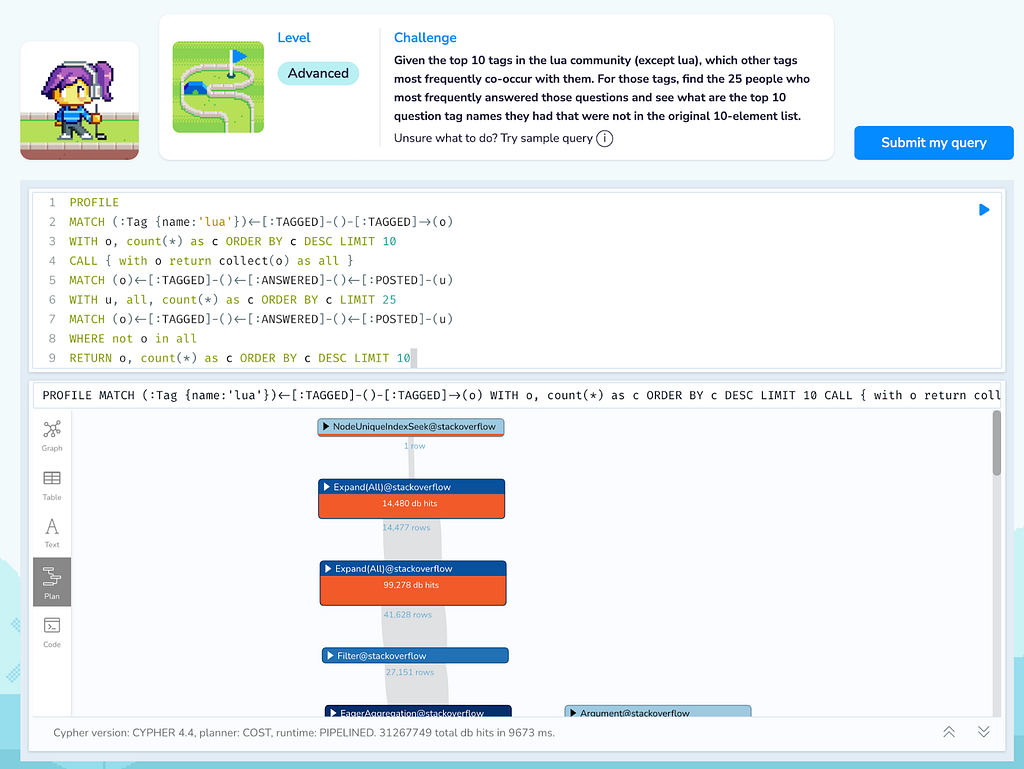
This category was as expected the hardest, many folks also had issues understanding the challenge. Unfortunately, we didn’t have the capacity to provide explanations for all your questions, apologies for that.
Winners
But we still got 111 submissions, of which we could pick the 6 winners.
- Ron van Weverwijk
- Laura Arditti
- Hüseyin Çötel
- Đức Lê Tự
- Niclas Kjäll-Ohlsson
- Rajendra Kadam
Some different solutions from the one we’ve shown:
MATCH (:Tag{name: "lua"})<-[:TAGGED]-(p)-[:TAGGED]->(o)
WITH o, count(p) as np
ORDER BY np DESC
LIMIT 10
WITH collect(o) as os
CALL {
WITH os
UNWIND os as o
MATCH (o)<-[:TAGGED]-()<-[:ANSWERED]-(a)<-[:POSTED]-(u)
RETURN u, count(DISTINCT a) AS na
ORDER BY na DESC
LIMIT 25
}
WITH os, collect(u) as us
CALL {
WITH us, os
UNWIND us as u
MATCH (u) →(:Question)-[t:TAGGED]->(ot)
WHERE (NOT ot IN os)
RETURN ot, count(t) as nt
ORDER BY nt DESC
LIMIT 100
}
return us, collect(ot)Using APOC:
MATCH l = (t:Tag {name: "lua"})-[:SIMILAR]-(s:Tag)<-[:TAGGED]-(p:Post)-[:TAGGED]->(c:Tag)
WITH c, count(l) AS n, collect(p) AS p
ORDER BY n DESC LIMIT 10
WITH apoc.coll.flatten(collect(p)) AS p, collect(c) AS o
MATCH r = (u:User)-[:POSTED]->(:Answer)-[:ANSWERED]->(q:Question)
WHERE q in p
WITH count(r) AS a, u, o, collect(q) AS q
ORDER BY a DESC LIMIT 25
WITH apoc.coll.flatten(collect(q)) AS q, o
MATCH (v:Question)-[:TAGGED]->(t:TAG)
WHERE NOT (t IN o) AND v IN q
WITH t, count(v) AS c
RETURN t ORDER by c DESC LIMIT 100Using a single query:
MATCH (tf:Tag)<-[tr:TAGGED]-(q:Question)-[:TAGGED]-(t:Tag {name:"lua"}) with tf, count(tr) as cnt order by cnt desc limit 10
MATCH (tf)<-[:TAGGED]-(q:Question)<-[:ANSWERED]-(:Post)<-[rp:POSTED]-(u:User) with u, count(rp) as cntrp, collect(tf.name) as tf_list order by cntrp desc limit 25
MATCH (tt:Tag)<-[rtt:TAGGED]-(:Question)<-[:ANSWERED]-(:Post)<-[:POSTED]-(u) where not tt.name in tf_list with tt, count(rtt) as crtt order by count(rtt) desc limit 100 return ttA smaller Stack Overflow dataset is also available on Neo4j AuraDB, the full dataset is on the Demo server demo.neo4jlabs.com with username/password/database “stackoverflow”.
Please make sure you join our user forums or hang out in our Discord to learn from each other.
If you want to learn more, we have published additional Cypher, Graph Data Science, and Application Development courses on GraphAcademy.
And we’re running regular live streams, Meetups, GraphSummits, and other events, all of which you can find on our Events Page.
Cypher Code-Golf Hackathon Completion was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





