



Welcome to the first in a series of blogs on some of the exciting new features in Neo4j 4.3 that was released last week at NODES 2021.
Over the coming weeks, I will be publishing technical blogs on the following new features:
- Relationship/Relationship Property Indexes (this blog)
- Relationship Chain Locks
- Deploying on Kubernetes with Helm Charts
- Server Side Routing
- Read Scaling for Analytics
Each blog will provide an introduction into the feature, when to use it, and a worked example.
Finally, a big thanks to Michael Hunger for his help in putting the example in this blog together.
What Are Relationship / Property Indexes, and When Do You Use Them?
The new index types in Neo4j 4.3 work in much the same way as Node and Node Property indexes do — they enable you to quickly look up where there are references to a particular Relationship Type in the graph (i.e. which Nodes are connected by the relationship). Or in the case of Relationship Property Indexes, which Relationship Types have those properties . You can specify a combination of properties too — known as a compound index — for example, indexing on properties since and from would only index relationships with both of these properties defined
Creating a Relationship and /or Relationship Property Index will enable you to run more complex queries on relationships in less time. The indexes help reduce scanning across the entire database, which translates into fewer hits on the database. This won’t just benefit your queries, but anyone else using Neo4j at the same time. And in turn, reducing the hits on the database means you reduce the demands on the storage IO — something your storage team will certainly thank you for.
Side Note on the Use of Indexes
Adding Indexes does need to be done with some thought because they increase the write workload — creates and updates on the index when new data is written to the database. Indexes may not benefit your queries when the majority of nodes have the same relationship type or there is only a single relationship type — same goes for relationship properties.
How will I know the Index is helping? We’ll explain later, but Neo4j has a handy way of showing you its plan for running the query, and this includes the use of the indexes. Neo4j’s schema-less architecture means that you don’t have to figure this all out upfront, and Indexes can always be added to improve performance. Note, Neo4j will create a LOOKUP Relationship type index by default, and you can drop it with the DROP INDEX command if it isn’t required.
OK, That’s Great! Give Me an Example?
I am going to use the same query that I presented in the announcement for Neo4j 4.3 at NODES — where we imagined we were exploring the Panama Papers to find occurrences of the same two officers involved in the same off-shore companies. We aren’t expecting to find just one or two companies or one or two directors, since the scale of the scandal suggests that many of the same individuals were involved in hundreds of bogus companies.
To set this up, Michael Hunger and I used his commands to import the panama data here. We made a few minor changes (described below) to preserve the officer role as a relationship type (we could have chosen to create different types of relationships as well).
New code used in this example
neo4j@neo4j> USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM “file:///all_edges.csv” AS row
WITH row WHERE row.rel_type IN [“officer of”,”director of”,”shareholder Of”, “beneficiary of”, “secretary of”]
MATCH (n1:Node) WHERE n1.node_id = row.node_1
MATCH (n2:Node) WHERE n2.node_id = row.node_2
CREATE (n1)-[r:OFFICER_OF]->(n2) SET r.role = row.rel_type;
Replaced the code used in Michael’s original script because he created a single relationship type OFFICER_OF for all the directors, shareholders, beneficiaries, etc.
neo4j@neo4j> USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM “file:///all_edges.csv” AS row
WITH row WHERE row.rel_type = “officer_of”
MATCH (n1:Node) WHERE n1.node_id = row.node_1
MATCH (n2:Node) WHERE n2.node_id = row.node_2
CREATE (n1)-[:OFFICER_OF]->(n2);
The Query
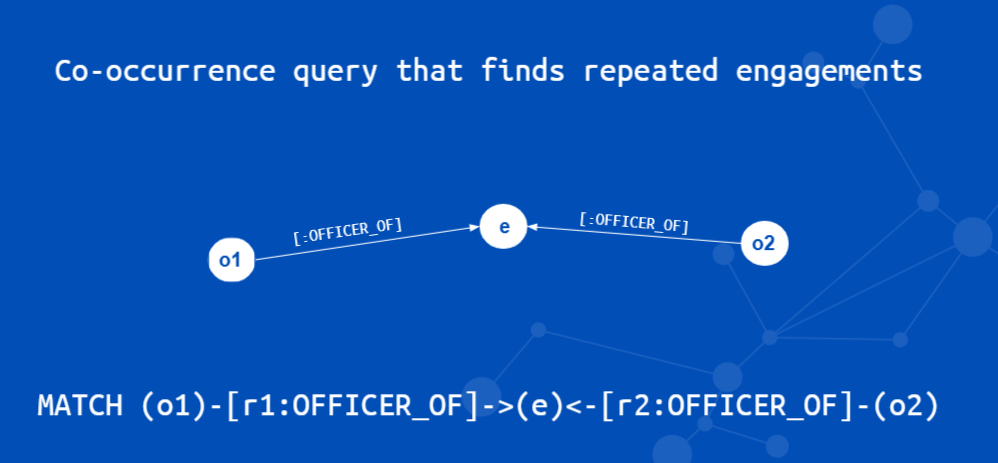
To find pairs of directors who are involved in multiple shell companies we need what is termed a “co-occurrence query.” This type of deep query is something that is only really practical to perform in a graph database, because you are examining every legal business entity in the graph to see if there are relationships with the same pairs of individuals.
neo4j@neo4j> MATCH (o1)-[r:OFFICER_OF]->(e)<-[OFFICER_OF]-(o2)
WHERE id(o1) > id(o2)
AND r.role CONTAINS “director”
WITH o1, o2, count(*) as c order by c desc limit 100
RETURN o1.name, o2.name, c
Co-occurrence queries can be used in lots of other settings too, for example social media posts — do the same two people comment on the same social media posts — may find that Dwayne ‘The Rock’ Johnson and Kevin Hart do, which may imply that they are good friends.
Query Results
If you scroll through the results you find that some of the directors are involved in anywhere from 60 to 90+ companies, while others are only involved in a couple. It is not unreasonable to expect people to be involved in a couple of companies legitimately, but 60+ is a definite red flag for suspicious activity.
How Do You Create the Index on the Role?
Creating the index is straightforward. Run the following in the cypher-shell:
neo4j@neo4j> CREATE INDEX officerRelationshipProperty
FOR ()-[r:OFFICER_OF]-()
ON (r.role);
Check out the docs for the full syntax.
How do we SHOW that Neo4j runs 3.4 times faster with the new index?
Neo4j provides two commands to help you figure out what is going on under the hood: EXPLAIN and PROFILE. EXPLAIN will figure out the execution plan, but won’t actually run the query so won’t return any results. PROFILE on the other hand will run the query, consume the resources, and return the results. By running the query with EXPLAIN or PROFILE before we create the index, we can compare the results we get after creating the index.
neo4j@neo4j> PROFILE MATCH (o1)-[r:OFFICER_OF]->(e)<-[OFFICER_OF]-(o2)
WHERE id(o1) > id(o2)
AND r.role CONTAINS “director”
WITH o1, o2, count(*) as c order by c desc limit 5
RETURN o1.name, o2.name, c
When the command runs, it will produce the results and explain the plan used. Below on the left you have the execution without the index, and on the right the plan with the index which references the DirectedRelationshipContainsIndex signaling that the Relationship Property Index was used.
Without the index
Cypher version: CYPHER 4.3 planner: COST, runtime: INTERPRETED*. 4065736 total db hits in 2571 ms

With the index
Cypher version: CYPHER 4.3, planner: COST, runtime: INTERPRETED*. 999737 total db hits in 744 ms.

*I am using Community Edition which is why the INTERPRETED runtime is used, if you are running Enterprise Edition it will use the new faster PIPELINED runtime.
Now That You Mention It, How Much Faster Is PIPELINED?
By switching to Enterprise Edition, Neo4j will automatically use the PIPELINED runtime. The PIPELINED runtime uses algorithms to group the operators in the execution plan in order to optimize performance and memory usage. In doing so, it is able to execute the same query with the Index in 507 ms, which is 1.5x faster than INTERPRETED .
Enterprise without Index: CYPHER 4.3, planner: COST, runtime: PIPELINED. 4952883 total db hits in 1847 ms
Enterprise with Index: CYPHER 4.3, planner: COST, runtime: PIPELINED. 1228764 total db hits in 507 ms
Please note these results are provided for illustrative purposes only. They were all run on a 1GB Docker instance.
It is also worth giving a quick shout-out to another handy feature in Neo4j 4.3 — EXPLAIN plan logging, covered in the next section, which can help you troubleshoot use of indexes in queries..
Troubleshooting with EXPLAIN Plan Logging
Every time a CYPHER query is run, it generates and uses a plan for the execution of the code. The plan generated can be affected by changes in the database (such as a new index being added). It is not possible to see which plan was used. If you need to see what is happening at the query plan execution level, you may want to enable the new logging feature.
The new configuration setting helps DBAs troubleshoot queries and confirm which plan was used when the query plan was generated and record it in the log.
Name: dbms.logs.query.plan_description_enabled
Datatype:boolean, default value = false
Dynamic: true
NOTE: Enabling this option will impact the performance of the database, because of the cost of preparing and including the plan, Neo4j does NOT recommend leaving this set to true.
Stay Tuned
That’s all for this week on Relationship / Property Indexes. Look out for the next blog in the series — Relationship Chain Locks where you can find out how not to block, when you update the Rock!
Neo4j 4.3 Blog Series: Relationship Indexes was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





