
Cypher Gems in Neo4j 5

Director of Engineering, Neo4j
18 min read

Now that Neo4j 5 LTS has been released, let’s look at what it offers in terms of Cypher features that may look minor, but that can have a huge impact. There has been a lot written about the high-profile features — like parallel runtime, block format, quantified path patterns, vector indexes (I won’t even link to a blog for that one because there are too many to choose from, but you will find some farther down in the article), Change Data Capture, and the performance improvements — but what about all the less-marketed improvements? In certain contexts, they can have a bigger impact than the things you hear the most about.
Cypher Unicode Normalization
Let’s assume you have a database of something — customers, for example — that has been built over some time. The data has been injected from various tools, and some may have been imported from other systems.
Let’s create a small part of this graph with the code below. To try this, copy and paste this code into Neo4j Query or Browser because you cannot type it yourself:
CREATE (a1:Address {street: "Fake street 3B", city: "Malmö"})
CREATE (a2:Address {street: "Imaginary Alley 116", city: "London"})
CREATE (a3:Address {street: "Fake street 6A", city: "Malmö"})
CREATE (c1:Customer {name: "Jason Bourne"})
CREATE (c2:Customer {name: "Sarah Connor"})
CREATE (c3:Customer {name: "James Bond"})
CREATE (c4:Customer {name: "Ned Stark"})
CREATE (c1)-[:LIVES_AT]->(a1)
CREATE (c2)-[:LIVES_AT]->(a3)
CREATE (c3)-[:LIVES_AT]->(a2)
CREATE (c4)-[:LIVES_AT]->(a1)
Note that the above statements use CREATE, which is traditionally used in Cypher, but the new GQL-compliant INSERT is also supported.
Now list all customers and what city they live in:
MATCH (c:Customer)-[:LIVES_AT]->(a:Address)
RETURN c.name AS Customer, a.city as City
The result would be:
Customer City
"Jason Bourne" "Malmö"
"Sarah Connor" "Malmö"
"James Bond" "London"
"Ned Stark" "Malmö"
So we have three customers in Malmö and one in London. But hopefully for our business, we have more than four customers; plus, we assumed we had a big database built over a long time. So reading through all the lines to see who lives in Malmö might not be feasible, and after all, filtering is something most query languages do very well. So let’s only ask for those who live in Malmö:
MATCH (c:Customer)-[:LIVES_AT]->(a:Address)
WHERE a.city = "Malmö"
RETURN c.name AS Customer, a.city as City
The result:
Customer City
"Jason Bourne" "Malmö"
"Ned Stark" "Malmö"
Wait — what happened to Sarah? She also lives in Malmö! The reason, as you may have guessed, is Unicode. The same character can be represented in different ways in Unicode. The first Malmö address (a1) uses the standard representation for ‘ö’, which is hex F6 (“u00F6”), while the second uses a standard ‘o’ (“u006F”) followed by a modifier to add the dots (“u0308”).
Unicode is unpredictable that way. There are other characters with even more representation, like ‘Å’ for example, that have three (“u00C5”, “u212B,” and “u0041u030A”). To solve this, Cypher has introduced a normalize() function, which you can use like this:
MATCH (c:Customer)-[:LIVES_AT]->(a:Address)
WHERE normalize(a.city) = normalize("Malmö")
RETURN c.name AS Customer, normalize(a.city) as City
And this time, we get the expected result:
Customer City
"Jason Bourne" "Malmö"
"Sarah Connor" "Malmö"
"Ned Stark" "Malmö"
This may seem like a small thing, but it can be a big pain point if you have a large database of non-normalized strings. You can read more about Unicode normalization in the Cypher manual.

Property-Based Access Control
Role-based access control (RBAC) has been a part of Neo4j for several versions, but now you can also control access based on the properties of the nodes. This warrants another example.
We have our HR records as a graph with one node label called Employee. The Employee has four properties: name, salary, role, and department. Anyone should be able to read name, role, and department, but only the department head should be able to read the salary. And with a setup like this, it is important that the department head doesn’t have write access to the department property, or it would be easy to get around it.
We add a couple of employees to our company:
CREATE (:Employee {name: "Dilbert", department: "Engineering", role: "Software Engineer", salary: 100000})
CREATE (:Employee {name: "Alice", department: "Engineering", role: "Software Engineer", salary: 100000})
CREATE (:Employee {name: "Wally", department: "Engineering", role: "Software Engineer", salary: 80000})
CREATE (:Employee {name: "Asok", department: "Engineering", role: "Intern", salary: 50000})
CREATE (:Employee {name: "Pointy-Haired Boss", department: "Engineering", role: "Engineering Manager", salary: 150000})
CREATE (:Employee {name: "Catbert", department: "HR", role: "HR Manager", salary: 150000})
CREATE (:Employee {name: "Tina", department: "Documentation", role: "Technical writer", salary: 100000})
CREATE (:Employee {name: "Dogbert", department: "Executive", role: "World Dominator", salary: 10000000})
Then we create an EngineeringManager role that only has read access to employees and who can only see the salary if the department is “Engineering.”
CREATE ROLE EngineeringManager IF NOT EXISTS;
GRANT ACCESS ON DATABASE * TO EngineeringManager;
GRANT MATCH {*} ON GRAPH * TO EngineeringManager;
DENY READ {salary} ON GRAPH * FOR (n:Employee) WHERE n.department <> "Engineering" TO EngineeringManager;
CREATE USER pointyhairedboss IF NOT EXISTS SET PASSWORD 'password' CHANGE NOT REQUIRED;
GRANT ROLE EngineeringManager TO pointyhairedboss;
(Yes, Pointy-Haired Boss would probably use ´password´ as password.)
If we log out and log back in as pointyhairedboss and then try to list our employees to look at salaries, we get:
MATCH (e:Employee)
RETURN e.name AS Employee, e.department AS Department, e.salary AS Salary
Employee Department Salary
"Alice" "Engineering" 100000
"Wally" "Engineering" 80000
"Asok" "Engineering" 50000
"Pointy-Haired Boss" "Engineering" 150000
"Catbert" "HR" null
"Tina" "Documentation" null
"Dogbert" "Executive" null
"Dilbert" "Engineering" 100000
It seems to work since we don’t see salaries for those not in Engineering. And if we try to look at the node in the Browser, we can’t see the salary property.
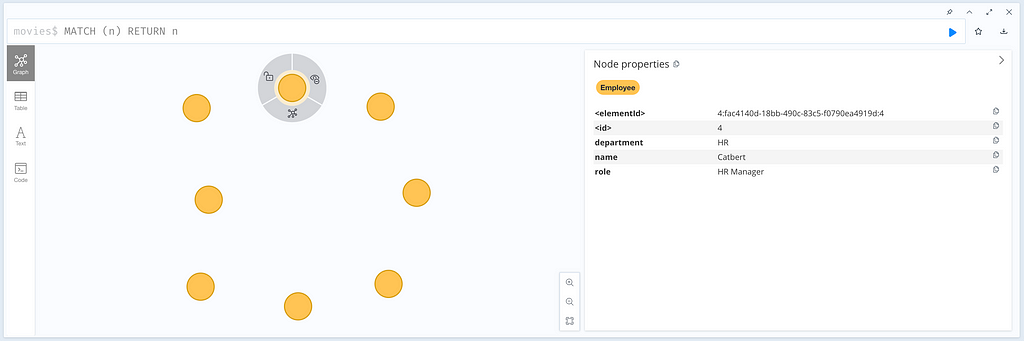
For security reasons, it might be worth testing to see if we can change Catbert’s department to see if we can get around the rule:
MATCH (e:Employee {name: "Catbert"}) SET e.department = "Engineering"
But, as it should, we are prevented by the property-based access control:
Neo.ClientError.Security.Forbidden
Set property for property 'department' on database 'hr' is not allowed for user 'pointyhairedboss' with roles [EngineeringManager, PUBLIC].
You can read more about property-based access control in the Cypher manual.
Dynamic Labels
We all know that not all queries are static. An application wouldn’t be very exciting if it did exactly the same thing every time. If we search for a person by name, and the name to search for is an input from the user, one way to do it could be:
executeQuery("MATCH (p:Person) WHERE p.name = "" + name + "" RETURN p");
Though, as we all have learned from xkcd, this is a bad idea as it opens us up to Cypher injection. Someone could input:
Robert" RETURN p; MATCH (n) DETACH DELETE n //
as their name, which would give the query a whole other outcome.
The solution is to use parameters instead of string concatenation on the client side:
MATCH (p:Person) WHERE p.name = $name RETURN p
However, up until Neo4j 5, you have not been able to use parameters for the label names. You couldn’t do this:
MATCH (p:$($label)) WHERE p.name = $name RETURN p
But now, since 5.26, you can. It’s critical to be able to have dynamic labels in an injection-safe way without having to do client-side variable sanitation and string concatenation. But it is also convenient in other cases — if, for example, we want to import data from a CSV file with the LOAD CSV command and we have the label name as one of the fields:
LOAD CSV WITH HEADERS FROM 'file:///names.csv' AS line
CALL {
WITH line
CREATE (p:$(line.profession) {id: line.id, name: line.name})
} IN TRANSACTIONS
This could be accomplished also in prior versions with a CASE statement, but that requires quite a bit more code. And also, it would have to be updated when a new profession is added, while the above wouldn’t.
Someone could claim that the CASE variant would provide more protection from incorrectly formatted data in the CSV. Well, just sit tight a while longer and soon, you will have an optional graph schema that will solve that, too. 🙂
Note that you could do dynamic labels prior to Neo4j 5 by using Awesome Procedures on Cypher (APOC), though having it natively supported in the language has many benefits. Not only is it more readable and easier to work with but the query planner has awareness and can optimize in ways that it doesn’t have with custom procedures.
Type Predicate Expressions
One subtle yet powerful addition in Neo4j 5 is the ability to check the type of properties. You can check if a property is of a certain type and get a string representation of the type.
To demonstrate this, we’ll envision having a graph without schema, at least without a known schema, that we want to use for GraphRAG (see below). Maybe the graph was created by an AI service from unstructured data, or maybe we simply haven’t received a description of all the node types and what properties they may have.
If you don’t know what GraphRAG is, it is about using an LLM chatbot (e.g., ChatGPT) to ask questions about your own dataset. You provide parts of your knowledge graph to the chatbot and ask for answers from those parts. To know what parts are relevant to your question, you use vector search.
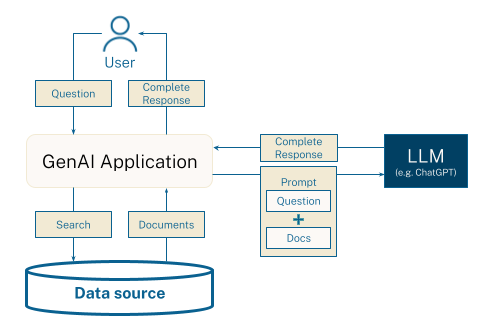
To be able to do this, we have to start by doing a vector embedding of the relevant text property in each node. But how do we know which is the relevant text property if we don’t know the schema? The proper answer is probably to spend some time with your graph, learn it, and figure out what the content is. But here is a shortcut if you don’t want to: We’ll simply assume that the longest string property in each node is the one we want to embed.
To achieve this, we need to know what properties are string properties, and that is where the new type predicates come in. Here is how we could do it:
MATCH (n)
CALL(n) {
UNWIND keys(n) AS p
WITH n, p WHERE n[p] IS :: STRING NOT NULL ORDER BY size(p) DESC LIMIT 1
RETURN p
}
WITH collect(n[p]) AS properties, collect(n) AS nodes
CALL genai.vector.encodeBatch(properties, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(nodes[index], "embedding", vector)
Note 1: Before doing the above, we need an account with OpenAI to give us the API key that we set a parameter apiKey, and we also need to create a vector index on the embedding property on all our label types.
Note 2: This assumes we have less than 2,048 nodes in our graph. With more, we need to split it up into chunks what OpenAI batch text embeddings can handle.
Note 3: We still need to have some concept of the schema of our graph in order to use GraphRAG. Otherwise, it will just be standard RAG.
You can read more about type predicates in the Cypher manual.
OPTIONAL CALL
You’ve been writing Cypher queries for a while and are starting to feel proficient with it. And one day — probably a sunny spring day with birds singing and the scent of grass in the air — you have the revelation of OPTIONAL MATCH and what it can do. This was the day you earned the Cypher expert cape.
Neo4j 5 introduces OPTIONAL CALL, which does for CALL what OPTIONAL MATCH does for MATCH.
Let’s start by just quickly looking at what OPTIONAL MATCH does. We have a graph of Person nodes. Some of these, but not all, own a dog. Some even own more than one dog.
CREATE (q:Person {name: "Queen Elizabeth II"})
CREATE (c:Person {name: "Chris Evans"})
CREATE (k:Person {name: "Kim Kardashian"})
CREATE (m:Dog {name: "Muick"})
CREATE (s:Dog {name: "Sandy"})
CREATE (d:Dog {name: "Dodger"})
CREATE (q)-[:OWNS]->(m)
CREATE (q)-[:OWNS]->(s)
CREATE (c)-[:OWNS]->(d)
Now we want to list all persons, and of those who own dogs, we want one row per dog. If we just do:
MATCH (p:Person)-[:OWNS]->(d:Dog)
RETURN p.name AS Person, d.name AS Dog
then we will not see Kim Kardashian at all, because she doesn’t own a dog. The same would happen even if we split it into two MATCH queries:
MATCH (p:Person)
MATCH (p)-[:OWNS]->(d:Dog)
RETURN p.name AS Person, d.name AS Dog
The solution is to use OPTIONAL MATCH, which will always return at least one row (as null), even if there are no matches:
MATCH (p:Person)
OPTIONAL MATCH (p)-[:OWNS]->(d:Dog)
RETURN p.name AS Person, d.name AS Dog
Here we will also get Kim Kardashian as a result, with the Dog column as null. This is not new to Neo4j 5, but using the same mechanism for CALL is.
I live in Malmö, and I want to visit all capitals in Europe, but I am also lazy and want to start with those that are the easiest to get to (i.e., shortest driving distance). I will use Dijsktra’s cheapest path to get the driving distance to each of the cities. But I don’t want to miss out on a city like Reykjavík just because I can’t drive there; when I get to them on the list, I will fly instead. Here is how I could get this list in the order I will visit the cities:
MATCH (m:City {name: "Malmö"})
MATCH (c:City {capital: true, continent: "Europe"})
OPTIONAL CALL apoc.algo.dijkstra(m, c, "ROAD", "distance") YIELD path, weight
RETURN c.name AS City, weight AS Distance ORDER BY weight
Without OPTIONAL CALL, Reykjavík and all other capitals without a land connection to Malmö would be excluded from the result.

OPTIONAL CALL also works for subqueries:
MATCH (p:Person)
OPTIONAL CALL(p) {
MATCH (p)-[:OWNS]->(d:Dog)
RETURN d
}
RETURN p.name AS Person, d.name AS Dog
This does the same as the OPTIONAL MATCH example further up, which is a better way to do it in this case, but just to show how it works.
You can read more about OPTIONAL CALL in the Cypher manual.
For readers familiar with SQL, OPTIONAL CALL gives Cypher a universally composable left-outer join capability.
POINT Indexes
Neo4j 5 saw the introduction of a new index type, VECTOR indexes (used for GenAI operations such as vector embeddings/vector search and GraphRAG, as we saw earlier in this article). Some other indexes — RANGE indexes and POINT indexes — did exist in previous versions, but they weren’t used in query planning until Neo4j 5, and now you can enjoy the full performance boost from them.
One usage of POINT indexes could be when we want to visualize the graph, and have too much data to render it all in a good way, but we have a geographical location (either a 2-D location on a map or a 3-D location in space) for the nodes, and not all nodes are visible at the same time. This could be if we move over a map and want to see the subset of things that are in view right now but want to avoid fetching the billions of nodes we may have in the graph that are outside the current viewport.
Here is a description of a similar scenario where we fly through a 3-D space and want to render the nodes within the vicinity at the moment. This uses the same IMDb dataset I used in the GraphRAG article, containing all movies and persons from IMDb — a total of 24 million nodes. Too much to visualize in a good way.
Instead, I did a static layout of my graph, giving every node a fixed location in space. Then I did a JavaFX 3-D application that allowed me to fly through this 3-D space and experience the movies and persons while continuously updating the 3-D model in the background with only those objects within the vicinity. Thanks to the POINT index, this can be done quickly despite having a huge dataset.
At first, I gave all nodes that I wanted to be part of the rendering a label called Node3D. In my case, this was all nodes except the Genre nodes (they provide another complexity rendering-wise because they have on average almost half a million relationships each).
MATCH (n:!Genre)
CALL(n) {
SET n:Node3D
} IN TRANSACTIONS
Now I gave all those nodes a 3-D position in a property called graph3d. The type of this property was a Point in a 3-D Cartesian space (SRID 9157) with arbitrary units. I started by just giving them a random position, evenly spread in a spherical space:
MATCH (n:Node3D)
CALL(n) {
WITH n,
rand() AS u,
rand() AS v,
rand() AS w
WITH n,
$radius * (u ^ (1.0/3.0)) AS radius,
acos(2*v - 1) AS theta,
2 * pi() * w AS phi
WITH n, radius, theta, phi,
radius * sin(theta) * cos(phi) AS x,
radius * sin(theta) * sin(phi) AS y,
radius * cos(theta) AS z
SET n.graph3d = point({x: x, y: y, z: z})
} IN TRANSACTIONS
A more elaborate layout, like a force-based layout, is difficult on a big dataset. But to give it more life, I wanted closely related items to be closer together. This query groups leaf nodes as dandelion shapes around their parents:
CALL() {
MATCH (n:Node3D)
WHERE COUNT{(n)-[]-(c:Node3D) WHERE labels(n) = labels(c)} = 1
MATCH (n)-[]-(p:Node3D)
WHERE labels(n) = labels(p)
RETURN n,p
UNION
MATCH (n:Node3D)
WHERE COUNT{(n)-[]-(:Node3D)} = 1
MATCH (n)-[]-(p:Node3D)
RETURN n,p
}
CALL(*) {
WITH n, p,
rand()*2.0*pi() AS a1,
rand()*2.0*pi() AS a2
WITH n, p, a1, a2,
sin(a1)*$circle AS y1,
cos(a1)*$circle AS r
WITH n, p, a2, r, y1,
cos(a2)*r AS x1,
sin(a2)*r AS z1
SET n.graph3d = point({
x: p.graph3d.x + x1,
y: p.graph3d.y + y1,
z: p.graph3d.z + z1})
} IN TRANSACTIONS

And now we come to the index itself: the mechanism that makes this rendering feasible:
CREATE POINT INDEX graph3d_index FOR (n:Node3D) ON (n.graph3d)
In the first query, where the random layout was done, we used a radius of 125000 (still just an arbitrary unit) for our entire space. To begin, we place ourselves (the camera) at the center of this sphere. But instead of fetching all nodes, we just fetch those within a range of 15000 from where we are:
MATCH (n:Node3D)
WHERE point.distance(n.graph3d, $center) < 15000
RETURN n
This makes us “see” 12 percent of the radius of the entire space, but the volume of the sphere we see is just 0.17 percent of the volume of the entire sphere, which, on average, would only require us to fetch about 41,500 nodes. And because of the POINT index, the above query executes in a few milliseconds.
The above query took half a second in Neo4j 5 (on my local MacBook). In Neo4j 4, it took 8 seconds, despite having the POINT index created. This is not a scientific benchmark, but just giving some idea.
When we fetch the nodes, we memorize where we were when we did so. As soon as we have moved 1,000 units from that point, we called the above query again in a background thread to update what nodes we have in our local model (discarding those that moved out of that local space).
The visibility in JavaFX is set to 13,000 — twice the move distance lower than the fetch radius, thus making objects smoothly appear in our eyesight as we move and making the background fetching invisible.
We had one more thing to solve: rendering the relationships. This was a lot more difficult than the nodes. A node is either within our visibility sphere or not. But a relationship can pass through our visibility sphere even if both its end nodes are very distant.
To solve this, we had to make a simplification: We only render relationships for nodes that either start or end in the visibility sphere. Still there are a lot more relationships than nodes in this local area, so we reduce the visibility sphere for fetching relationships to a fifth of that for nodes.
To handle relationships, we rewrite the query above as:
MATCH (n:Node3D)
WHERE point.distance(n.graph3d, $center) < 15000
OPTIONAL MATCH (n)-[r]-(:Node3D)
WHERE point.distance(n.graph3d, $center) < (15000/5)
RETURN n, r, startNode(r).graph3d AS startPos, endNode(r).graph3d AS endPos
Now we just need our JavaFX 3-D application, which lets us fly through our sphere-shaped space while our local model is updated in the background without us even noticing it. This is all thanks to the POINT index that lets us quickly fetch nodes based on distance.

You can read more about indexes in the Cypher manual.
Improved Syntax
The things described above show new language constructs that enable things that were difficult to accomplish prior to Neo4j 5. But there have also been a lot of language improvements that just make the language cleaner, without necessarily enabling new functionality. Some of this has been done as part of adapting to the new GQL standard.
Scoped CALL
Before Neo4j 5, you had to begin a CALL subquery with a WITH statement, specifying what parameters were sent to the subquery. However, this WITH didn’t behave as other WITHs — for example, you couldn’t add a WHERE. To do that, you had to use another WITH directly after:
MATCH (n)
CALL {
WITH n
WITH n WHERE n.age >= 21
...
}
Now, you can instead supply the parameters in the CALL statement itself:
MATCH (n)
CALL(n) {
WITH n WHERE n.age >= 21
...
}
You can also use CALL(*) to use all parameters in scope (like you had with WITH * before) and CALL() in case you have no parameters:
MATCH (c:Child)-[o:OWNS]->(d:Dog)
CALL(*) {
MERGE (c)-[:HAS_PARENT]->(p:Parent)
MERGE (p)-[:HAS_TO_WALK]->(d)
}
More Compact CASE Statements
In Neo4j 5, we allow for more compact CASE statements when a user wants to have the same output for the multiple branches in the CASE expression. It also allows for more diverse simple CASE statements, like this:
MATCH (x)
RETURN
CASE x.age
WHEN 5, 7, 9 THEN true
WHEN > 20 THEN true
WHEN < 0 THEN true
ELSE false
END
Graph Pattern Matching Improvements
Graph Pattern Matching (GPM) is the core of Cypher and GQL. It is the ASCII art syntax, like ()-[]->(), used to match patterns in the graph. This has existed since the birth of Cypher, but has evolved quite a bit lately. The biggest addition in Neo4j 5 was quantified path Patterns (QPP), which was mentioned at the top of this blog. But there have also been some smaller tweaks to make the pattern matching more convenient to use.
Already in Neo4j 4, we added the possibility of inline filtering in node patterns:
MATCH (p:Person WHERE p.born > 1950) RETURN p
And now in Neo4j 5, it is possible to do the same thing for relationships:
MATCH (p)-[k:KNOWS WHERE k.since > 2019]->(p2) Return p2
Another very usable GPM feature in Neo4j 5 is label pattern expressions, which allow you to do things like this:
MATCH (superhero:Marvel|(DCComics & !Batman)) RETURN superhero
Just as in all C-based languages, | means OR, & means AND, and ! means NOT. So the above will match for nodes with labels Marvel or DC Comics (except if they also have the label Batman).

All these improvements can be enjoyed on their own, but are also the base on top of which we built the new quantified path pattern feature.
Summary
Little drops of water make the mighty ocean. I hope that some of these lesser-known and less-marketed features piqued your interest. If you’re on Aura, you already have access to all these features* (unless you are on a legacy 4 LTS version). If you are not on Aura, Neo4j 5 LTS is available for you to explore at the usual download places. Have fun!
* Note that property-based access control is only available in the higher Aura tiers and in Enterprise edition if you are running your own server.
Cypher Gems in Neo4j 5 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs


