The Future of Knowledge Graph: Will Structured and Semantic Search Become One?

Field Engineer, Neo4j
13 min read

What LLM & Graph May Bring to the Future of Knowledge Graphs

Abstract
In the last several decades, when people consider building a knowledge-related solution, they tend to look into two distinct directions based on whether data is structured or unstructured. Accordingly, there is the so-called structured search using a query language over a database or semantic search using inferencing and reasoning over the meaning of data, mostly text.
There are also methods to bring certain structures into unstructured data via technologies like entity extraction, entity linking, relation extraction, and so on in order to achieve better accuracy and performance. With the rise of Large Language Models (LLM), there is a new and promising way to bring the two into ONE, i.e., to store both structure and meaning (in the form of vectors created by the text embedding process) in a knowledge graph (KG). We will further explore this idea with an example.
A Brief History of Knowledge Graph
Knowledge graphs have roots in diverse fields, including artificial intelligence, semantic web, and graph theory, and have been built to support various applications over decades. Let’s briefly review KG’s history in the last 60 or so years(already!).
1. 1960s and 1970s — Semantic Networks
Early AI researchers introduced semantic networks as a way to represent knowledge. These graphical structures represented objects (nodes) and relations (edges) between them.
2. 1980s — Frames and Expert Systems
Marvin Minsky introduced the concept of frames, which are data structures for representing stereotypical situations.
Expert systems, computer systems that emulate the decision-making ability of a human expert, became popular. These systems relied heavily on knowledge bases.
3. 1990s — Ontologies and RDF:
The term “ontology” started to be widely used in the context of knowledge representation. It referred to a set of concepts and categories in a subject area, and their relationships.
The Resource Description Framework (RDF) was introduced by the World Wide Web Consortium (W3C) as a standard for describing resources on the web.
4. 2000s — SPARQL and DBpedia:
SPARQL, a query language for Resource Description Framework (RDF), was introduced, allowing for more complex querying of web data.
The launch of DBpedia, which aimed to extract structured information from Wikipedia and to make this information available on the web, was a crucial milestone.
5. 2010s — Rise of Commercial Knowledge Graphs
– Google’s Knowledge Graph: In 2012, Google announced its Knowledge Graph, a structured knowledge base to enhance search results with information gathered from various sources. It changed how information is presented in search, offering direct answers and rich snippets.
— Facebook’s Open Graph: Around the same period, Facebook introduced the Open Graph Protocol, which allowed third-party websites to integrate more seamlessly with the platform.
— Wikidata: Launched by the Wikimedia Foundation in 2012, it acts as a central storage for the structured data of its Wikimedia sister projects, including Wikipedia and Wikimedia Commons.
— Neo4j: This graph database, though not a knowledge graph per se, has been instrumental in the growth of knowledge graph technology. It provides tools and infrastructure for creating, querying, and maintaining graph data structures under a schema called Labelled Property Graph.
RDF Triple Stores vs. Labeled Property Graphs: What’s the Difference? – Graph Database & Analytics
6. 2020s and Beyond: The Era of Neural Knowledge Graph?
A neural knowledge graph combines the structured representation of knowledge graphs with the learning capabilities of neural networks, especially deep learning. The rise of neural knowledge graphs is part of a broader trend in AI research that aims to marry symbolic, rule-based AI (which is interpretable and can be reasoned about explicitly) with subsymbolic, statistical AI (which is adept at handling noisy, real-world data). Early studies have shown promising outcomes from such an approach, and its future is yet to be seen.
Structured or Semantic Search?
Structured Search typically requires certain schema to be defined; e.g., column, row, and fields in a relational database, or node, relationship, and property in a graph database. The biggest benefit of having a predefined schema, which means you need to know what fields or columns are available and their data types, is the precision and powerful features of manipulating data through a query language like SQL for RDBMS and Cypher for graph database.
Meanwhile, Semantic Search aims to understand the intent and contextual meaning of search phrases to produce highly relevant results. Instead of focusing solely on matching keywords, it seeks to understand the context in which keywords are used. For instance, the word “apple” could refer to the fruit or the tech company, and a semantic search system would attempt to discern which meaning was intended based on additional context.
Semantic Search often uses NLP techniques to understand context, synonyms, user intent, and more. Many semantic search systems use knowledge graphs to understand the relationships between different entities and concepts.
Because of the nature of the stored information and the capabilities offered, structured search excels in environments where data is well-organized, and the user knows precisely what they are querying for. Semantic search shines in more complex, natural language environments where user intent and context play a significant role in retrieving the right information.
Bring Structured & Semantic Search into One
The most amazing thing about text embedding generated by an LLM is it can encode any text (unstructured) into a fixed-size list of floats (vector), which can then be matched by using one of the Similarity algorithms.
The post below has a more complete explanation of text embedding.
Text Embedding — What, Why and How?
LLMs also show surprisingly strong reasoning, summarizing, and completion capability over text. Because people often don’t differentiate between structured and unstructured data when posing questions, an integrated approach that combines LLM with KG can understand natural language queries and fetch information regardless of its underlying structure, leading to a smoother and more intuitive search experience.
More importantly, integrating structured and semantic search allows for a more robust feedback mechanism. The system can learn from explicit feedback (e.g., users rating the relevance of results) and implicit feedback (e.g., tracking which results users click on most often) to refine its algorithms over time.
An Experiment Using The Movies Graph
The Movie Graph
In the following sections, I will showcase how to implement natural language Q&A on the famous Movie Graph, using ChatGPT API and Neo4j Graph Database in just a few easy steps!
For steps of creating the Movie Graph on Neo4j AuraDB, save text embeddings generated by OpenAI API. Please check my previous post:
Enhance Semantic Search of Text Embeddings through Collaborative Filtering over A Knowledge Graph
The Design
There are already many posts on generating a Cypher query from a question in natural language using GPT-3 and other similar LLMs. In this pattern, the query is generated by LLM based on examples provided, which is then executed by the underlying database to return results.
However, there are common challenges in this pattern:
- LLM can’t always generate correct labels, relationships, or property names, even if the schema is given as part of the prompt.
- LLM can’t generate complex queries if there is no sample given.
- Due to the prompt size limit, it’s not possible to provide enough samples, so LLM may not be able to learn all available syntax of the query language.
- LLM can mess up with relationship directions.
- Adding Q&A Features to Your Knowledge Graph in 3 Simple Steps
- English to Cypher with GPT-3 in Doctor.ai
- LangChain Cypher Search: Tips & Tricks
Instead of expecting LLM to generate structured queries based on unstructured questions, I will demonstrate a different approach which follows these three steps:
- Create text embeddings for nodes, relationships, and node-relationship-node patterns, which are then saved in KG. (=> 4.3)
- Create a vector index. (=>4.4)
- For a question, generate the text embedding of it, do a similarity search in KG to retrieve as many contents as possible, and let LLM generate answers from it. (=>4.5)
Embeddings Are All You Need
Node Embedding
The Movie Graph has a quite simple schema:
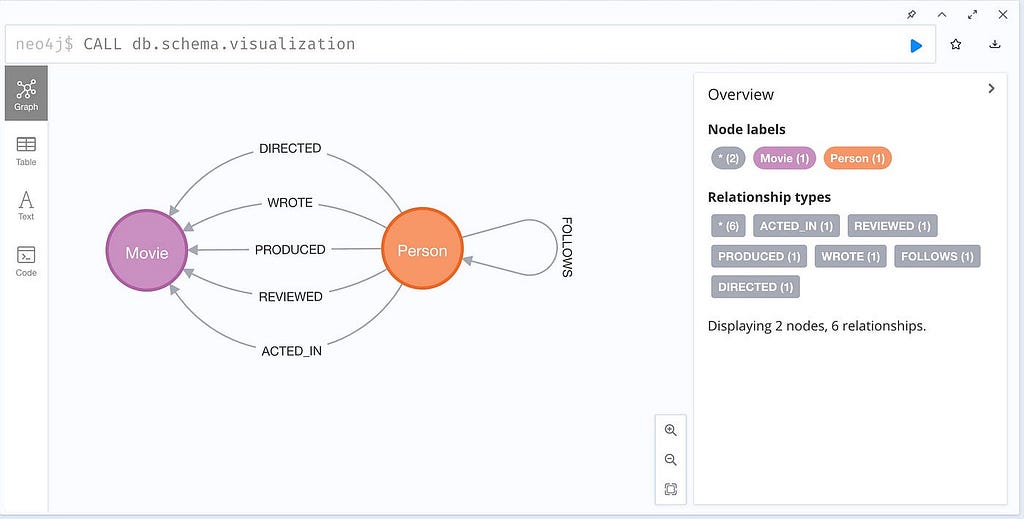
The node embedding is basically a text embedding of:
- node label
- node property
- node property value
For example, for Person node Tom Hanks, node embedding is the text embedding generated by OpenAI Embedding API of the following content:
Person name "Tom Hanks" born 1956
and Movie node Apollo 13 is generated from:
Movie title "Apollo 13" tagline "Houston, we have a problem."
Embedding of Node-Relationship-Node
This is similar to embedding triples. For an example:
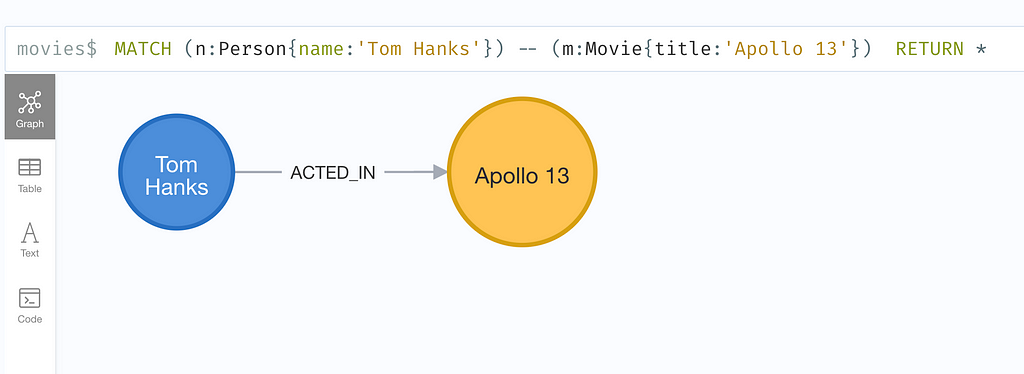
The embedding is generated for:
"Tom Hanks" ACTED_IN "Apollo 13"
Save & Index Text Embeddings in Neo4j
Embedding is represented as a vector, which is an array of float values. In Neo4j, vectors are saved as property value, and indexed through Vector Index. The link below gives more details.
For a given question, a call to OpenAI Embedding API is made to get its embedding, which is then used to retrieve similar contents in Neo4j through the vector index. The similarity is calculated using COSINE Similarity.
CALL db.index.vector.queryNodes('embeddingIndex', topK, $questionEmbedding)
YIELD node, score
RETURN node.text AS context, score;
Different from other posts, the Cypher above is the ONLY query to run, which has one parameter, i.e., the embedding of the question. There is no need to generate Cypher for a given question.
Generate Answers
When sufficient contents are retrieved from KG for the given question, another OpenAI Completion API call is made to let LLM generate an answer from the context.
The Instruction below is used for the prompt (or System Message if using Chat API from GPT-3.5/4 model):
You are an intelligent chatbot. Please answer the questions only based on the context provided below as truly as possible. If you can’t find the answer from the context, simply say, “Sorry, I don’t have enough context for your question.”.
Test Results of Sample Questions
This section lists some Q&A results over the Movie Graph.
1. Single entity: What-is
Question: Who is Kevin Bacon?
Context: (only the first 5 lines are given. Same for all following samples)
Person name “Kevin Bacon” born 1958
“Kevin Bacon” ACTED_IN “Apollo 13”
“Kevin Bacon” ACTED_IN “A Few Good Men”
“Kevin Bacon” ACTED_IN “Frost/Nixon”
Person name “Kevin Pollak” born 1957
… … … …
Answer: Kevin Bacon is an actor born in 1958.
2. Single entity: Fact-based logical reasoning
Question: is Top Gun a movie?
Context:
“Tony Scott” DIRECTED “Top Gun”
“Tom Skerritt” ACTED_IN “Top Gun”
Movie title “Top Gun” tagline “I feel the need, the need for speed.”
“Meg Ryan” ACTED_IN “Top Gun”
“Tom Cruise” ACTED_IN “Top Gun”
… … … …
Answer: Yes, “Top Gun” is a movie.
3. Single entity: Fact-based logical reasoning, negative
Question: is Tom Hanks a movie?
Context:
“Tom Hanks” ACTED_IN “Sleepless in Seattle”
“Tom Hanks” DIRECTED “That Thing You Do”
“Tom Hanks” ACTED_IN “You’ve Got Mail”
“Tom Hanks” ACTED_IN “That Thing You Do”
“Tom Hanks” ACTED_IN “Cast Away”
… … … …
Answer:
No, Tom Hanks is not a movie. Tom Hanks is an actor who has appeared in many movies.
4. Simple aggregation
Question: how many movies Kevin Bacon acted in?
Context: (note the order of results are slightly different from #1)
“Kevin Bacon” ACTED_IN “A Few Good Men”
“Kevin Bacon” ACTED_IN “Apollo 13”
“Kevin Bacon” ACTED_IN “Frost/Nixon”
Person name “Kevin Bacon” born 1958
“Kevin Pollak” ACTED_IN “A Few Good Men”
… … … …
Answer: Kevin Bacon acted in 3 movies. (Correct as per Cypher query result.)
5. Single entity + relation
Question: what movies did Tom Hanks act in?
Context:
“Tom Hanks” ACTED_IN “Sleepless in Seattle”
“Tom Hanks” ACTED_IN “A League of Their Own”
“Tom Hanks” ACTED_IN “That Thing You Do”
“Tom Hanks” ACTED_IN “You’ve Got Mail”
“Tom Hanks” ACTED_IN “Cast Away”
… … … …
Answer: Tom Hanks acted in the following movies:- Sleepless in Seattle- A League of Their Own- That Thing You Do- You’ve Got Mail- Cast Away- Charlie Wilson’s War- The Green Mile- Apollo 13- Joe Versus the Volcano- The Da Vinci Code- The Polar Express- Cloud Atlas
6. Two entities, logical reasoning
Question: Is Tom Cruise older than Tom Hanks?
Context:
Person name “Tom Hanks” born 1956
Person name “Tom Cruise” born 1962
“Tom Hanks” ACTED_IN “Apollo 13”
“Tom Hanks” ACTED_IN “Cast Away”
“Tom Hanks” ACTED_IN “Joe Versus the Volcano”
… … … …
Answer: No, Tom Hanks is older than Tom Cruise.
7. Entity-relation, out-of-scope
Question: Did Tom Cruise act in Mission Impossible 7?
Context:
“Tom Cruise” ACTED_IN “Top Gun”
“Tom Cruise” ACTED_IN “A Few Good Men”
“Tom Cruise” ACTED_IN “Jerry Maguire”
“Tom Skerritt” ACTED_IN “Top Gun”
“Tom Hanks” ACTED_IN “Apollo 13”
… … … …
Answer: Sorry, I don’t have enough context for your question.
8. Two-entity-relationship, 1-hop
Question: Did Tom Hanks and Hogo Weaving act in same movie ever?
Context:
“Tom Hanks” ACTED_IN “A League of Their Own”
“Tom Hanks” ACTED_IN “That Thing You Do”
“Tom Hanks” ACTED_IN “Sleepless in Seattle”
“Tom Hanks” ACTED_IN “Cast Away”
“Tom Hanks” ACTED_IN “Charlie Wilson’s War”
… … … …
Answer: Yes, Tom Hanks and Hugo Weaving acted in the movie “Cloud Atlas” together.
9. Single-entity, multiple-relationship, summarization
Question: tell me something about Top Gun?
Context:
“Tony Scott” DIRECTED “Top Gun”
“Tom Skerritt” ACTED_IN “Top Gun”
“Val Kilmer” ACTED_IN “Top Gun”
Movie title “Top Gun” tagline “I feel the need, the need for speed.”
“Kelly McGillis” ACTED_IN “Top Gun”
… … … …
Answer: “Top Gun” is a movie directed by Tony Scott. It stars Tom Cruise, Tom Skerritt, Val Kilmer, Kelly McGillis, Meg Ryan, and Anthony Edwards. The tagline of the movie is “I feel the need, the need for speed.”
10. Multiple-entity, multiple-relationship, summarization
Question: Recommend some movies similar to The Matrix ordered by actors or directors
Context:
“Lilly Wachowski” DIRECTED “The Matrix”
“Lilly Wachowski” DIRECTED “The Matrix Reloaded”
“Lana Wachowski” DIRECTED “The Matrix”
“Lilly Wachowski” DIRECTED “The Matrix Revolutions”
“Lana Wachowski” DIRECTED “The Matrix Revolutions”
… … … …
Answer: First 3 parts are listed here
1. Movies directed by Lana Wachowski:
— Cloud Atlas
— Speed Racer
2. Movies directed by Lilly Wachowski:
— The Matrix Reloaded
— The Matrix Revolutions
3. Movies directed by Robert Zemeckis:
— Cast Away
— The Polar Express
… … … …
11. Multiple-entity, multiple-hop, collaborative filtering, summarization
Question: The co-actors of Tom Hanks, what other movies they acted in? list actor name and movie title
Context:
“Tom Hanks” ACTED_IN “A League of Their Own”
“Tom Hanks” ACTED_IN “Sleepless in Seattle”
“Tom Hanks” ACTED_IN “That Thing You Do”
“Tom Hanks” ACTED_IN “You’ve Got Mail”
“Tom Hanks” ACTED_IN “Joe Versus the Volcano”
… … … …
Answer:
Bill Pullman — Sleepless in Seattle
Bill Paxton — A League of Their Own, Apollo 13, Twister
Steve Zahn — You’ve Got Mail
Meg Ryan — Sleepless in Seattle, You’ve Got Mail, When Harry Met Sally, Joe Versus the Volcano, Top Gun
… … … …
Further Discussions
We can continue with more Q&As, but the accuracy and relevance of the results shown so far were truly impressive to me. Some further development on it will focus on the following areas:
- More efficient and relevant context generation.
- The intelligence of deciding whether a question should be answered by text-based context or structured query execution.
- Leveraging metadata or domain knowledge (e.g., ontology) of the dataset to improve the efficiency.
- A fine-tuned model with domain-specific data.
When both structured knowledge and its semantics are stored in the Neo4j graph database, it is very achievable to combine semantic match with structured traversal over the graph to provide further processing of the results, which makes this approach huge potential to be further explored.
To conclude, I’d like to quote some words from this amazing paper by Luna Dong:
The future (of KG): With the above analysis, we envision a KG that encodes knowledge both in the form of knowledge triples and in the form of LLM embeddings, where the former are easier to use for human understanding and explainability, whereas the latter is easier for machine comprehension.
Look forward to what’s next!
The Future of Knowledge Graph: Will Structured and Semantic Search Become One? was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles
Streamline Data Ingestion With the Neo4j Aura Import API



Find Similar Patient Journeys With Neo4j Aura Graph Analytics