


Enhancing Word Embedding with Graph Neural Networks

Graph ML and GenAI Research, Neo4j
16 min read

Natural Language Processing (NLP) has seen rapid advancements in recent years. One important aspect of this progress has been the use of embeddings, which are numerical representations of words or phrases that capture their meaning and relationships to other words in a language.
Embeddings can be used in a wide range of NLP tasks, such as document classification, machine translation, sentiment analysis, and named entity recognition. Furthermore, with the availability of large pre-trained language models like GPT-3, embeddings have become even more critical for enabling transfer learning across a range of language tasks and domains. As such, embeddings are closely tied to the rapid advancements in NLP.
On the other hand, recent advancements in graphs and graph neural networks have led to improved performance on a wide range of tasks, including image recognition, drug discovery, and recommender systems.
In particular, graph neural networks have shown great promise in learning representations of graph-structured data, where the relationships between data points provide a signal that improves the accuracy of downstream machine-learning tasks.
In this blog post, you’ll discover how to harness the power of graph neural networks to capture and encode the relationships between data points and enhance document classification accuracy. Specifically, you will train two models to predict a medium article’s tags.

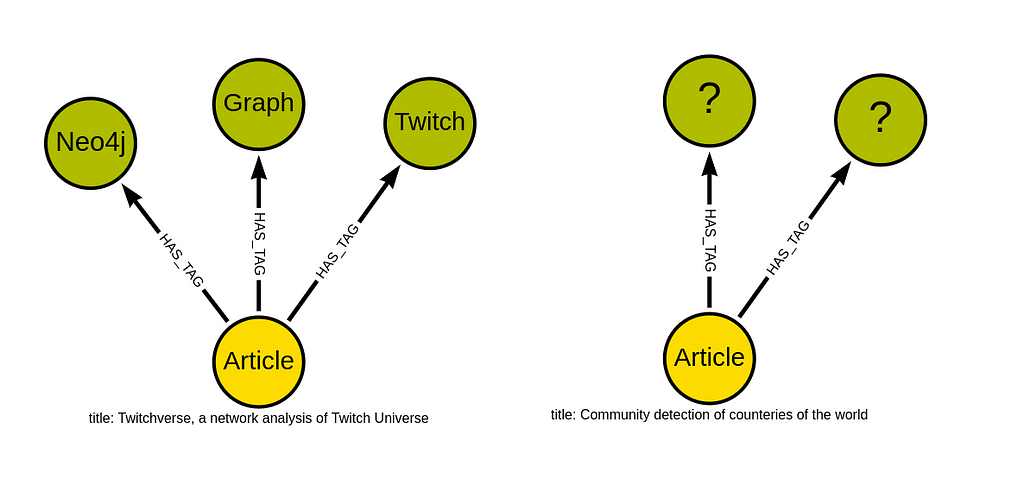
Most medium articles have relevant tags assigned to them by the author for easier discoverability and search performance. Additionally, you can think of these tags as a categorization of articles. Each article can have up to five tags or categories it belongs to, as shown in the above image. Therefore you will train two classification models to perform a multi-label classification, where each article can have one or more tags assigned to them.
The first classification model will use OpenAI’s latest embeddings (text-embedding-ada-002) of the article’s title and subtitle as the input features. This model will provide a baseline accuracy you will try to improve using a graph neural network algorithm called GraphSAGE. Interestingly, word embeddings can be and will be used in this example as input to GraphSAGE.
During training, the GraphSAGE algorithm then leverages these word embeddings to iteratively aggregate information from neighboring nodes, resulting in powerful node-level representations that can improve the accuracy of downstream machine-learning tasks like document classification.
In short, this blog post explores the use of graph neural networks to improve word embeddings by taking into account the relationships between data points.
When the relationships between data points are relevant and predictive, graph neural networks can learn more meaningful and accurate representations of text data and, consequently, increase the accuracy of downstream machine learning models.
Medium Dataset
There are a couple of medium article datasets available on Kaggle. However, none of them contain any relationships between articles. What type of relationships between articles would even be predictive for predicting their tags? Medium has added the ability for users to create lists that can help them bookmark and curate the content they have or intend to read.
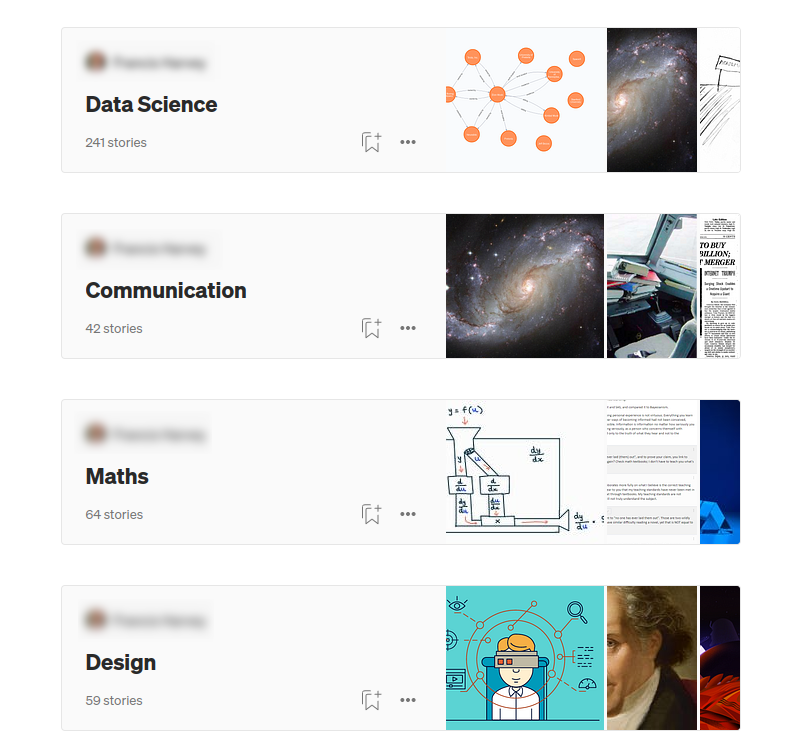
This image presents an example where the user created four lists of articles based on their topics. For example, most articles were grouped under the Data Science list, while other articles were added to the Communication, Maths, and Design lists. The idea is that if two articles are in the same list, they are somewhat more similar than if they don’t have any common lists. You can think of medium lists as human-annotated relationships between articles that can help you find and potentially recommend similar articles.
There is one exception to this assumption. Some users create vast reading lists that contain all sorts of articles.
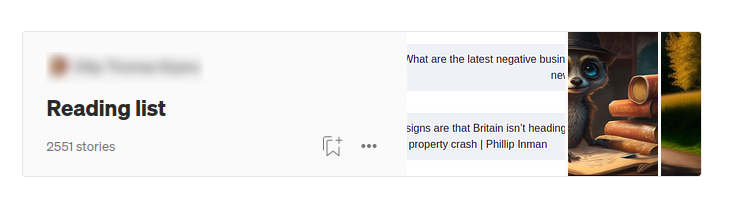
Interestingly, most of these lists with a vast amount of articles have an identical Reading list title. So it has to be some sort of default value by Medium or something, as I have noticed the reading list title with a couple of users.
Unfortunately, there are no publicly available datasets with information about the Medium articles as well as the user lists they belong to.
Therefore, I had to spend an afternoon parsing the data. I retrieved information about 55 thousand medium articles from 4000 user lists.
Preparing Neo4j Environment
The graph construction and GraphSAGE training will be executed in Neo4j. I like Neo4j as it offers a nicely designed graph query language called Cypher as well as a Graph Data Science plugin that contains more than 50 graph algorithms that cover most of graph analytics workflow. Therefore, there is no need to use multiple tools to create and analyze the graph.
The graph schema of the Medium dataset if the following:
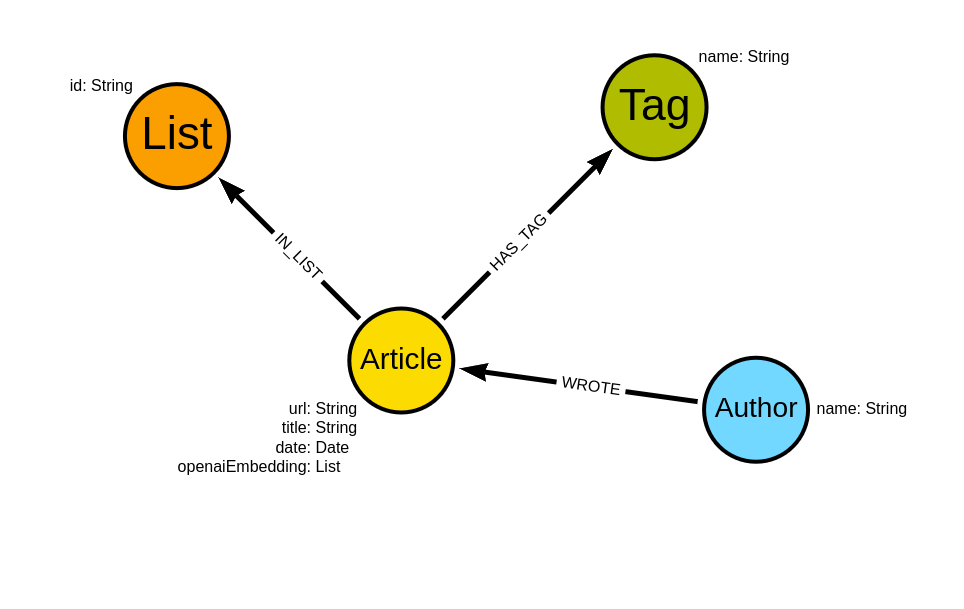
The schema revolves around Medium articles. We know the url, title, and date of the article. Additionally, I have calculated the OpenAI’s embeddings using the text-embedding-ada-002 model based on the article title and subtitle and stored them as openaiEmbedding property. Additionally, we know who wrote the article, which user’s lists it belongs to, and its tags.
I have prepared two options for you to import the medium dataset into Neo4j database. You can execute the following Jupyter notebook and import the dataset from Python. This option also works with Neo4j Sandbox environment (use blank graph data science project).
blogs/Import.ipynb at master · tomasonjo/blogs
The other option is to restore the Neo4j database dump I have prepared.
The dump has been created with Neo4j version 5.5.0, so make sure to use that version or later. The easiest way to restore the database dump is to use the Neo4j Desktop environment.
Additionally, you will need to install the APOC and GDS libraries if you are using the Neo4j Desktop environment.
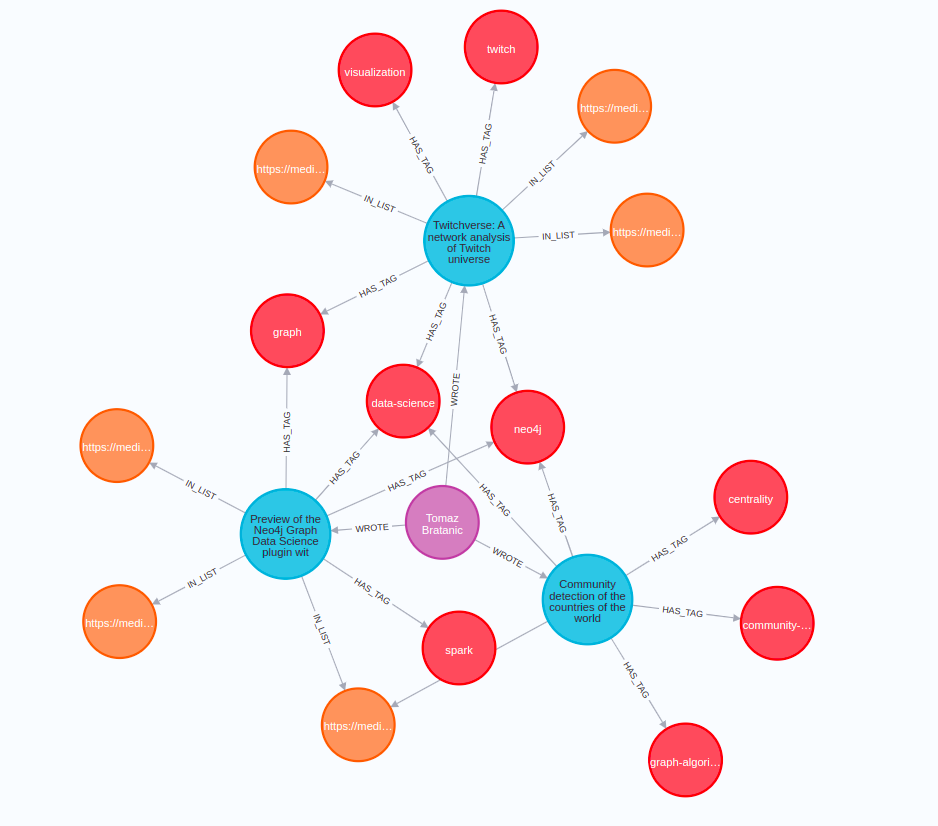
After the database import is finished, you can run the following Cypher statement in Neo4j Browser to verify that the import was successful.
MATCH p=(n:Author)-[:WROTE]->(d)-[:IN_LIST]->(), p1=(d)-[:HAS_TAG]->()
WHERE n.name = "Tomaz Bratanic"
RETURN p,p1 LIMIT 25
The result will contain a couple of articles I have written along with their lists and tags.
Now it is time for the practical part of this blog post. All the analysis code is available as a Jupyter Notebook.
blogs/Classification with GraphSAGE.ipynb at master · tomasonjo/blogs
Exploratory Analysis
We will be using the Graph Data Science Python Client to interface with Neo4j and its Graph Data Science plugin. It is an excellent addition to the Neo4j ecosystem, allowing us to execute graph algorithms using pure Python code. Check out my introductory blog post for more information.
First, we will evaluate the distribution of tags per medium article.
dist_df = gds.run_cypher("""
MATCH (a:Article)
RETURN count{(a)-[:HAS_TAG]->()} AS count
""")
sns.displot(dist_df['count'], height=6, aspect=1.5)
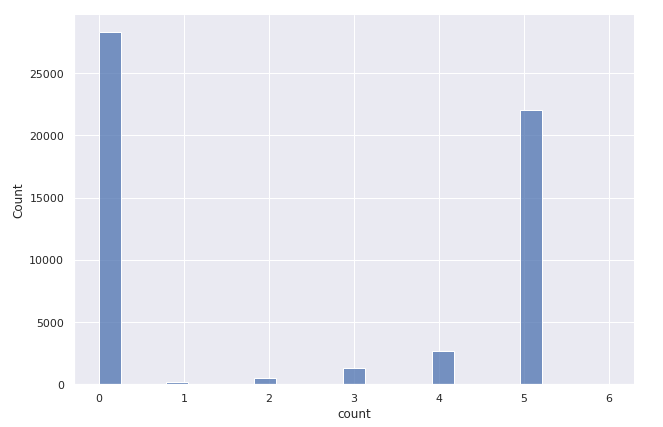
Around 50% of articles have no tags present.
There are two reasons for that. Either the author did not use any, or the scrapping process failed to retrieve them for various reasons, like medium publications having custom HTML structures. However, it is not a big deal as we still have more than 25 thousand articles with their tags present, allowing us to train and evaluate the multi-label classification model of article tags. Most authors choose to use five tags per article, which is also the upper limit that the Medium platform allows.
Next, we will evaluate if any articles are not part of any user lists.
gds.run_cypher(
"""
MATCH (a:Article)
RETURN exists {(a)-[:IN_LIST]-()} AS in_list,
count(*) AS count
ORDER BY count DESC
"""
)
The results show that all articles belong to at least one list. Identifying isolated nodes (nodes with no connection) is a critical part of any graph analytics workflow, as we have to pay special attention to them while calculating node embeddings. Luckily, this dataset contains no isolated nodes, so we don’t have to worry about that.
In the last part of the exploratory analysis, we will examine the most frequent tags. Here, we will construct a word cloud of tags present in at least 100 articles.
tags = gds.run_cypher(
"""
MATCH (t:Tag)
WITH t, count {(t)<--()} AS size
WHERE size > 100
RETURN t.name AS tag, size
ORDER BY size DESC
"""
)
d = {}
for i, row in tags.iterrows():
d[row["tag"]] = row["size"]
wordcloud = WordCloud(
background_color="white", colormap="tab20c", min_font_size=1
).generate_from_frequencies(d)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

The most frequent tags are data science, artificial intelligence, programming, and machine learning.
Multi-Label Classification
As mentioned, we will train a multi-label classification model to predict tags of a Medium article. Therefore, we will use the scikit-multilearn library to help with data splitting and model training.
I noticed that the dataset split with scikit-multilearn library does not provide a random seed parameter, and therefore, the dataset split is not deterministic. F
or a proper comparison of the baseline model trained on OpenAI’s word embedding and a model based on GraphSAGE embeddings, we will perform a single dataset split so that both model versions use the same training and test examples. Otherwise, there could be some differences between the models’ accuracy based solely on the dataset split.
The word embeddings are already stored in the graph, so we only need to calculate the node embeddings using the GraphSAGE algorithm before we can train the classification models.
GraphSAGE
GraphSAGE is a convolutional graph neural network algorithm. The key idea behind the algorithm is that we learn a function that generates node embeddings by sampling and aggregating feature information from a node’s local neighborhood. As the GraphSAGE algorithm learns a function that can induce the embedding of a node, it can also be used to induce embeddings of a new node that wasn’t observed during the training phase. This is called inductive learning.
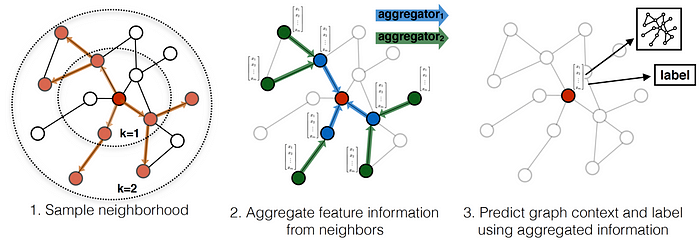
Neighborhood exploration and information sharing in GraphSAGE. [1]
If you want to learn more about the training process and the math behind the GraphSAGE algorithm, I suggest you take a look at the An Intuitive Explanation of GraphSAGE blog post by Rıza Özçelik or the official GraphSAGE site.
Monopartite Projection With Node Similarity Algorithm
GraphSAGE supports graphs with multiple types of nodes, where each type of node has different features representing it. In our example, we have Article and List nodes. However, I have decided to simplify the workflow by performing a monopartite projection.
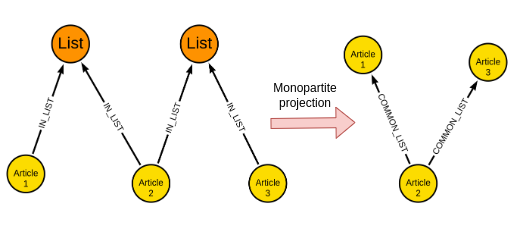
Monopartite projection is a frequent step in graph analysis. The idea is to take a bipartite graph (graph with two node types) and output a monopartite graph (graph with only one node type).
In this specific example, we can create a relationship between two articles if they are part of the same list. Additionally, the number of shared lists or a normalized value like the Jaccard coefficient can be stored as a relationship property.
Since the monopartite projection is a common step in graph analysis, the Neo4j Graph Data Science library offers a Node Similarity algorithm to help us with it.
First, we need to project an in-memory graph. We will include the Article and List nodes along with the IN_LIST relationships. Additionally, we will include the openaiEmbedding node properties.
G, metadata = gds.graph.project(
"articles",
["Article", "List"],
"IN_LIST",
nodeProperties=["openaiEmbedding"]
)
Now we can perform the monopartite projection using the Node Similarity algorithm. One thing to note is that the default value of the topK parameter is 10, meaning that each node will be connected to only its ten most similar nodes. However, in this example, we want to create a relationship between all articles in the user list. Therefore, we will use a relatively high value of the topK parameter.
gds.nodeSimilarity.mutate(
G, topK=2000, mutateProperty="score", mutateRelationshipType="SIMILAR"
)
We have used the mutate mode of the algorithm which stores the results back to the in-memory projected graph. The SIMILAR relationship has been created between all pairs of articles that share at least a single user list.
Training the GraphSAGE Model
The GraphSAGE algorithm is inductive, meaning that it can be used to generate embeddings for nodes that were previously unseen during training. The inductive nature allows us to train the GraphSAGE model only on a subset of the graph and then generate the embeddings for all the nodes.
Training the GraphSAGE model only on a subset of the graph saves us time and compute power, which is useful when dealing with large graphs. While our graph is not that large, we can use this example to demonstrate how to sample the training subset of the graph efficiently.
Random walk with restarts sampling
The idea behind random walk with restarts sampling is quite simple. The algorithm takes random walks from a set of predefined start nodes. At each step of the walk, there is a probability that the current random walk stops and a new one starts from the set of start nodes. The user can define the start nodes. If no start nodes are defined, the algorithm chooses them uniformly at random.
I thought it would be interesting to show you an example of choosing a start node manually. So we will begin by executing the Weakly Connected Components algorithm to evaluate how connected the graph of articles is. A weakly connected component is a set of nodes within the graph where a path exists between all nodes in the set if the direction of relationships is ignored.
A weakly connected component can be considered an island that nodes from other components cannot reach.
While the algorithm identifies connected sets of nodes, its output can help you evaluate how disconnected the overall graph is.
wcc = gds.wcc.stream(G)
wcc_grouped = (
wcc.groupby("componentId")
.size()
.to_frame("componentSize")
.reset_index()
.sort_values("componentSize", ascending=False)
.reset_index()
)
print(wcc_grouped)
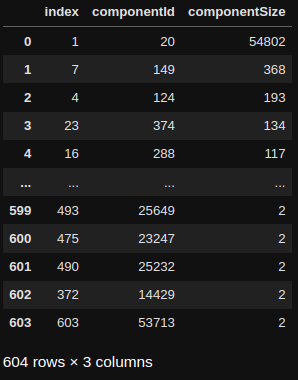
There is a total of 604 connected components in our graph. The largest component contains 98% of all nodes, while the other ones are smaller, with many containing only two nodes. If a component contains only two nodes, it means that we have a medium user list that has only two articles in it, and those two articles are not part of any other lists.
We executed the Weakly Connected Component algorithm to identify a node that belongs to a large connected component and, therefore, can be used as a starting node of the sampling algorithm. For example, if we used a node with only one neighbor, the sampling algorithm couldn’t perform longer walks to subsample the graph efficiently.
Fortunately, the sampling algorithm is implemented to automatically expand the set of start nodes if the random walks do not visit any new nodes. However, as we have used a start node from the largest connected component with 98% of all nodes, the algorithm won’t have to expand the set of start nodes automatically.
largest_component = wcc_grouped["componentId"][0]
start_node = wcc[wcc["componentId"] == largest_component]["nodeId"][0]
trainG, metadata = gds.alpha.graph.sample.rwr(
"trainGraph",
G,
samplingRatio=0.20,
startNodes=[int(start_node)],
nodeLabels=["Article"],
relationshipTypes=["SIMILAR"],
)
The sampling ratio parameter defines the fraction of nodes in the original graph to be sampled. For example, when using the value 0.20 for the sampling ratio, the sampled subgraph will be 20% the size of the original graph. Additionally, we need to define that the random walks can only visit Article nodes through SIMILAR relationships by using the nodeLabels and relationshipTypes parameters.
GraphSAGE Training
Finally, we can go ahead and train the GraphSAGE model on the sampled subgraph.
gds.beta.graphSage.train(
trainG,
modelName="articleModel",
embeddingDimension=256,
sampleSizes=[10, 10],
searchDepth=15,
epochs=20,
learningRate=0.0001,
activationFunction="RELU",
aggregator="MEAN",
featureProperties=["openaiEmbedding"],
batchSize=10,
)
The GraphSAGE algorithm will use the openaiEmbedding node property as input features. The GraphSAGE embeddings will have a dimension of 256 (vector size). While I have played around with hyper-parameter optimization for this blog, I have noticed that the learning rate and activation function are the most impactful parameters.
Generate Embeddings
After the GraphSAGE model has been trained, we can use it to calculate the node embeddings for all the Article nodes in the original larger projected graph and consider only the SIMILAR relationships.
gds.beta.graphSage.write(
G,
modelName="articleModel",
nodeLabels=["Article"],
writeProperty="graphSAGE",
relationshipTypes=["SIMILAR"],
)
This time, we used the write mode to store the GraphSAGE embeddings as node properties in the database.
Classification model
We have prepared both the OpenAI and GraphSAGE embeddings. The only thing left is to train the models and compare their performance.
First, we will label the article tags we want to predict. I arbitrarily decided to only include tags that are present in at least 100 articles. The target tags will be labeled with a secondary Target label.
gds.run_cypher(
"""
MATCH (t:Tag)
WHERE count{(t)<--()} > 100
SET t:Target
RETURN count(*) AS count
"""
)
We have labeled 161 tags we want to predict. Remember, the word cloud visualization above took the same 161 tags and visualized them according to their frequencies.
As we will use the scikit-multilearn library, we need to export the relevant information from Neo4j.
data = gds.run_cypher(
"""
MATCH (a:Article)-[:HAS_TAG]->(tag:Target)
RETURN a.url AS article,
a.openaiEmbedding AS openai,
a.graphSAGE AS graphSAGE,
collect(tag.name) AS tags
"""
)
Next, we need to construct a binary matrix that indicates the presence of tags for a given article. Essentially, you can think of it as one-hot-encoding of tags per article. So, we can utilize the MultiLabelBinarizer procedure to achieve this.
mlb = MultiLabelBinarizer()
tags_mlb = mlb.fit_transform(data["tags"])
data["target"] = list(tags_mlb)
The scikit-multilearn library offers an improved dataset split for multi-label prediction tasks. However, it does not allow a deterministic approach with a random seed parameter. Therefore, we will perform the dataset split only once for both the word and GraphSAGE embeddings and then train the two models accordingly.
The following function takes in a data frame and the columns that should be separately used as input features to a multi-label classification model and returns the best-performing model while printing the weighted macro and weighted precisions. Here, we use the LabelPowerset approach to multi-label classification.
def train_and_evaluate(df, input_columns):
max_weighted_precision = 0
best_input = ""
# Single split data
X = data[input_columns].values
y = np.array(data["target"].to_list())
x_train_all, y_train, x_test_all, y_test = iterative_train_test_split(
X, y, test_size=0.2
)
# Train a model for each input option
for i, input_column in enumerate(input_columns):
print(f"Training a model based on {input_column} column")
x_train = np.array([x[i] for x in x_train_all])
x_test = np.array([x[i] for x in x_test_all])
# train
classifier = LabelPowerset(LogisticRegression())
classifier.fit(x_train, y_train)
# predict
predictions = classifier.predict(x_test)
print("Test accuracy is {}".format(accuracy_score(y_test, predictions)))
print(
"Macro Precision: {:.2f}".format(
get_macro_precision(mlb.classes_, y_test, predictions)
)
)
weighted_precision = get_weighted_precision(mlb.classes_, y_test, predictions)
print("Weighted Precision: {:.2f}".format(weighted_precision))
if weighted_precision > max_weighted_precision:
max_weighted_precision = weighted_precision
best_classifier = classifier
best_input = input_column
return best_classifier, best_input
With everything prepared, we can go ahead and train the models based on word and graphSAGE embeddings and compare their performance.
p.s. If you are using Google Colab, you might run into OOM problems using the openai embeddings
classifier, best_input = train_and_evaluate(data, ["openai", "graphSAGE"])
The results are the following:
Training a model based on openai column
Test accuracy is 0.055443548387096774
Macro Precision: 0.20
Weighted Precision: 0.36
Training a model based on graphSAGE column
Test accuracy is 0.05584677419354839
Macro Precision: 0.30
Weighted Precision: 0.41
Although the embeddings of the title and subtitle provide some information about their tags, they may not be the most efficient. This could be due to clickbait-style titles that prioritize grabbing attention over accurately describing the content. Furthermore, authors may have different preferences for tagging identical content with varying labels. Despite these challenges, our model predicts 161 labels, many of which have few examples, yielding acceptable results. To further improve accuracy, we can embed the entire article text and evaluate its performance.
Interestingly, using GraphSAGE embeddings enhances classification precision by considering the relationships between articles. Our model’s macro precision improves by ten percentage points, while the weighted precision improves by five. These outcomes demonstrate that GraphSAGE embeddings help identify infrequent tags more effectively. Unlike standard word embedding models, graph neural networks enable us to encode additional relationships between data points, thereby enhancing downstream machine learning models. We have also performed a dimensionality reduction from 1536 to 256 while increasing the performance, which is a great outcome.
Test Predictions
There are almost 50% of articles without any tags in our database. We can test the model on several and manually evaluate the results.
example = gds.run_cypher(
"""
MATCH (a:Article)
WHERE NOT EXISTS {(a)-[:HAS_TAG]->()}
RETURN a.title AS title,
a.openaiEmbedding AS openai,
a.graphSAGE AS graphSAGE
LIMIT 15
"""
)
tags_predicted = classifier.predict(np.array(example[best_input].to_list()))
example["tags"] = [list(mlb.inverse_transform(x)[0]) for x in tags_predicted]
example[["title", "tags"]]
Results
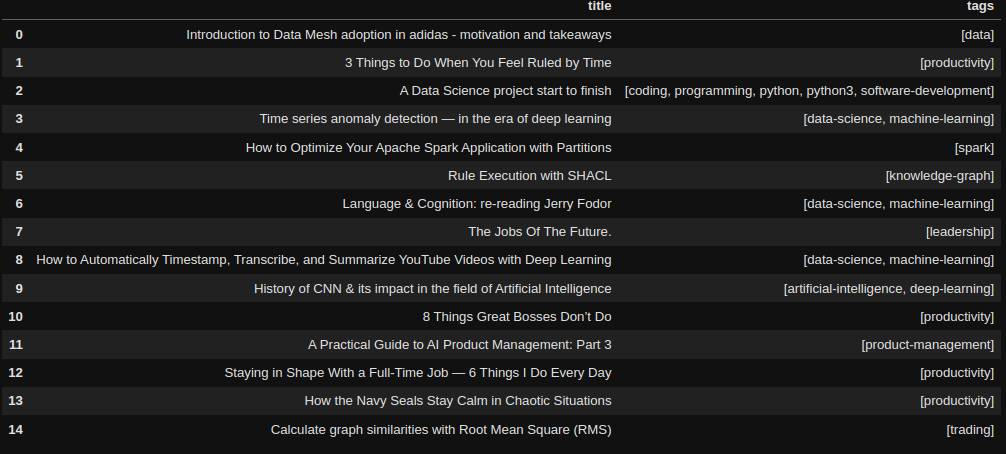
Interestingly, the model mostly assigns one or two labels per article, when most real-world articles have five tags. This is probably one cause for the values of precision scores. Other than that, the results look promising judging by this small sample.
Summary
Traditional word embedding models like word2vec focus on encoding the co-occurrence statistics of words. However, they entirely ignore any other relationships that can be found between data points. For instance, we had users annotate similar articles by placing them in various reading lists. Luckily, graph neural networks offer a bridge between traditional word embeddings and graph embeddings as they allow us to build on top of word embeddings and encode additional information derived from relationships between data points. Therefore, the graph neural networks do not have to start from scratch but can be used to enhance state-of-the-art word or document embeddings.
References
Enhancing Word Embedding with Graph Neural Networks was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles

Transform Static Risk Assessment Into a Dynamic Data-Driven Strategy
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI

Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces
