


Using LlamaParse to Create Knowledge Graphs from Documents

Field Engineer, Neo4j
7 min read

Combining the power of LlamaParse and Neo4j for better RAG applications.
- Building A Graph+LLM Powered RAG Application from PDF Documents
- Integrating unstructured.io with Neo4j AuraDB to Build Document Knowledge Graph
- The Developer’s Guide: How to Build a Knowledge Graph
The Process
Building a document processing pipeline with LlamaParse and Neo4j can be defined as the following steps: 1. Setting Up the Environment: Step-by-step instructions on setting up your Python environment, including the installation of necessary libraries and tools such as LlamaParse and the Neo4j database driver. 2. PDF Document Processing: Demonstrates how to use LlamaParse to read PDF documents, extract relevant information (such as text, tables, and images), and transform this information into a structured format suitable for database insertion. 3. The Graph Model for Document: Guidance on designing an effective graph model that represents the relationships and entities extracted from your PDF documents, ensuring optimal structure for querying and analysis. 4. Storing Extracted Data in Neo4j: Detailed code examples showing how to connect to a Neo4j database from Python, create nodes and relationships based on the extracted data, and execute Cypher queries to populate the database. 5. Generating and Storing Text Embeddings: Using a program created in the past to generate text embedding via OpenAI API call and store embedding as a vector in Neo4j. 6. Querying and Analyzing Data: Examples of Cypher queries to retrieve and analyze the stored data, and illustrate how Neo4j can uncover insights and relationships hidden within your PDF content. The complete tutorial notebook can be found here.Graph Model for Parsed Document
Regardless of which PDF parsing tool to use to save results into Neo4j as a knowledge graph, the graph schema is, in fact, quite simple and consistent.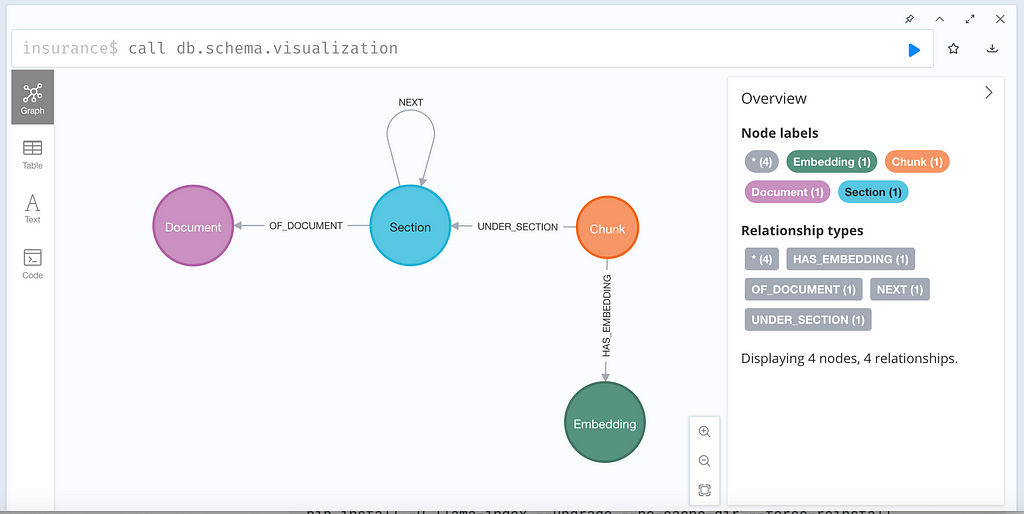
Parsing PDF Document
Using brand new LlamaParse PDF reader for PDF Parsing comprises two easy steps:- Using raw Markdown text as nodes for building index and applying simple query engine for generating the results;
- Using MarkdownElementNodeParser for parsing the LlamaParse output Markdown results and building a recursive retriever query engine for generation.Storing Extracted Content in Neo4j
from llama_parse import LlamaParse from llama_index.core.node_parser import MarkdownElementNodeParser pdf_file_name = './insurance.pdf' documents = LlamaParse(result_type="markdown").load_data(pdf_file_name) # Parse the documents using MarkdownElementNodeParser node_parser = MarkdownElementNodeParser(llm=llm, num_workers=8) # Retrieve nodes (text) and objects (table) nodes = node_parser.get_nodes_from_documents(documents) base_nodes, objects = node_parser.get_nodes_and_objects(nodes)
Querying Document Graph
This is what a document looks like after it is ingested into Neo4j: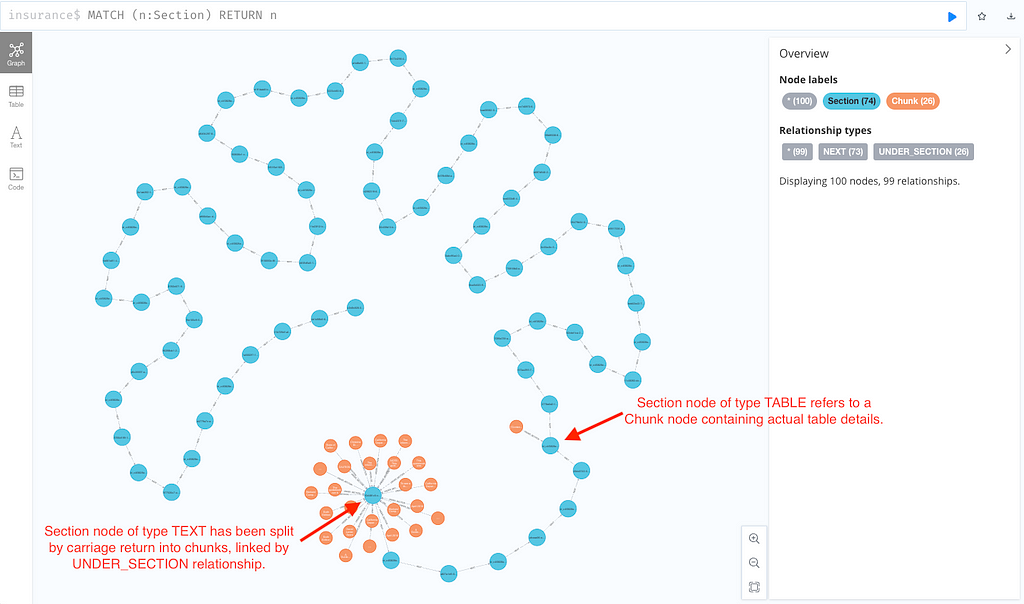
Conclusions
LlamaParse stands out as a highly capable tool for parsing PDF documents, adept at navigating the complexities of both structured and unstructured data with remarkable efficiency. Its advanced algorithms and intuitive API facilitate the seamless extraction of text, tables, images, and metadata from PDFs, transforming what is often a challenging task into a streamlined process. Storing the extracted data as a graph in Neo4j further amplifies the benefits. By representing data entities and their relationships in a graph database, users can uncover patterns and connections that would be difficult, if not impossible, to detect using traditional relational databases. Neo4j’s graph model offers a natural and intuitive way to visualize complex relationships, enhancing the ability to conduct sophisticated analyses and derive actionable insights. A consistent document knowledge graph schema makes it much easier to integrate with other tools for downstream tasks, e.g., to build Retrieval Augmented Generation using GenAI Stack (LangChain and Streamlit). The combination of LlamaParse’s extraction capabilities and Neo4j’s graph-based storage and analysis opens up new possibilities for data-driven decision-making. It allows for a more nuanced understanding of data relationships, efficient data querying, and the ability to scale with the growing size and complexity of datasets. This synergy not only accelerates the extraction and analysis processes but also contributes to a more informed and strategic approach to data management. The complete tutorial notebook can be found here.
Thinking about building a knowledge graph?
Download The Developer’s Guide: How to Build a Knowledge Graph for a step-by-step walkthrough of everything you need to know to start building with confidence.
Download the Guide
Share Article


Explore
Related Articles


A Practical Experimentation of GraphRAG and Agentic Architecture With NeoConverse
13 min read
Graphiti: Knowledge Graph Memory for a Post-RAG Agentic World
5 min read
