



As a famous hero once said: With data model flexibility comes great responsibility.
The schema optionality of Neo4j is convenient for rapid prototyping but can turn into quite the nightmare if the data complexity is not tamed as the dataset grows over time.
In scenarios like data import, the external data often needs to be massaged to a “graphier” shape after the initial load.
To address these issues, tools like Liquibase supply high-level database refactorings, and they have successfully done so for over 15 years.
As the author of the Neo4j extension for Liquibase, I wanted to go beyond basic Cypher support and include graph-specific refactorings — and oh boy! It has been as challenging as it has been fun!
Graph Refactoring?

Code Refactoring refers to a practice consisting in re-structuring parts of an existing program without changing their observable behavior.
The name Graph Refactoring comes from the excellent APOC library, which offers, among MANY other things, the apoc.refactor package.
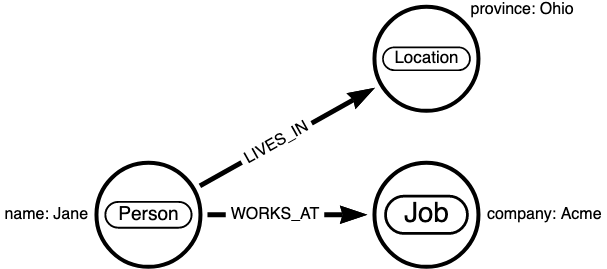
The procedure of interest for the rest of the post is mergeNodes. As its name suggests, mergeNodes fuses a sequence of nodes together, merging their labels, properties, and relationships, as illustrated below:
Liquibase and mergeNodes
Since this is the first graph refactoring ever offered by the Neo4j plugin for Liquibase, I can choose either of these two options:
- Make APOC a requirement for Liquibase/Neo4j users, rely on its existing refactoring, and call it a day
- Implement the mergeNodes functionality on the client side instead
Wise colleagues advised me against option 2, since it would be quite a challenging task.
However, choosing option 1 also means restricting the Neo4j Liquibase user base artificially. Indeed, setting APOC as a requirement means I cannot target vanilla Neo4j deployments anymore. Users have to install the APOC plugin alongside their server.
Don’t get me wrong — as a Neo4j end user or application developer, I would 100 percent pick APOC and rely on its awesome extensions.
As a library developer, though, the perspective is a bit different, and accessibility matters.
If people cannot or do not want to use APOC, I don’t want to deprive them of such a good refactoring capability!
Finally, I frequently fool myself with rhetorical questions like “How hard can this be?”, in which rhetorical here means: ignore the answer and unwisely proceed with carrying out the implementation!
API Brainstorming Time!
Ideally, the mergeNodes API would take the sequence of nodes to merge as input.
Unfortunately, there is no such thing as Node and Relationship persistent objects on the Neo4j driver side of things.
Contrast this with server extensions like APOC’s mergeNodes: they have direct access to the Neo4j server-side Java API (which is also exposed when you use Neo4j as an embedded instance).
The Java API gives you access to persistent Relationship and Node objects, which you can easily modify before programmatically committing the surrounding transaction.
However, on the client side (on the Neo4j driver side), the only way to alter data is to run Cypher queries.
Because of this, the next best thing after persistent Node and Relationship objects is to let the user specify the Cypher pattern that describes the nodes to merge.
That way, I can use that pattern in a larger Cypher query and retrieve the sequence of nodes to merge.
Will it Blend?
At this point, astute readers may frown a bit.
What I describe above is basically Cypher string concatenation and is therefore subject to Cypher injection attacks (like SQL injection attacks but with… Cypher).
Is that a problem? In general, yes, it is!
In the Liquibase context? Not so much.
Running Liquibase migrations allows users to run the arbitrary changes they need to make, with the permissions they require. Since users are in full control of the statements they want to run, SQL / Cypher injection is not really relevant in Liquibase’s threat model.
The API Finally Emerges
As we just established, part of what is needed is the Cypher pattern.
Since I want to use that fragment within a larger Cypher query, I also need the actual Cypher variable name that is bound to the sequence of nodes so I can refer to that sequence later in the query.
For instance, if the pattern is (n:Foo)-[:BAR]->(m:Baz) ORDER BY n.name ASC and the user wants to merge the Foo nodes, I need to know that the variable n refers to the nodes to merge.
Finally, users should be able to control what happens when property conflicts occur — i.e. when two or more nodes about to be merged share the same property name.
In that case, I offer three options (which differ a bit from APOC mergeNodes options):
- Keep the first set value of all the properties with the same name.
- Keep the last set value of all the properties with the same name.
- Keep all the set values of the properties with the same name.
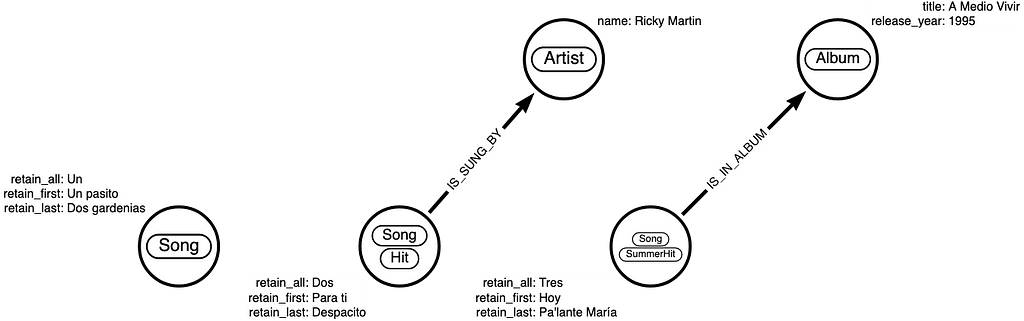
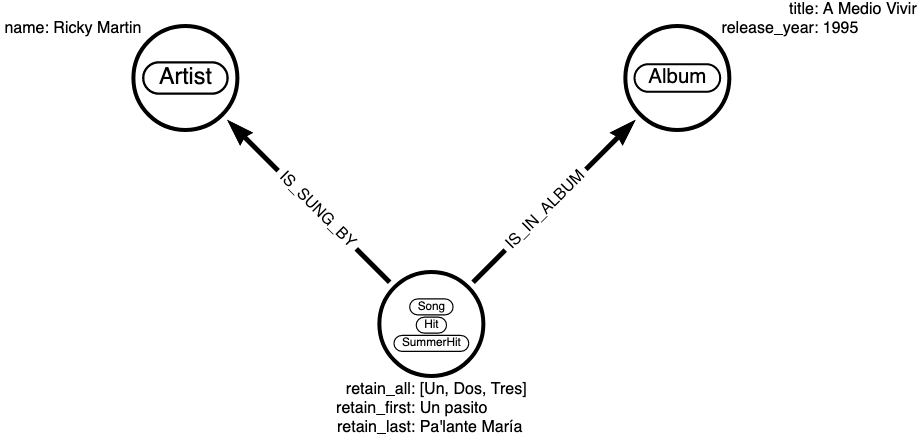
Let’s illustrate what happens with the following example.
- With the KeepFirst policy, the resulting name property would be set to “Foo”
- With the KeepLast policy, the resulting name property would be set to “Bar”
- With the KeepAll policy, the resulting name property would be set to [“Foo”, “Bar”](i.e. an array with both values)
Every encountered property name must match a merge policy.
Since specifying 1 merge policy per property name would be quite tedious, the merge policy defines the matching property names as a regular expression. That way, the policy can be applied to more than one property name.
At this point, I have everything I need to finally define the API of mergeNodes.
Let us see how it looks in Go. (I first explored the API and implementation in that language).
The first parameter is a transaction, since the merge should be an all-or-nothing operation.
This has some implications, but I will come back to these at the end of the post.
Since official Neo4j drivers offer transaction functions (i.e. transaction retryable callbacks), another variant can also be exposed “for free”:
… where neo4j.TransactionWork, as defined by the official Go driver for Neo4j, is a simple type definition:
type TransactionWork func(Transaction) (any, error)
i.e. a simple transaction callback that either returns a result or an error.
The second parameter defines the Cypher pattern (aka fragment) and the Cypher variable that refers to the collection of nodes to merge:
Finally, the last parameter specifies the merge policy for each property name:
Think of PropertyMergeStrategy as an enumeration (yes, enums are awkward in Go).
Now that the API is defined, let’s show an example of how it could be used:
The above program matches an ordered sequence of person nodes and merges them all into the first one. Every property is turned into an array (even if there is only one for a given name). Each array contains all the property values encountered in order, per property name.
A Man, a Plan, an Implementation
The sequence of actions, at the high level, is rather simple:
- Copy all labels to the target node (i.e. the first node of the sequence)
- Copy all properties to the target node
- Copy all relationships to the target node
- Delete the rest of the nodes
While the three first steps can be executed in any order, the last one has to be run last — otherwise, we would lose the nodes and their data too early.
Assuming a vanilla Neo4j deployment, no external Cypher extensions are available. Therefore, I do not think it’s possible to run all these steps in a single query in that scenario.
Let’s break down the number of queries per step, required to perform the merge:
- 1 query to match the nodes labels and 1 to copy them to the target
- 1 to match all the properties, 1 to set them on the target
- 1 to match all relationships, 1 to copy them to the target
- 1 to delete the rest of the nodes
First Hurdle: Repeated Node Matching
Since the first three steps always require matching the sequence of nodes, I tried first to reuse the user-provided Cypher pattern every time.
It turns out that’s a very bad idea.
Let me explain why with a simple example.
Let’s say I want to merge three nodes, with names “Ahmed”, “Jane” , and “Zamora”, sorted by ascending name order.
I copy the labels, so far so good: the “Ahmed”node will get all the extra labels the other nodes have.
Then, let’s say I pick the KeepLast merge policy for the name property.
When I copy the properties, the node previously known as “Ahmed” now holds the value “Zamora”, since “Zamora” is the last node’s name.
When I copy the relationships, problems start to appear.
Why? Because “Ahmed” used to be the first node by ascending name order but has become one of the last, since it’s now named “Zamora”.
Indeed, after the property copy, I have “Jane” as before but I’ve got two “Zamora”! “Jane” becomes the first node of the sequence and that’s not what should happen.
This may seem obvious in retrospect, but I wasted quite a few hours before realizing this approach was a no-go.
What’s needed instead is to retrieve the node IDs in the same user-defined order, once and for all, and use these ordered IDs for all the subsequent queries.
Since the execution happens within a single transaction, IDs are guaranteed to be stable. The usual warnings about ID usage do not apply here.
Second Hurdle: Special Values
This one is a classic, and yet I partly fell for it again.
Labels, property names, and relationship types can all contain special characters.
Since they are not accepted as query parameters, they need to be escaped with tickquotes (e.g.: (:`A Human`)-[:`IS FOLLOWING`]->(:`A Human`)) before being interpolated to the Cypher query.
Note that particular example violates the Cypher style guide.
Anyway, this is luckily a quick fix, but it’s easy to forget!
Third (Non-)Hurdle: Dynamic Property Write in Cypher
The property copy follows three steps:
- Retrieve all the property names and values, in order.
- Process those and generate the copy query.
- Run the query.
I was pleasantly surprised to learn that Cypher allows dynamic property reads. The query needed for the first query is therefore rather concise:
UNWIND $ids AS id
MATCH (n) WHERE id(n) = id
UNWIND keys(n) AS key
WITH {key: key, values: collect(n[key])} AS property
RETURN property
This returns a list of rows. Each row consists of pairs of property names and all the values matching that name, in iteration order.
The key part is n[key], which enables the dynamic lookup of the property of a node or a relationship.
With that, I have all the properties I need and just need to merge the values according to the first policy matching each property name (pick first, pick last, or combine them all).
Finally, the time has come to actually overwrite all the properties of the target node.
I initially had a query like this in mind:
MATCH (n) WHERE id(n) = $id
UNWIND $props AS prop
SET n[prop.key] = prop.value
Unfortunately, n[key] = value is not supported by Cypher.
Then, I went through the unnecessary trouble of generating the set clause for each property one by one. This is unnecessary, because a concise solution already exists in Cypher:
MATCH (n) WHERE id(n) = $id SET n = $props
Boom! As easy as that. Match the first node by its ID and overwrite all its properties, by passing a map parameter named props. SET n += $props is also possible and would overwrite only properties with the same name.
Does it Scale?
The fact that a merge operation runs within a single transaction does have some implications, as I hinted at earlier.
This means, among other things, that if dealing with more data than the server is configured to handle, the transaction will abort before running out of memory.
The best workaround in that situation remains to split the nodes to merge in different batches, but that obviously means that the merge is not an all-or-nothing operation anymore, from a transactional standpoint.
Indeed, if the work is split into 10 batches and the seventh fails, all previous six batches are committed and must not be re-run (unless they are idempotent but that is always feasible).
Liquibase does not support batch execution out of the box. Indeed, Liquibase has been historically designed with relational databases in mind. Refactoring relational databases means altering their structures with DDL statements. These statements are typically less memory intensive than their DML counterparts (with exceptions like adding a new column with a non-NULL default value to a table with a gigantic amount of rows).
In the case of Neo4j, there isn’t really a DDL vs. DML distinction. The model is inferred from the data. The data is the model. As a consequence, DDL-like operations with Neo4j are more subject to scalability issues.
If this ends up being an issue for you, please let me know. Liquibase and I will work on improving the situation.
Conclusion
The initial sandbox project has moved to https://github.com/graph-refactoring/graph-refactoring-go.
The refactoring is also available in the Neo4j extension for Liquibase. Here is a Liquibase change set using the refactoring:
This is only the beginning, of course.
There are plenty of other refactorings to implement.
If you are interested in contributing to the Liquibase extension or implementing a refactoring in your favorite language, drop me a line — let’s make it happen!
Graph Refactoring: The Hard Way was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





