


Easy Data Ingestion With Neo4j Runway and arrows.app

Consulting Engineer, Neo4j
6 min read

Automatically write ingestion code for your Neo4j graph.

Neo4j Runway is a Python library I developed with the help of Jason Booth and Dan Bukowski at Neo4j. It provides tools that abstract communication with OpenAI to run discovery on your data and generate a data model, as well as tools to generate ingestion code and load your data into a Neo4j instance. The goal is to simplify the user experience of understanding how their relational data can fit into a graph data model and get them exploring quickly.
We’ll walk through Runway’s integration with Neo4j’s data modeling application arrows.app using the code generation and data ingestion modules. If you are unfamiliar with arrows.app, read more about it here. To read more about Neo4j Runway, check out this article covering each key module.
To install, simply run this pip command:
pip install neo4j-runway
The information in this article pertains to Neo4j Runway v0.2.2
Key Features
- Data discovery: Harness OpenAI LLMs to provide valuable insights from your data.
- Graph data modeling: Use OpenAI and the Instructor Python library to create valid graph data models.
- Code generation: Generate ingestion code for your preferred method of loading data.
- Data ingestion: Load your data using Runway’s built-in implementation of pyingest — a Neo4j Python ingestion tool.
The notebook we’ll use as a guide is in this repo of examples using the Neo4j Runway library: arrows.ipynb.
Requirements
Runway uses Graphviz to visualize data models. To use this feature, download Graphviz. This install is necessary to run the Graphviz Python package.
You’ll need a Neo4j instance to use Runway fully. Start a free cloud-hosted Aura instance or download the Neo4j Desktop app.
Runway’s code generation and data ingestion features do not require an LLM.
Runway is still in beta. Feel free to provide feedback and report any bugs.
arrows.app
The arrows.app is a web-based tool for drawing pictures of graphs. It’s commonly used to create data models and allows users to export their graphs in many formats, including PNG and JSON.
Here, we will use some dummy data about fictional people and their pets. The following is the graph data model I created in arrows.app.
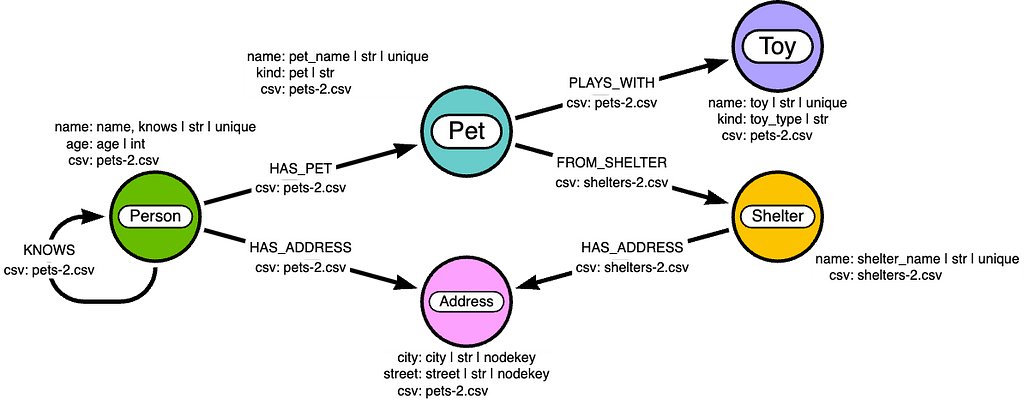
Here, we have a data model about people and their pets. We can see that a Person has a Pet, a Pet is from a Shelter, and so on. Notice that we also have properties, but they have specific formatting so we can track the important features when we import them into Runway. To maintain property features, we must format them like so:
<propertyName>: <csv_mapping> | <Python type> | <unique> or <nodekey>
Here we have propertyName as a key and a pipe-separate list of property features as the value:
- propertyName: The property name that will be stored in Neo4j
- csv_mapping: The CSV column name that maps to the property name
- Python type: The Python type of the property (If a Neo4j type is provided, this should automatically be converted on import)
- unique: Indicates whether the property is a unique identifier (optional)
- nodekey: Whether the property is a part of a node key (optional)
Identifying a property as unique will create a uniqueness constraint and index. Identifying a property as nodekey will create a node key constraint and index on that node, including all marked properties.
Sometimes there are CSV columns that refer to the same property. In this case, a Person node has the property name. This name property is mapped to the CSV columns name and knows, where knows identifies another Person that is related via a KNOWS relationship. We can notate this with a comma-separated list where the first column mapping is the source, and the second column mapping is the target node. So in this example, it will look like this:
(Person {name: csv.name})-[:KNOWS]->(:Person {name: csv.knows})We can also identify which CSV the node or relationship is found. This is stored as a property field like so:
csv: <csv name>
If all data is from a single CSV, we can exclude this entry and identify the single CSV name when generating the ingestion code later.
To download our data model, we can select: Download / Export tab → JSON tab → Download tab.
Runway
Now, we import the data model into Runway and generate some ingestion code:
from neo4j_runway import DataModel
model = DataModel.from_arrows(file_path="data/model/pet-model-0.2.0.json")
If we have Graphviz installed, we can visually verify that our model was imported correctly:
model.visualize()
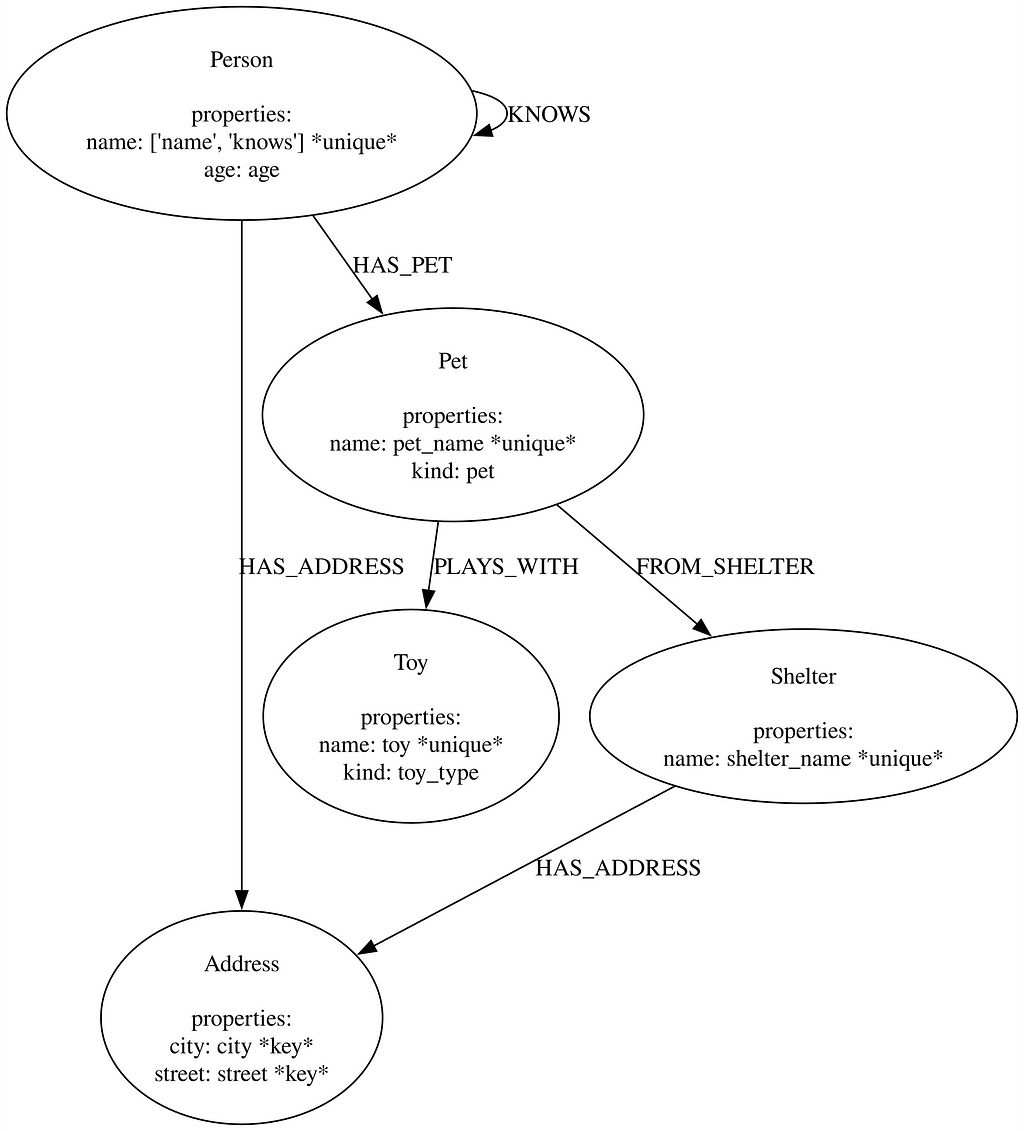
Now that we have confirmed our model is accurate, we can generate some code. We’re going to use the LOAD CSV method to ingest our data. This built-in Cypher command allows you to point to a CSV file location and run your ingestion code. In this example, we locally store the CSV file in the import/ directory of our Neo4j instance. If you’re using an Aura instance of Neo4j, you won’t be able to store a CSV locally, but you can still use the LOAD CSV method and point to an s3 bucket or other storage location:
from neo4j_runway import IngestionGenerator
gen = IngestionGenerator(data_model=model, csv_dir="./")
We don’t include a csv_name argument in the IngestionGenerator since we identify the appropriate CSVs in the data model.
When generating the LOAD CSV code, we indicate the method as “browser” since we’ll copy and paste the code into a Neo4j browser cell. If you plan on using the code with one of the Neo4j drivers or an API, you can indicate the method as “api” or leave the field blank.
The difference here is appending “:auto” to the beginning of the LOAD CSV Cypher query to set the transaction to implicit mode. This is necessary when loading via the browser because we use the query type CALL { … } IN TRANSACTIONS, which initiates separate transactions within the query.
To run LOAD CSV queries from a Neo4j driver, you must run in implicit mode using the method:
Session.run(<query>)
Find more information about implicit transactions in the Neo4j Python Driver Manual 5.
The following method will generate our LOAD CSV code to copy and paste into a Neo4j browser cell:
load_csv_cypher = gen.generate_load_csv_string(method=”browser”)
Or we can save this to a file:
gen.generate_load_csv_file(file_name="pets_load_csv", method="browser")
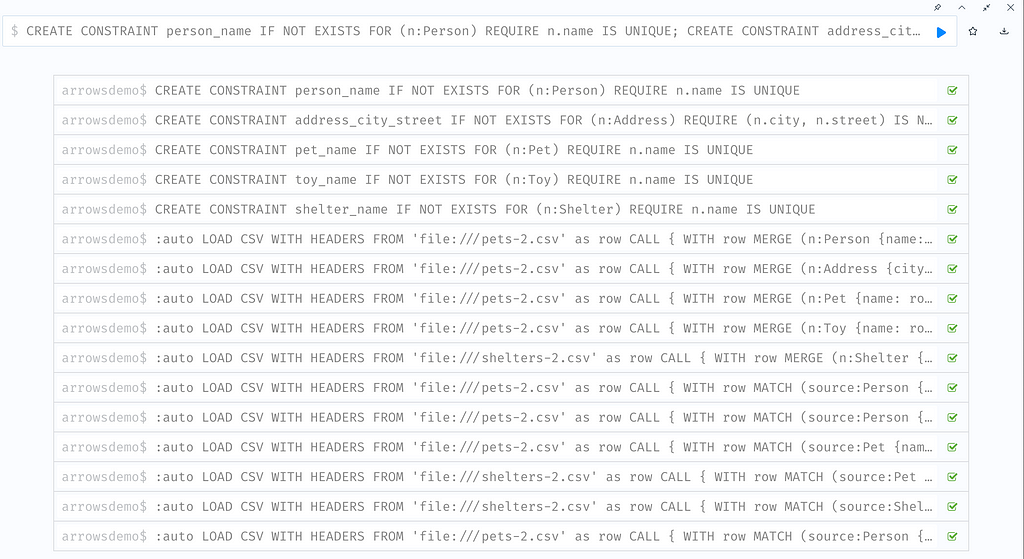
We then copy and paste the full code into a browser cell of our Neo4j instance and hit run. If all queries run successfully, you should see something like this:
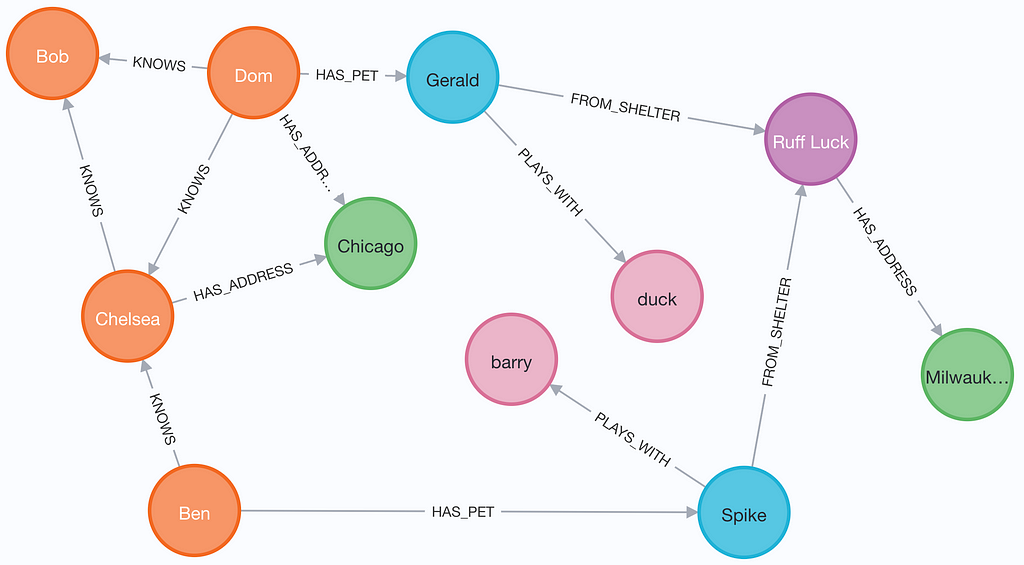
Here’s a snapshot of the generated graph:
Conclusion
We’ve explored how you can generate ingestion code for your arrows.app data model using the Neo4j Runway Python library. To read more about Neo4j Runway, check out this article covering each key module.
Please remember that Runway is still in beta. Feel free to provide feedback and report any bugs.
Easy Data Ingestion With Neo4j Runway and arrows.app was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles


Everything a Developer Needs to Know About the Model Context Protocol (MCP)
25 min read

A Practical Experimentation of GraphRAG and Agentic Architecture With NeoConverse
13 min read
Graphiti: Knowledge Graph Memory for a Post-RAG Agentic World
5 min read