





Who among us remembers how hard it was to learn to drive? If you haven’t learned to drive yet, or don’t intend to learn, how hard do you think it would be?
Pretty daunting, as I remember (confession: it took me three attempts to pass my test — gulp).
Then there’s the question of what you learn to drive. In the United States, most vehicles have automatic transmissions, so it makes sense to learn that mode. In Europe and many other places, however, manual transmission is the norm, so many decide they might as well take on the greater burden of learning clutch control and gear changing.
Many vehicles at the high end nowadays have both, so even the seasoned manual driver can choose the simpler option when it suits them.
If we apply the analogy to the application drivers for Neo4j, we have to concede they have been more like a manual transmission — offering the maximum amount of capability (with reactive sessions, flow control, and much more) — but at the cost of being more difficult to learn.
That’s about to change, as the drivers team at Neo4j is adding the equivalent of an automatic transmission mode to the APIs.
Summary
The drivers team has been working on simplifying the experience of new users getting started with Neo4j. The existing interfaces have not changed (you won’t have to change existing application code), but a new experience that builds on top of them is being introduced.
There’s a new path through the driver APIs using an Execute method (or ExecuteAsync to be idiomatic to .net) on the Driver object. The simplest call to the Neo4j database now looks like this (code samples here are in C#);
await _driver.ExecutableQuery("RETURN 1;").ExecuteAsync();
The Bigger Picture
The Neo4j drivers offer a great deal of control for use cases which can become pretty complex. Optimizing performance across highly variable architectures, while ensuring consistency and routing correctness can be a non-trivial exercise.
All this control can come at a cost though, in terms of complexity for the developer.
For some time, running a command against Neo4j from your application has involved understanding several (for some) novel concepts.
- Sessions, their configuration, and lifetime
- Transaction Functions
- Routing Control
- Transactions
- Bookmarks and Causal Chaining
- Result Cursors, Streaming Behavior, Lifetime of Results
There have been valiant efforts to capture the essentials in an accessible form, such as https://development.neo4j.dev/developer-blog/neo4j-driver-best-practices/
Still, apart from being a lot to take on board, it also involved quite a lot of… well… scaffolding. Even an apparently simple query execution is recommended to be written using an ‘explicit transaction function’.
It got worse, as some users were drawn toward a section of the API that seemed simpler, but didn’t provide retries for transient failures (as can occur for cloud databases, like Aura, where Neo4j’s fastest growth is happening).
The engineering team — who look after the Bolt protocol and server, as well as the 5 official language drivers — following research, embraced a challenge to reduce the number of concepts that users had to learn, along with the number of ‘inflection points’, in order to foster a user experience of ‘progressive discovery’ (i.e. you learn the complicated bits only when you need to do something complicated).
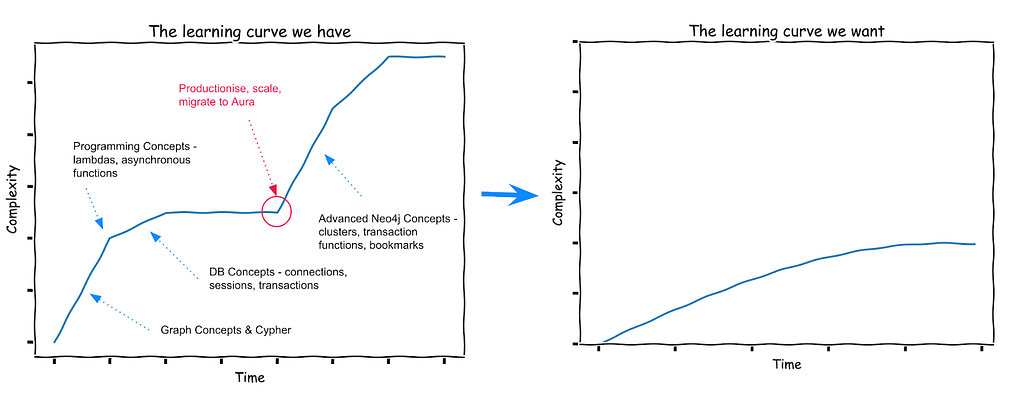
So they have built a path through the API that shields many of the more complex aspects from the user (while retaining them for the most sophisticated use cases, and for backward compatibility).
The new API allows the developer to acquire results from the database using some configuration defaults which we expect most users will choose in most cases anyway.
Changes include;
- Results are delivered to memory without requiring an additional step
- Session and Transaction objects are called by executeQuery automatically, so not exposed to the user. Retry behavior is the same, but without requiring lambdas or callbacks
- Bookmarks are passed automatically, so causal consistency does not require manual steps
- Configuration options are set by default but accessible for change using a QueryConfig object
Version 5.5 of the official drivers see the initial public release of these changes, for now under an ‘experimental’ tag.
To highlight the improvements that the new API introduces we will again use some C# code. Here is an example of two causally chained queries using the existing session-level interface, in the classic read-your-own-write scenario.
The two queries:
const string writeQuery = @"
MERGE (p1:Person { name: $person1Name })
MERGE (p2:Person { name: $person2Name })
MERGE (p1)-[:KNOWS]->(p2)";
const string readQuery = @"
MATCH (p:Person)
RETURN p";
The session API usage:
var _driver = GraphDatabase.Driver("localhost",
AuthTokens.Basic("user", "password"));
var savedBookmarks = new List<Bookmark>();
await using var session = driver.AsyncSession();
await session.ExecuteWriteAsync(async tx =>
{
var resultCursor = await tx.RunAsync(writeQuery,
new { personName1, personName2 });
await resultCursor.ConsumeAsync();
});
savedBookmarks.Add(session.LastBookmark);
await using var session2 = driver.AsyncSession(
o => o.WithBookmarks(savedBookmarks.ToArray()));
var records = await session2.ExecuteReadAsync(async tx =>
{
var resultCursor = await tx.RunAsync(readQuery);
return await resultCursor.ToListAsync();
});
Now, to highlight the differences, this is the same functionality implemented with the new driver-level API:
var _driver = GraphDatabase.Driver("localhost",
AuthTokens.Basic("user", "password"));
await _driver.ExecutableQuery(writeQuery)
.WithParameters(new { person1Name, person2Name })
.ExecuteAsync();
var readResults = await _driver.ExecutableQuery(readQuery)
.ExecuteAsync();
Note the reduction in code achieved by the driver handling a lot of tasks for you, such as bookmark management.
The default behaviors can be configured and overridden as needed, giving control to the developer as their requirements change. Should you need to have fine-grained control then you can move on or continue to use the session interface.
It is worth noting that this interface is idiomatic depending on the language. The Python code for example does not use a fluent API and slightly differing naming. Take a look at the examples in the linked GitHub discussions below for the language(s) of your choice.
Which one works best for you? Let us know at the links below.
So, What’s Next for the Simplified API?
After consultation and perhaps some tweaks, we’ll remove the experimental tags and promote the use of the API for new users.
Going forward, we think we can automatically detect whether your query might contain a write operation, so you don’t need to indicate AccessMode to optimize the distribution of reads and writes across clusters.
The team is also investigating object mapping from results into suitable application classes, and other ideas to reduce the need for boilerplate code and complexity.
We’d love to hear from you — check out the code samples and add to the discussion for your preferred language;
Java: https://github.com/neo4j/neo4j-java-driver/discussions/1374
Python: https://github.com/neo4j/neo4j-python-driver/discussions/896
.net: https://github.com/neo4j/neo4j-dotnet-driver/discussions/677
JavaScript: https://github.com/neo4j/neo4j-javascript-driver/discussions/1052
Go: https://github.com/neo4j/neo4j-go-driver/discussions/441
A New Steer for the (Neo4j) Drivers? was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles

Transform Static Risk Assessment Into a Dynamic Data-Driven Strategy
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI

Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces
