




Introduction
If you’ve explored using Neo4j for GraphRAG, you already know its potential to enhance the output quality of generative models. Traditionally, this required deep knowledge of Neo4j and Cypher. In this post, we introduce the official Neo4j GraphRAG Python package (neo4j-graphrag), designed to simplify the integration of Neo4j into Retrieval-Augmented Generation (RAG) applications for developers.
Our GraphRAG Python package equips you with the tools to efficiently manage retrieval and generation processes in a RAG setup. By the end of this post, you will be proficient in executing retrieval tasks using our package. In an upcoming post, you will learn more about the generation capabilities of the package, allowing you to build out a full end-to-end RAG pipeline.
What Is GraphRAG?
The neo4j-graphrag package facilitates graph Retrieval-Augmented Generation (GraphRAG). At Neo4j, we believe that integrating graph databases with vector search represents the next frontier for RAG.
Setup
Start by connecting to a pre-configured Neo4j demo database that simulates a movie recommendations knowledge graph. Access it at https://demo.neo4jlabs.com:7473/browser/ using “recommendations” as both the username and password. This setup provides a realistic scenario where your vector embedding data is already part of a Neo4j database ready to be used.
Visualize the data by entering the Cypher command:
MATCH (n) RETURN n LIMIT 25;
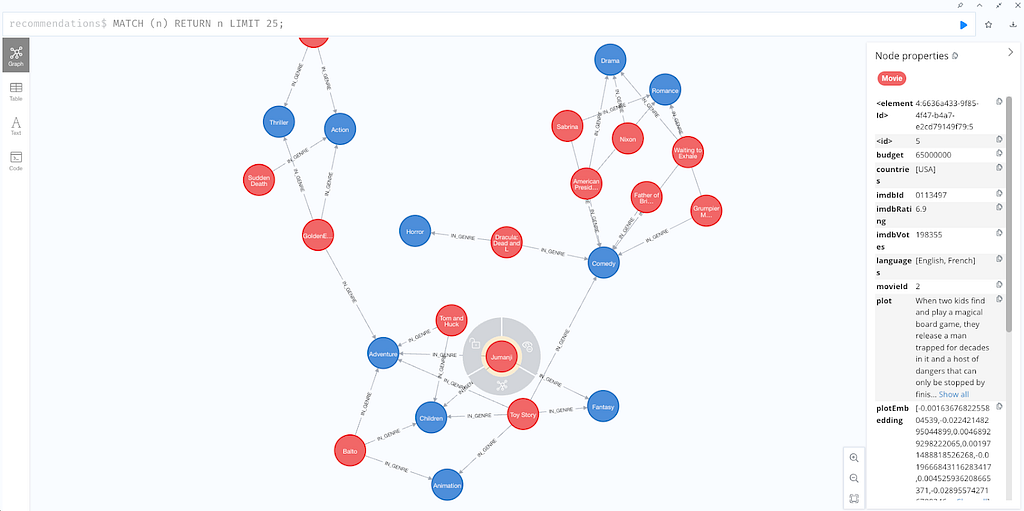
Observe the plotEmbedding attribute in each node’s details on the right. We’ll use these embeddings to conduct vector searches throughout our demonstrations. You can check that there exists a moviePlotsEmbedding vector index by entering the Cypher command:
SHOW INDEXES YIELD * WHERE type='VECTOR';
In your Python environment, install the neo4j-graphrag package along with these other packages:
pip install neo4j-graphrag neo4j openai
Proceed by establishing a connection to your Neo4j database using the Neo4j Python driver:
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
For this demonstration, ensure that you have an OpenAI API key set:
import os os.environ["OPENAI_API_KEY"] = "sk-…"
Retrieval
Our package provides a variety of retrievers, tailored for different retrieval strategies (see our documentation for the full list). Selecting the appropriate one depends on your specific needs. Here, we employ the VectorRetriever class:
from neo4j-graphrag.retrievers import VectorRetriever
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title", "plot"],
)
We use the text-embedding-ada-002 model because the movie plot embeddings in the demo database were generated using this model, thus enabling a more relevant retrieval search. There are ways to customize the returned result. Here we specify return_properties to have the node properties title and plot returned.
Use the retriever to search for movie plots closely aligned with your query, which executes an approximate nearest-neighbor search to identify the top three movie plots that best match your query:
query_text = "A movie about the famous sinking of the Titanic"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
items=[
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'An unhappy married couple deal with their problems on board the ill-fated ship.'}""",
metadata={'score': 0.9450652599334717, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Night to Remember, A',
'plot': 'An account of the ill-fated maiden voyage of RMS Titanic in 1912.'}""",
metadata={'score': 0.9428615570068359, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.'}""",
metadata={'score': 0.9422949552536011, 'nodeLabels': None, 'id': None})]
metadata={'__retriever': 'VectorRetriever'}
We can further parse retriever_result using regular expressions:
import re
for k, item in enumerate(retriever_result.items):
plot = re.search(r"'plot':s*'([^']*)'", item.content).group(1)
title = re.search(r"'title':s*'([^']*)'", item.content).group(1)
score = item.metadata["score"]
print(f"Result {k}: {title} - {score} - {plot}")
Result 0: Titanic - 0.9450652599334717 - An unhappy married couple deal with their problems on board the ill-fated ship.
Result 1: Night to Remember, A - 0.9428615570068359 - An account of the ill-fated maiden voyage of RMS Titanic in 1912.
Result 2: Titanic - 0.9422949552536011 - A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.
GraphRAG
Let’s see how the retriever fits into a simple GraphRAG pipeline. To perform a GraphRAG query using the neo4j-graphrag package, a few components are needed:
- A Neo4j driver — Used to query your Neo4j database.
- A retriever — The neo4j-graphrag package provides some implementations and lets you write your own if none of the provided implementations matches your needs.
- An LLM — We need to call an LLM to generate the answer. The neo4j-graphrag package currently only provides an implementation for the OpenAI LLMs, but its interface is compatible with LangChain chat models and lets you write your own interface if needed.
In practice, it’s done with only a few lines of code:
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "What movies are sad romances?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 5})
print(response.answer)
We will see in an upcoming post how we can customize different types of retrievers.
Summary
We’ve demonstrated using the VectorRetriever class from the neo4j-graphrag package to execute a straightforward retrieval query. Future posts will explore other retrieval strategies and how you can use different LLMs in your GraphRAG pipelines using this package. Stay tuned!
We invite you to integrate the neo4j-graphrag package into your projects and share your insights via comments or on our GraphRAG Discord channel.
The package code is open source, and you can find it on GitHub. Feel free to open issues there.
Getting Started With the Neo4j GraphRAG Python Package was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles

Enhancing Hybrid Retrieval With Graph Traversal Using the GraphRAG Python Package
