Eagerness in Neo4j Query Planning Explained With a Little Fairytale

Director of Engineering, Neo4j
15 min read

The constant midwinter darkness lay heavy over the North Pole. Not even the green aurora that shimmered in the sky managed to chase away the shadows. The only sound but the wind came from the valley behind the snow-covered ridge. A muffled sound of hammer strokes fought against the sound of the wind to make it over the ridge. It came from Santa’s toy factory at the bottom of the gorge.
For 24 days, the elves had been working hard to make the 2 billion Christmas presents for every kid under the age of 15, and Santa was getting anxious, as he was every year, over the thought of delivering it all in a single night. It was so much easier 100 years ago, and it would only get worse. His hand trembled as he brought the cup of hot chocolate to his mouth as he sat in front of the fireplace. “This stress will put me in an early grave,” he thought to himself, while realizing that at 1,744 years old, it probably wouldn’t be considered early for most. “Maybe it is just my time,” he thought. The shaking made him spill hot chocolate on his red pants, and a short cry escaped him.
“What’s happening?” said an elf who entered the room having heard him from the hallway outside.
“I can’t do this,” cried Santa. I can’t visit 2 billion homes in a single night.
The elf walked into the room and sat down next to Santa in front of the fireplace.

“Then why don’t you just change things? I think most agree that Christmas isn’t a single day. Christmas lasts from Advent Sunday until Epiphany, which would give you over a month to deliver it all.”
“That sounds wonderful, but then you elves would only have a day to produce it all.”
“But we can do that in November,” answered the elf, eager to help.
Santa patted him on the head while wiping a tear from his own cheek.
“That’s kind of you, but I can’t force all kids to come in with their wish lists that early.”
The elf glanced back into the fire, with his thick brows squeezed together in deep thought. Then he looked up at Santa again and said, “I know you like to have all those presents loaded up in your sleigh and ride off toward the full moon with the sack on the rim of bursting from all those packets. But if you let go of that eagerness we can solve it more efficiently.”
“How so?” Santa asked.
“As soon as we start receiving wish lists from the kids,” the elf said, “we can start to produce them, we don’t have to be eager and pile up all lists before starting production. And as soon as we have some produced, you can start deliveries. When you are back from the first round, we will have the second batch ready, and so on.”
“That’s fantastic!” Santa shouted. And strengthened by that vision — and the remaining hot chocolate — he ran out and made his last trip with the stressful schedule of 0.04 milliseconds per house visited.

The next year, they implemented the elf’s plan. As soon as the wish lists started pouring in in mid-November, they started producing toys, wrapping them, and loading them on the sleigh. And on the last day of November, which was the Advent Sunday that year, Santa made his first trip with the first batch of presents. And that night he spent a full millisecond at each home, and he rejoiced.
A week later, one of the elves, Herbert, was sitting on the beige tile floor, a mountain of opened envelopes and a candle beside him (because the envelopes shadowed the light from the fireplace), reading the newly arrived wish lists. He had just opened one from little Timmy, which read:
“For Christmas, I don’t want anything at all for myself. My friend Bobby’s parents just split up, which made him very sad, and I know that he wished for a stuffed elephant. So I’ll use my wish to make his elephant twice as big and twice as cuddly.”

Herbert felt an eerie chill down his back and ran over to the ledger and quickly browsed through it. And to his fear, he found Bobby and that his gift had already been delivered by Santa. He jumped up and ran through the deep snow over to the factory and quickly pulled the Andon cable (see the Toyota production system guide) to stop production.
Santa and the production leaders assembled to come up with a solution — a short-term solution for the problem at hand and a long-term solution. The short-term solution was to replace Bobby’s elephant with a bigger one (they even made it red, having overheard Bobby’s complaints over the previous yellow mistake).

The next year, they implemented the long-term solution. They realized that the delivery of the presents could be done continuously as soon as produced, but they had to be eager in the collection of wish lists and gather them all before starting production. And so, in the postal collection room, they had a big bin called the Eagerness bin, where they eagerly collected all the wish lists before starting production.
That year, everything went smoothly. Santa couldn’t start his rounds until the second Sunday of Advent, but he still managed to get almost a millisecond per home, and there were no hiccups at all. And all the children of the world were joyous.

Eagerness in Cypher
Now what on earth does that have to do with a query language? Well, most query languages — whether Cypher, GQL, or SQL — work like that. They execute using operators (collecting wish lists, producing toys, delivering Christmas gifts, etc.), and each operator produces a number of rows, which is the input for the next operator. Let’s take this query as an example:
MATCH (n)
WHERE n.startYear = 1999
RETURN n
When a query like that comes to the database server, it is first parsed and semantically analyzed. Next, it arrives in the query planner, which will figure out the most effective way to execute it (i.e., what operators to use and in what order). For a simple query like this, there isn’t much choice; it will be done with three operators. We can see this by running an EXPLAIN on the query, which shows us the query plan:
EXPLAIN
MATCH (n)
WHERE n.startYear = 1999
RETURN n
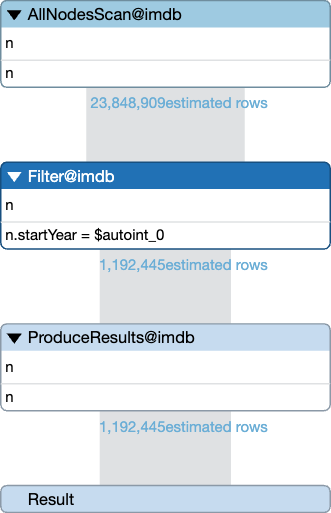
As we said, the result of each operator is rows that serve as input to the next operator.
The first operator is an AllNodesScan, which finds all nodes in the database and returns one row for each. The second operator is Filter, which filters out those where the start year isn’t 1999. And the third one is ProduceResults, which returns the result back to us as a caller. We can also see the estimated number of rows from each operator in the plan (based on what the planner knows about the statistics of the database).
We see here that the first operator, the AllNodesScan, produces 24 million rows. Piling all of them up before starting to filter would be a big risk of running out of memory (and it wouldn’t be performant). So it does like with Santa Claus: The filter starts receiving nodes from the scan as soon as they become available, and it passes them on to the result producer as soon as it has found matches, and the result producer starts to stream them back to us as soon as it gets them. That way, there never have to be very many nodes in memory.
However, with a very small change to the query, we start getting problems, just like the elf had with Timmy’s wish:
MATCH (n)
WHERE n.startYear = 1999
RETURN n ORDER BY n.primaryTitle
This time, there will be a new operator between the Filter and the ProduceResult operators. The new operator is Sort, which, as it sounds, sorts all rows on something (the title in this case). It would be hard for this operator to sort all rows without having all the rows at hand, so it needs to collect all rows before starting to produce a result*. We say that Sort is an eager operator. This seemingly small change to the query can have a big impact on memory requirements and performance.
This list of Neo4j operators shows all operators the query planner can choose from when planning how to execute a query (this is an evolving list that grows with new releases). In the rightmost column (Considerations), we see a blue tag called “Eager” on those operators that are like Sort (i.e., that need to collect all rows before starting to produce a result).
Looking through that list, you’ll find one such eager operator simply called Eager. The rest of this article will be about this mysterious little operator that does nothing but collect all rows from the previous operator before submitting them to the next.
The Eager Operator
Thinking about it, it makes sense that Sort is eager by this definition. Of course, we need all the rows before we can determine the order and before we can return the one that should be considered the first one. This is very deterministic, but not all cases are.
Let’s look at a simple query operating on the UK Railway graph:
MATCH (station:LondonGroup)<-[:CALLS_AT]-(london_calling)
MERGE (london_calling)-[:CALLS_AT_CITY]->(city:City {name: 'London'})
What we do here is find all calling points that seem to be in London (because they point to a station that is part of LondonGroup), and we add a reference for all of them to a newly created City node called London**.
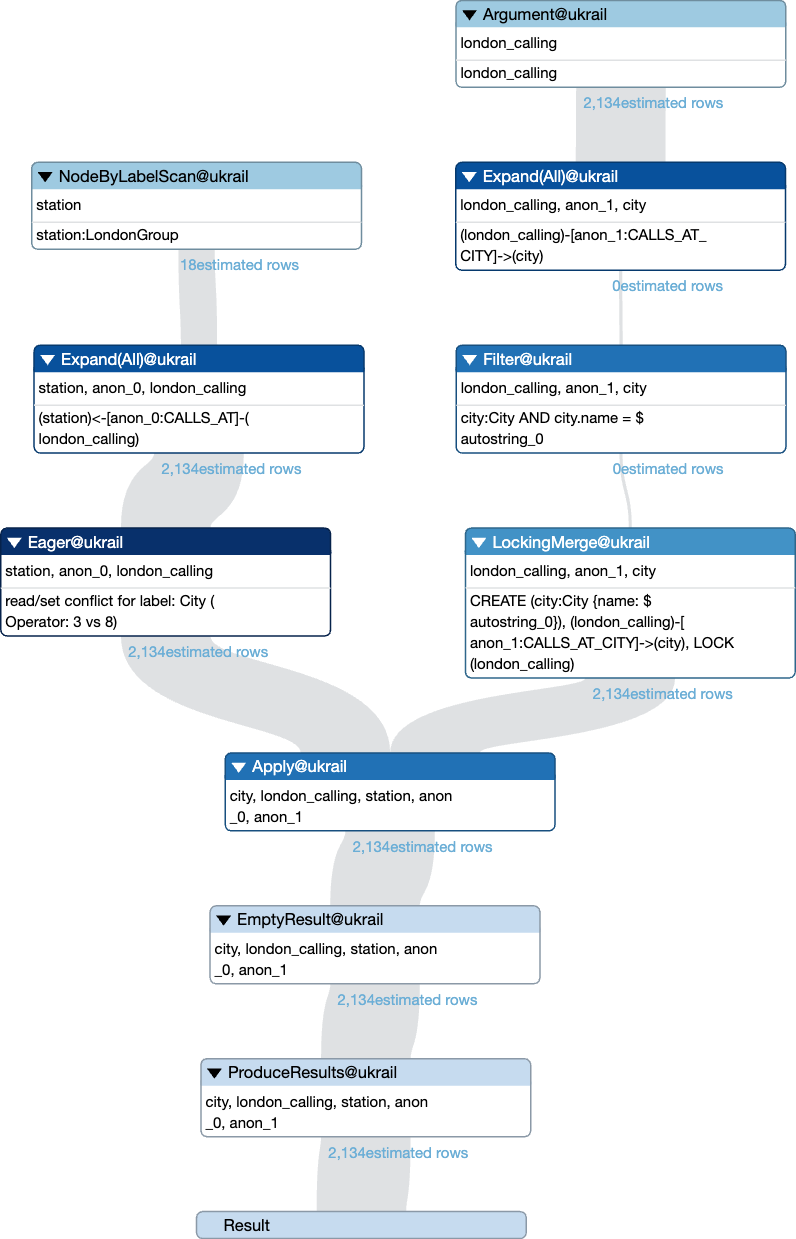
This yields a plan with a bunch of operators: NodeByLabelScan, Expand(All), Filter, LockingMerge, and Apply. None of these are eager operators, so the query should be able to execute without piling up rows anywhere, right? No, it can’t.
The MERGE operation can create new nodes with the label City. Could those nodes impact the MATCH if it’s still searching? That’s unclear since the MATCH pattern includes a node assigned to london_calling without a label specified. Theoretically, london_calling could pick up the newly created node, which it’s not allowed to do. To solve that, it inserts the Eager operator at a strategic point to collect all rows before proceeding, as we can see in this plan:
OK, you may think this would be the case for any creation after a match where the match could catch what was created. For example:
MATCH (p:Person)
CREATE (twin:Person {dna: p.dna})
Here, the match would match on things created by the subsequent match if there wasn’t an Eager operator, right? In principle, yes, but fortunately there’s something called stable cursors for direct matches. Because of how the NodeByLabelScan is implemented in the database, there’s no risk of being infected by newly created nodes. But in the case of the UK Railway example, there isn’t a stable cursor, so the Eager is needed.
Optimizing Eagerness
So why do we need to know this? This query planning seems like a black box thing that we shouldn’t have to care about, right? Yes and no.
Cypher is, like other database query languages, a declarative language. This means that, unlike a regular programming language like Java, you don’t define what the computer should do or how it should do it, but you define what result you want, and it’s up to the computer to figure out the best and most efficient way to give you that. This is the purpose of the query planner. When you first start working with a query language, you normally do view it as a black box, and you’re happy if you get what you thought you asked for. But after a while, you’ll want to tweak your queries and make them more efficient. That’s when it becomes useful to read execution plans.
As we saw above, eagerness is memory-consuming and degrades performance, so it’s something we want to avoid if possible. If we want to optimize our queries, the Eager operator is probably one of the first things to look for and see if we can remove.
Let’s revisit the query on the UK Railway graph that caused the Eager operator, and let’s run it with the EXPLAIN or PROFILE*** statement to view the execution plan:
EXPLAIN
MATCH (station:LondonGroup)<-[:CALLS_AT]-(london_calling)
MERGE (london_calling)-[:CALLS_AT_CITY]->(city:City {name: 'London'})
You can see the full plan in the last image in the previous section, and you can see the Eager operator in dark blue on the very left. This is what we want to get rid of.

The query plan gives us some clue as to why it added the operator. We see that it says that it’s a conflict for the City label (just as we hinted to earlier). It also says it’s a read/set conflict for operators 3 and 8. For those numbers to make sense, we need to look at the textual representation of the execution plan, which looks like the image below (this is the same as the last image in the previous section, but reversed, so you read it bottom-up instead of top-down):
+------------------+----+--------------------------------------------------------------------------------------------+----------------+---------------------+
| Operator | Id | Details | Estimated Rows | Pipeline |
+------------------+----+--------------------------------------------------------------------------------------------+----------------+---------------------+
| +ProduceResults | 0 | | 2134 | |
| | +----+--------------------------------------------------------------------------------------------+----------------+ |
| +EmptyResult | 1 | | 2134 | |
| | +----+--------------------------------------------------------------------------------------------+----------------+ |
| +Apply | 2 | | 2134 | |
| | +----+--------------------------------------------------------------------------------------------+----------------+ |
| | +LockingMerge | 3 | CREATE (city:City {name: $autostring_0}), (london_calling)-[anon_1:CALLS_AT_CITY]->(city), | 2134 | |
| | | | | LOCK(london_calling) | | |
| | | +----+--------------------------------------------------------------------------------------------+----------------+ |
| | +Filter | 4 | city:City AND city.name = $autostring_0 | 0 | |
| | | +----+--------------------------------------------------------------------------------------------+----------------+ |
| | +Expand(All) | 5 | (london_calling)-[anon_1:CALLS_AT_CITY]->(city) | 0 | |
| | | +----+--------------------------------------------------------------------------------------------+----------------+ |
| | +Argument | 6 | london_calling | 2134 | Fused in Pipeline 2 |
| | +----+--------------------------------------------------------------------------------------------+----------------+---------------------+
| +Eager | 7 | read/set conflict for label: City (Operator: 3 vs 8) | 2134 | In Pipeline 1 |
| | +----+--------------------------------------------------------------------------------------------+----------------+---------------------+
| +Expand(All) | 8 | (station)<-[anon_0:CALLS_AT]-(london_calling) | 2134 | |
| | +----+--------------------------------------------------------------------------------------------+----------------+ |
| +NodeByLabelScan | 9 | station:LondonGroup | 18 | Fused in Pipeline 0 |
+------------------+----+--------------------------------------------------------------------------------------------+----------------+---------------------+
The numbers it refers to is the Id column, so it’s the set (CREATE) on the LockingMerge (row 3) that conflicts with the read on the Expand(All) (row 8).
As mentioned above, it’s because the planner doesn’t know that london_calling cannot be the node created in the MERGE. The City node (London) created on row 3 could be picked up in later iterations of the Expand(All) on row 8, which is why it adds the eager to make sure Expand(All) has completed before proceeding to the LockingMerge.
So what we need to do is tell the planner to only consider CallingPoint nodes for london_calling (we know that only CallingPoint nodes has the CALLS_AT relationship, but we need to be explicit about it because the planner doesn’t know). And since we don’t assign the CallingPoint label to the city nodes created, it’s clear that those can’t impact the MATCH.
MATCH (station:LondonGroup)<-[:CALLS_AT]-(london_calling:CallingPoint)
MERGE (london_calling)-[:CALLS_AT_CITY]->(city:City {name: 'London'})
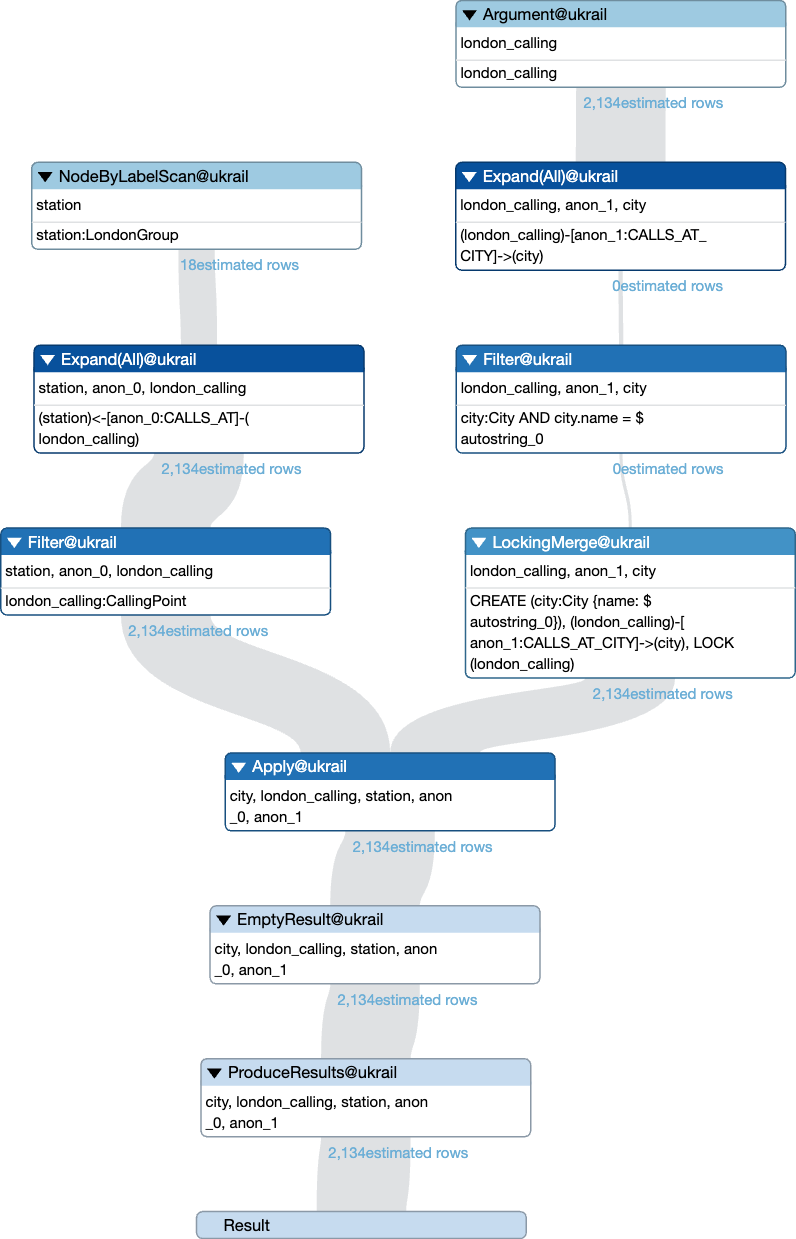
As we see, the Eager is gone. Now, not all Eager operators are that easy to get rid of, and sometimes you can’t. But it is well-invested time to have a go at it at least.
And even if it isn’t possible to remove the Eager, it might be possible to change it so that you have it in a place where you have fewer incoming rows. Also, it’s better on the right-hand side of an Apply (i.e., in the right-hand “arm” of the Y-shaped plan above).
LP Eagerness
How does the planner know if Eager operators are needed? This is done in a subpart of the query planner called Eagerness Analysis. This was completely rewritten in Neo4j version 5.19 (released in April 2024).
The previous version was called IR Eagerness because the analysis was done on the Intermediate Representation (i.e., the parsed query before planning). The new, rewritten version is called LP Eagerness because it is done on the Logical Plan (essentially the query plans we’ve looked at in this article). Doing the analysis on the Logical Plan has several benefits:
- It is more Eager Optimal
- It has better maintainability
- It has better observability
An Eager Optimal plan is a plan that uses the fewest possible Eager operators while still producing the correct result. As we saw in the example with the UK Railway, it sometimes inserts an Eager that isn’t actually needed. A query must never give the wrong result, so it will rather add one Eager too much than to skip one too many. But the more Eager Optimal a plan is, the more performant it will be and the less the risk there will be of running out of memory. On a benchmarking run of about 500 read/write queries, less than 80 percent were Eager Optimal with IR Eagerness, while more than 90 percent were Eager Optimal with LP Eagerness.
The new eagerness analysis routine is easier to maintain and keep robust for the future. This is great for the software engineers that develop and maintain the query planner, and maybe less interesting for us as users — except I think it’s pretty nice to have a robust planner.
A more important benefit for us as users and as someone who wants to optimize the eagerness of a query is the observability that comes with LP Eagerness. In the old IR Eagerness, we, as users, didn’t get any information as to why an Eager Operator was added. We could just see that it had been. But now we get the tips in the comments, like the “read/set conflict for label: City (Operator: 3 vs. 8)” hint we got in the plan we looked at earlier.
Further Reading
There’s a lot more to learn in the land of eagerness analysis, and it’s a difficult art to master. Here’s another blog, written by my colleague Jennifer Reif a couple of years ago. At the time, there was only IR Eagerness, but it’s still relevant today. It shows some other ways to avoid the Eager Operator.
Cypher Sleuthing: the eager operator
Footnotes
* Sort doesn’t have to keep all rows in memory in all cases. If you, for example, do an ORDER BY x LIMIT y, it’ll only need a window with y rows in memory. But it is still eager in the sense that it can’t start to stream the result until it has seen all rows.
** As this query is written in the blog, multiple London nodes will be created — one for each calling point. That would be solved by rewriting the query as below. The same would apply with the Eager operator, but the plan gets a bit more complex, so we left it as it is in the blog.
MATCH (station:LondonGroup)<-[:CALLS_AT]-(london_calling)
MERGE (city:City {name: 'London'})
MERGE (london_calling)-[:CALLS_AT_CITY]->(city)
*** The difference between EXPLAIN and PROFILE is that EXPLAIN never runs the query; it just plans it and shows you what the plan looks like with the estimates done. PROFILE shows you the same plan, but since it did execute the query, it also shows the actual number of rows from each operator, so you get more information. However, if it’s a write query and you don’t actually want to alter your data, or if the query is too big to complete successfully, you may want to stick to EXPLAIN.
An Eagerness Carol was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Find Similar Patient Journeys With Neo4j Aura Graph Analytics
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It