


Enhancing Hybrid Retrieval With Graph Traversal Using the GraphRAG Python Package

Senior Software Engineer, AI
7 min read


In previous posts in this series on the Neo4j GraphRAG Python package, we demonstrated how you can enhance your GraphRAG applications by going beyond simple vector search, using some of the advanced retrievers available in the package. We illustrated how adding a graph traversal step to vector search enables the retrieval of valuable information in addition to that returned by vector search alone. We also showed how combining full-text search with vector search can match queries to data in the Neo4j database that would otherwise be missed by vector search alone. In this post, we’ll explore the HybridCypherRetriever, which combines hybrid search and graph traversal techniques to significantly improve retrieval in GraphRAG applications.
Setup
Make sure you’ve installed the GraphRAG Python package, the Neo4j Python driver, and the OpenAI Python package.
pip install neo4j neo4j-graphrag openai
We’re going to make use of the same pre-configured Neo4j demo database that we used in the previous posts:
- The GraphRAG Python package
- Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package
- Hybrid Retrieval for GraphRAG Applications Using the GraphRAG Python Package for Python
This database simulates a movie recommendations knowledge graph. For details on the database, read the setup section of the first blog, Getting Started With the Neo4j GraphRAG Python Package.
You can access the database through a web browser at https://demo.neo4jlabs.com:7473/browser/ using “recommendations” as both the username and password. Use the following snippet to connect to the database in your application:
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
Additionally, make sure to export your OpenAI key:
import os os.environ["OPENAI_API_KEY"] = "sk-…"
Hybrid Search and Graph Traversal
In Getting Started With the GraphRAG Python Package, we demonstrated how to use a vector retriever to query a vector index containing movie plots. This allowed us to retrieve movie nodes from a Neo4j database, providing context for an LLM to answer user queries. However, these movie nodes lacked details, such as the actors who starred in each film. Consequently, they couldn’t answer questions like “Who were the actors in the movie about the magic jungle board game?”
Fortunately, in the second blog, Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package, we discussed the VectorCypher retriever, which enables the use of a Cypher query to retrieve additional nodes connected to the initial movie nodes. This approach allowed us to retrieve and return actor nodes linked to each movie node, thus enabling answers to questions about specific actors.
In the third blog, Hybrid Retrieval for GraphRAG Applications Using the Neo4j GraphRAG Python Package, we discussed the limitations of vector search, particularly when user queries rely on exact word or phrase matching, such as when an exact date is required. To address this, we incorporated full-text search into our retrieval process, which matches texts based on lexical similarity (i.e., the exact wording) rather than semantic similarity, which is the basis of vector search. We demonstrated how the Hybrid Retriever, which combines the results of both vector search and full-text search, could find and return the correct movie nodes for queries like “What is the name of the movie set in 1375 in Imperial China?”
But what if we wanted to combine these approaches? Using hybrid search and graph traversal together allows us to answer even more complex questions than either method could handle alone — questions like “What are the names of the actors in the movie set in 1375 in Imperial China?”
The Limitations of the Vector Cypher and Hybrid Retrievers
Before we start, let’s take a look at how the VectorCypherRetriever and HybridRetriever handle this question to see if we even need to use a new retriever.
First the VectorCypherRetriever:
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import VectorCypherRetriever
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retrieval_query = """
MATCH
(actor:Actor)-[:ACTED_IN]->(node)
RETURN
node.title AS movie_title,
node.plot AS movie_plot,
collect(actor.name) AS actors;
"""
retriever = VectorCypherRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
retrieval_query=retrieval_query,
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
That returns the following:
items = [
RetrieverResultItem(
content="",
metadata=None,
),
RetrieverResultItem(
content="",
metadata=None,
),
RetrieverResultItem(
content="",
metadata=None,
),
]
metadata = {"__retriever": "VectorCypherRetriever"}
Unfortunately, this retriever doesn’t return the correct movie (Musa the Warrior). However, using a full-text index could be beneficial here, as it would allow us to precisely match the date (1375) if it’s mentioned in the movie’s description.
For a more detailed explanation of this retriever, as well as a walkthrough of the code snippet above, see Enriching Vector Search With Graph Traversal Using the GraphRAG Python Package.
Now let’s try the HybridRetriever:
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import HybridRetriever
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
That returns the following:
items = [
RetrieverResultItem(
content="{'title': 'Musa the Warrior (Musa)', 'plot': '1375. Nine Koryo warriors, envoys exiled by Imperial China, battle to protect a Chinese Ming Princess from Mongolian troops.'}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China III (Wong Fei-hung tsi sam: Siwong tsangba)', 'plot': "Master Wong and his disciples enroll in the 'Dancing Lion Competition' to stop an assassination plot and to battle an arrogant, deceitful opponent."}",
metadata={"score": 0.9975943434767434},
),
]
metadata = {"__retriever": "HybridRetriever"}
With this retriever, although we match the correct movie (Musa the Warrior), we don’t return the actors, as these are stored in separate actor nodes and we need an additional graph traversal step to retrieve these nodes along with the movie nodes.
For a more detailed explanation of this retriever, as well as a walkthrough of the code snippet above, see Hybrid Retrieval for GraphRAG Applications Using the GraphRAG Python Package for Python.
The Hybrid Cypher Retriever
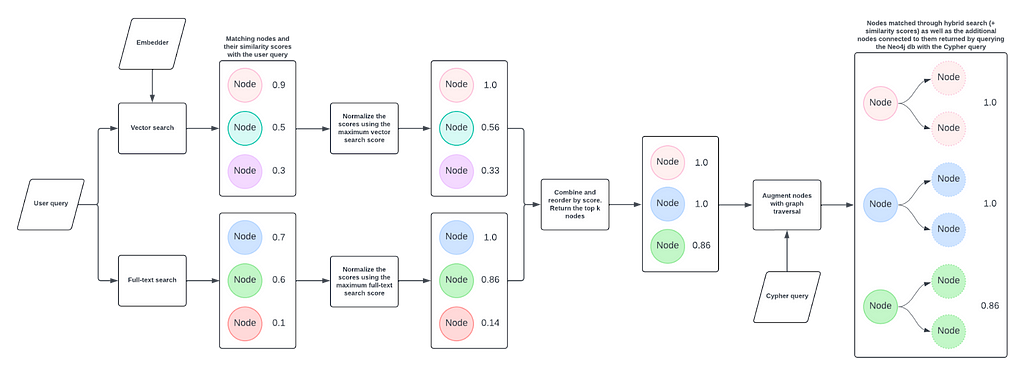
The HybridCypherRetriever enhances the hybrid search process by adding a graph traversal step. It begins by identifying an initial set of nodes through a combined search over vector and full-text indexes, then uses a specified Cypher query to retrieve additional information from the graph for each of these nodes.
To make use of this retriever, we first need to write a Cypher query to specify exactly what additional information to fetch along with each of the nodes retrieved through hybrid search. Given we are looking to answer questions about actors in movies, we can use the following query:
retrieval_query = """ MATCH (actor:Actor)-[:ACTED_IN]->(node) RETURN node.title AS movie_title, node.plot AS movie_plot, collect(actor.name) AS actors; """
We then pass this query to the HybridCypherRetriever with the names of the vector and full-text indexes we want to search. As with the previous blogs in this series, we’ll be searching the movie plots and we’ll use the moviePlotsEmbedding vector index and the movieFulltext full-text index.
Finally, we also pass an embedding model to the retriever. We use the text-embedding-ada-002 model as the movie plot embeddings in the demo database were originally generated using it:
from neo4j import GraphDatabase
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import HybridCypherRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridCypherRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
retrieval_query=retrieval_query,
embedder=embedder,
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
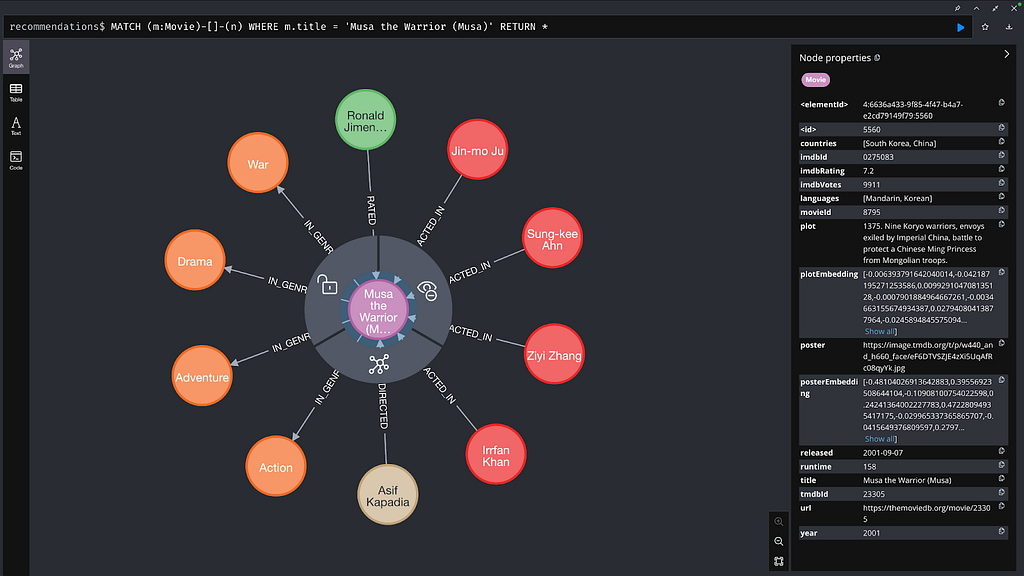
Querying our database retriever using this retriever returns the correct movie (Musa the Warrior) along with its actors:
items = [
RetrieverResultItem(
content="",
metadata=None,
),
RetrieverResultItem(
content="",
metadata=None,
),
RetrieverResultItem(
content="",
metadata=None,
),
]
metadata = {"__retriever": "HybridCypherRetriever"}
Which returns the correct answer to our query:
The names of the actors in the movie set in 1375 in Imperial China, "Musa the Warrior (Musa)," are Irrfan Khan, Ziyi Zhang, Sung-kee Ahn, and Jin-mo Ju.
Summary
In this blog, we demonstrated how to use the advanced HybridCypherRetriever from the GraphRAG Python package in your GraphRAG application. We highlighted the limitations of hybrid search and vector search with graph traversal individually, and showed how combining these techniques enables you to answer more complex and nuanced questions.
We invite you to use the neo4j-graphrag package in your projects and share your insights via comments or on our GraphRAG Discord channel.
The package code is open source, and you can find it on GitHub. Feel free to open issues there.
GitHub – neo4j/neo4j-graphrag-python: Neo4j GraphRAG for Python
Enhancing Hybrid Retrieval With Graph Traversal Using the Neo4j GraphRAG Python Package was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI

Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces

