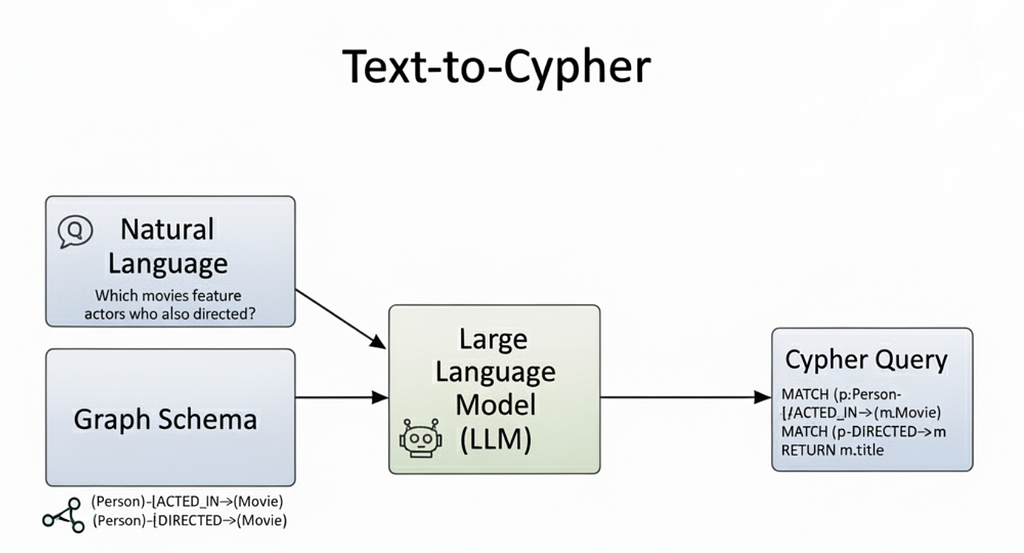
An Extremely Simple but Effective Way to Improve Search Over Text Embeddings

Field Engineer, Neo4j
8 min read

Experiments on AWS, Azure, and GCP
Abstract
In many GenAI solutions built today, e.g., RAG, doing similarity searches over embeddings of text, images, and other data becomes more and more popular. There are quite some approaches proposed and implemented to improve the embedding search, using techniques like embedding model fine-tuning, prompt engineering, and cross-encoder for re-ranking, to name a few.
In this article, I will demonstrate an extremely simple but effective way to improve similarity search, without using ANY of the methods mentioned above. Some samples will be given, and test results shown for embeddings done on all 3 major cloud providers, i.e., Azure OpenAI, Google VertexAI, and AWS Bedrock, using Neo4j APOC ML procedures.
For a more holistic explanation of text embedding, please feel free to check my previous article:
Text Embedding — What, Why and How?
The Goals
In a classical RAG (Retrieval Augmented Generation) solution, the retrieval process often performs a similarity search over the (text) embedding (represented as a data type called vector) of the question (asked in natural language), against text embeddings of content stored in a knowledge base.

For effective vector search, we’d expect a similarity score that:
- There is enough gap between the vectors of higher relevance and those of less relevance.
- There is a reasonable threshold to be used to exclude those irrelevant vectors from the results.
The Samples
Let’s say we have some questions on banking products:
1. 'tell the differences bwteen standard home loan and fixed loan'
2. 'compare standard home loan, line of credit and fixed loan'
3. 'how to calculate interest?'
4. 'what is fixed rate loan?'
5. 'can I make more replayment?'
And a summary of the intent:
The question is about comparing banking product features and summarising differences.
By a quick look at them, it wouldn’t be too hard for us (human beings) to expect that for the above intent, questions #1 and #2 should have higher similarity scores than the rest of the questions.
Let’s test it.
Making Embedding API Calls
As I use Neo4j to store both text and vector data in a knowledge graph, to start quickly, I will just use the machine learning procedures from Neo4j APOC library to get embeddings of text from all three cloud providers.
1. AWS Bedrock
AWS offers Titan Embedding G1 for text embedding tasks, which is available in certain regions by request. AWS access key and keyID are required. It is also required to grant AmazonBedrockFullAccess permission to the user account in IAM.
:param aws_secret_access_key=>'AWS-SECRET-ACCESS-KEY';
:param aws_key_id=>'AWS-KEY-ID';
:param region=>'us-west-2';
:param model=>'amazon.titan-embed-text-v1';
CALL apoc.ml.bedrock.embedding(['Some Text'], {region:$region,keyId:$aws_key_id, secretKey:$aws_secret_access_key, model:$model});
2. Azure OpenAI
On Azure, OpenAI text-embedding-ada-002 is the model that produces text embeddings of 1536 dimensions. The OpenAI API key is required to run:
CALL apoc.ml.openai.embedding(['Some Text'], $apiKey, {}) yield index, text, embedding;
3. GCP VertexAI
On GCP Vertex AI, embeddings for Text (model name textembedding-gecko) is the name for the model that supports text embeddings, which has 768 dimensions. GCP account access token, project ID, and region are required:
CALL apoc.ml.vertexai.embedding(['Some Text'], $accessToken, $project, {region:'<region>'}) yield index, text, embedding;
4. Cosine Similairy Function
In Neo4j’s Graph Data Science library, there is a Cosine Similarity function. If you don’t have it installed, here is a custom function done purely in Cypher.
CALL apoc.custom.declareFunction(
"cosineSimilarity(vector1::LIST OF FLOAT, vector2::LIST OF FLOAT)::FLOAT",
"WITH
reduce(s = 0.0, i IN range(0, size($vector1)-1) | s + $vector1[i] * $vector2[i]) AS dotProduct,
sqrt(reduce(s = 0.0, i IN range(0, size($vector1)-1) | s + $vector1[i]^2)) AS magnitude1,
sqrt(reduce(s = 0.0, i IN range(0, size($vector2)-1) | s + $vector2[i]^2)) AS magnitude2
RETURN
toFloat(dotProduct / (magnitude1 * magnitude2)) AS score;"
);
The Baseline
Let’s start with the Azure OpenAI embedding model using the Cypher statement below to calculate similarity:
CALL apoc.ml.openai.embedding(['The question is about comparing banking products features and summarising differences'],NULL , {})
YIELD index, text, embedding
WITH text AS text1, embedding AS emb1
CALL apoc.ml.openai.embedding(['tell the differences bwteen standard home loan and fixed loan',
'compare standard home loan, line of credit and fixed loan',
'how to calculate interest?',
'what is fixed rate loan?',
'can I make more replayment?'
],NULL , {})
YIELD index, text, embedding
WITH text AS text2, embedding AS emb2, emb1, text1
RETURN text1, text2, custom.cosineSimilarity(emb1, emb2) AS score;
and results are:
╒══════════════════════════════════════════════════════════════════════╤═══════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪═══════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"tell the differences bwteen standard home loan and fixed loan"│0.786548104272935 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"compare standard home loan, line of credit and fixed loan" │0.8082209952027013│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"how to calculate interest?" │0.7799410426972614│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"what is fixed rate loan?" │0.7562771823612668│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"can I make more replayment?" │0.7278839096948918│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴───────────────────────────────────────────────────────────────┴──────────────────┘
The initial results are aligned with what we expected, i.e., question #2 has the highest score followed by #1, and closely by#3. #4 & 5 have relatively lower scores. However, this is not as good as the goals we defined at the beginning of the article:
- Questions #1~3 have similarity scores very close to each other.
- The distance between max and min similarity scores is only about 0.08.
- Question #1 is relevant, but it has a relatively low score, if we consider 0.8 as a reasonable threshold.
For a large amount of vectors to compare, those issues can make the search and filtering more challenging.
Is there any way we can improve this using simple techniques, but not by doing model finetuning or sophisticated prompt engineering?
The Extremely Simple Way
OpenAI Embedding
Of course, we could add some keywords to the questions. For example, by adding ‘question: ‘ to the front of all questions, we’ll have slightly better results,as shown below:
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.8076027901384112│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.8209218883771804│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.7897457504166066│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.7752367420838878│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.7434177316292667│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
We can see now both #1 & #2 are above 0.8, together with scores boosted for all questions except #3, which, in fact, decreased.
A more generic, extremely simple, and effective way is to add some symbols.
For example, if I add ### to the beginning of questions, the scores are boosted further:
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"###question: tell the differences bwteen standard home loan and fixed│0.8153785384022421│
│sing differences" │ loan" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: compare standard home loan, line of credit and fixed loa│0.8396923324014403│
│sing differences" │n" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: how to calculate interest?" │0.8033634786411539│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: what is fixed rate loan?" │0.7924533227169328│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: can I make more replayment?" │0.7517756135667428│
│sing differences" │ │ │
So, I tested various patterns and came up with the summary below:


For OpenAI’s embedding model, it seems adding ### to both sides of the questions can achieve quite good outcomes, which boosted relevant questions more than less relevant ones, and increased distance by 13%+!
What about other embedding models?
AWS Bedrock
The baseline test shows Bedrock / Titan model has differentiated questions #1 & 2 away from the other ones better than OpenAI, as similarity scores have a much bigger distance but much lower absolute values, too.
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤═══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪═══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.48950020909002845│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.49591356152310995│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.3239678489106068 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.32782421303093584│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.10463201924339886│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴───────────────────┘
And the results after applying various patterns:

Again ### shows more influence over the text embedding.
Google VertexAI
VertexAI has a similar distance but lower scores compared to OpenAI.
══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.7222057116992117│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.7196310737891332│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.6515748673785347│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.618704888535842 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.5397404750178617│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴──────────────────┘
And the results after applying some patterns:

It looks like the VertexAI embedding model prefers &&& over ###.
Summary
Embeddings are knowledge of AI. However, even for texts of the same semantic meanings, their embeddings can be very different, which are subject to tokenization and pre-training processes of the language model, and trivial things like special characters/symbols included can have quite significant impacts on the outcomes, too.
Some models, especially subword-based models like BERT, treat symbols as separate tokens or as parts of tokens (like “##” in BERT), which influences the subsequent embeddings.
In models capable of generating context-sensitive embeddings (like transformers), the presence of symbols can change the context of the surrounding words, thus altering their embeddings. However, for closed-sourced LLMs, there is no easy explanation for this, which poses unknown opportunities as well as risks.
For more practical guidance on evaluating embedding & its search, you may find this article helpful, too:
Why Vector Search Didn’t Work for Your RAG Solution?
An Extremely Simple but Effective Way to Improve Search Over Text Embeddings was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Find Similar Patient Journeys With Neo4j Aura Graph Analytics
How a $28 Part Can Bring Down a $5M Machine — and How GenAI Stops It