


Neo4j Driver Best Practices

Senior Director of Developer Relations, Neo4j
7 min read
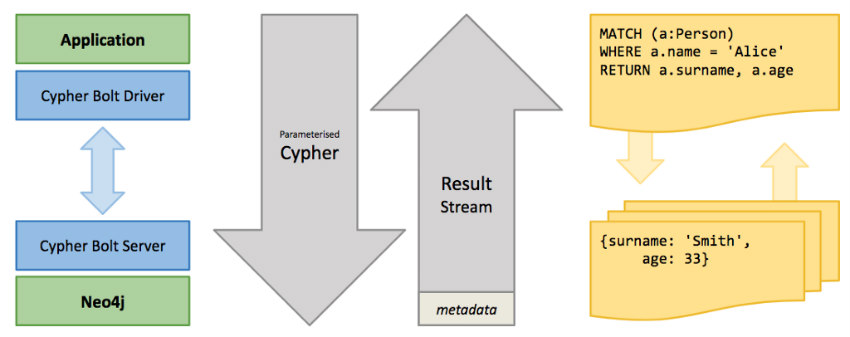
Neo4j & Neo4j Aura support Python, JavaScript, Java, Go, and .NET. Additionally, community support is available for other languages such as PHP and Ruby. In this article, we’ll cover some best practices for using Neo4j drivers in your application. The code examples will all be in Python for simplicity, but the basic practices outlined apply to all languages supported by Neo4j.
We will go from the simplest, to the more complex as the article goes on.
Connect Using the neo4j+s:// scheme Whenever Possible
For newer Neo4j versions after 4.0, neo4j+s:// is usually your best bet. It works with secured single instance databases, and also with clusters. The +s means that certificate validation will be performed, and that your connection will be secure.
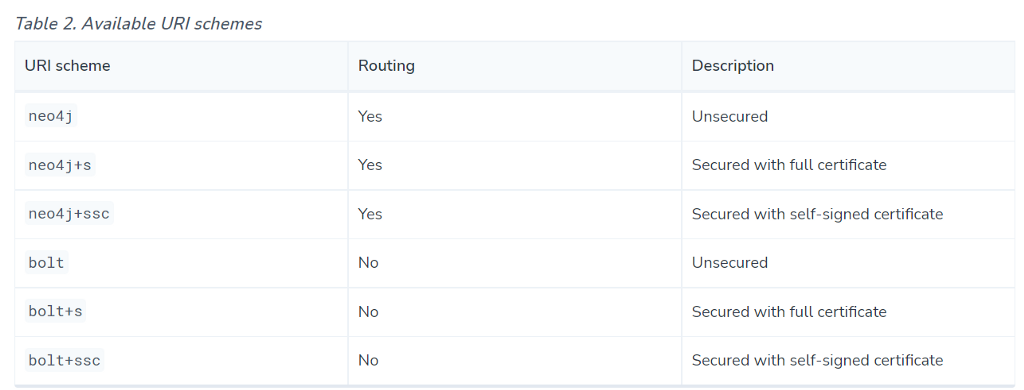
The bolt:// connection scheme connects to only one machine, and will usually not work like you expect when connecting to Neo4j Aura or any other clustered setup.
Use Very Recent Versions of Neo4j Drivers
Particularly for Neo4j Aura environments, Neo4j has been making big improvements in query performance and speed. If you have an older driver, make sure to upgrade it for best connectivity, at least to the 4.4 series of drivers.
At the time of writing: If you are using Java or JavaScript, make sure to use driver ≥ 4.3.6. For Python & Go, use at least ≥ 4.3.4; for .NET ≥ 4.4.0. These releases include a “server hints” feature that sends server keep-alive messages and keeps connections open and error free in a wider variety of network situations.
Verify Connectivity Before Issuing Queries
As soon as you create a driver instance, you should verify connectivity, like this:
from neo4j import GraphDatabase
uri = "neo4j+s://my-aura-instance.databases.neo4j.io"
driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))
driver.verify_connectivity()
Normally, the Neo4j driver creates connections as needed and manages them in a pool; by verifying connectivity at the very beginning, it forces the driver to create a connection at that moment. If the address, username, or password is wrong, it will fail immediately, and this is useful. Beginners will sometimes report errors in code that’s running a Cypher query, when in fact the error was that the connection wasn’t established until the cypher query was run, and it is in fact a connection error.
Create One Driver Instance Once and Hold Onto It
Driver objects in Neo4j contain connection pools, and they are typically expensive to create; it may take up to a few seconds to establish all of the necessary connections and establish connectivity. As a result, your application should only create one driver instance per Neo4j DBMS, and hold on to that and use it for everything.
This is very important in environments like AWS Lambda and other types of serverless cloud functions, where, if you create a driver instance every time your code runs, it will incur a performance penalty.
In some environments (like AWS Lambda), you may also want to look into changing connectivity settings to reduce the number of connections created, to reduce cold startup time. Drivers are generally heavyweight objects that expect to be reused many times.
Sessions, on the other hand, are cheap. Create and close as many of them as you like.
Use Explicit Transaction Functions
The simplest API is sometimes not the best. Here is a common mistake people make that sometimes bites them later. You can do this with Neo4j drivers, which creates what’s called an “Auto-commit Transaction”
with driver.session as session:
session.run("CREATE (p:Person { name: $name})", name="David")
The trouble with this is that Neo4j drivers don’t parse your Cypher, and because Neo4j clusters uses routed drivers, typically this kind of setup will always send all of your queries (both reads and writes) to the leader of your cluster. Effectively, you won’t be using 2/3rds of your 3-member cluster because all queries are going to the same machine.
Another thing that’s less good about using session.run and Auto-commit transactions is that you lose control over the commit behavior. Sometimes you need to run multiple cypher queries which all commit at once or all fail (rather than committing one by one individually).
You can not do that with autocommit.
The better practice is to use an “explicit transaction function”, like this:
def add_person(self, name):
with driver.session() as session:
session.write_transaction(self.create_person_node, name)
def create_person_node(tx, name):
return tx.run("CREATE (a:Person {name: $name})", name=name)
Two things to notice here:
- The Cypher “work” was encapsulated in
create_person_node - We called
session.write_transactionwhich tells the driver that it’s a transaction containing write operations. When we usesession.read_transactionfor reads, the driver can spread the work out among cluster members.
Use Query Parameters Wherever Possible
In the previous example, we used a query parameter called $name to pass a variable into a Cypher query:
def add_person(self, name):
with driver.session() as session:
session.write_transaction(self.create_person_node, name)
def create_person_node(tx, name):
tx.run("CREATE (a:Person {name: $name})", name=name)
You should use these parameters wherever you’re substituting data into your queries, and never use string concatenation. For example, the following is poor practice:
def create_person_node(tx, name):
tx.run("CREATE (a:Person {name: '%s'})" % name)
Use of query parameters gives several advantages:
- Safer code protects against security flaws like Cypher Injection Attacks
- It shows the database fewer query forms, allowing the database to compile fewer queries and make them run faster, rather than every new query being a new string the database hasn’t seen before.
Process Database Results Within Your Transaction Function
Let’s take a look at the following bit of code, and in particular the bold portion. We’re running a transaction to get Alice’s friends. Notice how instead of returning the Neo4j result object, the code is processing each record in the result into a new data structure called friends and returning that.
from neo4j import GraphDatabase
uri = "neo4j://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))
def get_friends_of(tx, name):
friends = []
result = tx.run("""
MATCH (a:Person)-[:KNOWS]->(f)
WHERE a.name = $name
RETURN f.name AS friend
""", name=name)
for record in result:
friends.append(record["friend"])
return friends
with driver.session() as session:
friends = session.read_transaction(get_friends_of, "Alice")
for friend in friends:
print(friend)
driver.close()
In Neo4j drivers, generally the result that comes back from a transaction function isn’t available outside of the scope of the transaction function. So this code would fail:
def get_friends_of(tx, name):
friends = []
result = tx.run("MATCH (a:Person)-[:KNOWS]->(f) "
"WHERE a.name = $name "
"RETURN f.name AS friend", name=name)
return result
with driver.session() as session:
results = session.read_transaction(get_friends_of, "Alice")
for record in result:
print(record["friend"])
The reason that it would fail is that the database cursor which fetches the results isn’t available outside of the scope of the transaction function get_results_of.
Understand Bookmarking and Causal Consistency If You See Inconsistent Reads
Neo4j drivers have a concept called bookmarks that allow you to read your own writes. Suppose you did two queries in a sequence:
- CREATE (p:Person { name: ‘David’ })
- MATCH (p:Person) WHERE name = ‘David’ RETURN count(p)
You’ll expect to get the answer of 1 from the second query. But let’s think through how this actually happens in a real cluster:
- The first query succeeds when a majority of cluster members have acknowledged the writes. In an AuraDB instance, that might be 2 of the 3 cluster members have your write
- If the second query happens (by chance) to be routed to the third member (that doesn’t have the write yet) it could return the answer 0 because the writes haven’t caught up yet!
Fortunately there’s an easy fix for this. If you use the same session object to do the read as you did for the write, it will always work as you expect. This is because the server returns a bookmark as of the write. The session object uses “bookmark chaining” and all subsequent reads are done as of that bookmark in the database.
Let’s distill this into super-simple best practices:
- If you are doing a sequence of operations and you need the later operations to be guaranteed to read the writes from earlier operations, simply reuse the same
sessionobject, and all of this is automatically taken care of for you, because sessions chain the bookmarks they receive from each query. - If you need to coordinate multiple different programs (and program B needs to read program A’s writes) then program A must pass its write bookmark to the other program’s session, so that B can read the database’s state as at least of that bookmark to guarantee consistency to that moment in time.
Most of the time you won’t need to access or worry about bookmarks, but they’re easy to access:
my_bookmark = None
with driver.session() as session:
results = session.write_transaction(write_bunch_of_people)
my_bookmark = session.last_bookmark()
with driver.session(bookmarks=[my_bookmark]) as session2:
# Do some reads guaranteed to include writes which
# happened above.
For more information on why Neo4j works this way, read into Causal Consistency.
Summary
If you use these practices, your graph code will be safer, more secure, more performant, and also more portable between graph environments, whether you’re running on a Neo4j Desktop install, an AuraDB Free database, or scaling all the way up to large AuraDB Enterprise clusters.
Neo4j Driver Best Practices was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles

Transform Static Risk Assessment Into a Dynamic Data-Driven Strategy
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI

Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces
