



Do you ever wonder what licenses you need for your Python project? Me too! So I made a tool to figure it out.
In short, every package has its license, but so do it’s dependencies and those dependencies’ dependencies. Creating a graph of dependencies is where Neo4j comes into play.
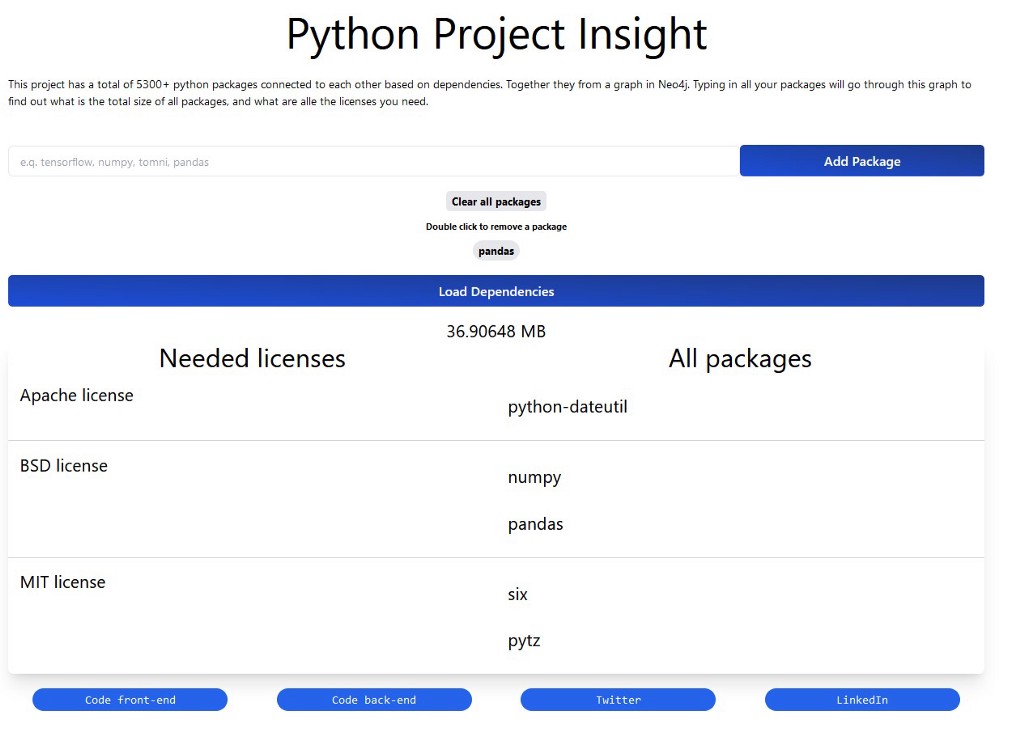
Example
Link: wagenrace.github.io/python_dep_frontend
As an example, with a project using only Pandas, it shows you that you need three licenses for Pandas and its five dependencies. The dependencies are direct or indirect.
Pandas does NOT require Six, but python-dateutil does.
Database
The data needs to be scraped, stored, and accessed.
Scraping
First the data needed to be scraped (code). Luckily every PyPi package has a special JSON page. For example, pypi.python.org/pypi/tomni/json holds the requires_dist, license, and package size.
Two design choices were made: every requirement with “extra ==” was ignored, and the biggest package size was always taken.
As a starting point, I used the hugovk project with the top 5,000 packages. An extra 315 appeared because some dependencies were not on the list.
The last step was manually combining different writings of the same license, given this lookup table.
For example, “3-clause bsd license” was written in 10 different ways:
- 3-clause bsd license
- bsd 3-clause
- bsd-3-clause
- 3-bsd
- bsd 3
- bsd (3-clause)
- bsd 3 clause
- 3-clause bsd <https://www.opensource.org/licenses/bsd-license.php>
- bsd 3-clause license
- 3-clause bsd
Storing the data
The data is connected and the connection is important to find all the dependencies. This means that graph databases form a very natural fit.
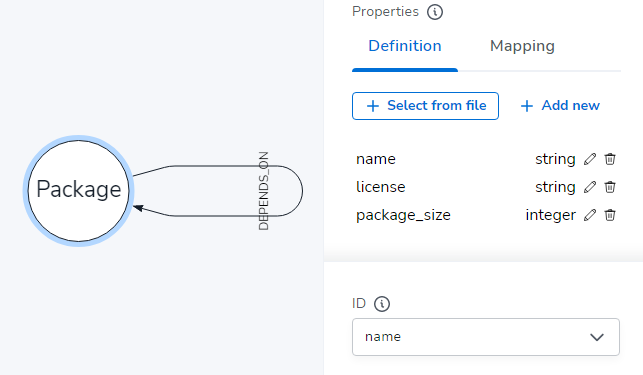
Using the data importer, I created a very simple model: packages can depend on other packages.
Licenses were not made into their own node because I did not want to find packages based on their license, and the free Aura Cloud had a limit (200k nodes/400k relationships) on the number of nodes that I wanted to use for packages!
PS: I did not use all the nodes (yet). Not even close. 5.317/200.000 were used.
Accessing
It will not surprise people to learn I like Python. So to set up a rest API, I used Fast-API (four licenses needed). And to access the Neo4j I use py2neo (four licenses needed).
These two together (five licenses needed) are the whole back-end hosted by dot-asterisk.
I used to fight with Cypher because it collected my packages per license. But this turned out to be a great feature!
The query looks for all the packages the start packages depend on with any number of packages in between.
This list is then DISTINCT (removing duplicates) and collected per license. The only downside is that the size in bytes is also collected per license. The front end can deal with that though.
MATCH (n:Package)-[:DEPENDS_ON*0..]->(m:Package) WHERE n.name in ["fastapi", "py2neo"] WITH DISTINCT m as p
RETURN DISTINCT p.license as licenses, collect(p.name) as packageNames, sum(p.package_size) as totalSizeBytes
Conclusion
The whole setup works, and now it’s very easy to find out what licenses are needed for your project (if your project only uses the 5,317 most downloaded packages).
I don’t know whether thinking about all the licenses you need is helpful or just another useless thing to worry about. However, there is now a tool for it!
Other findings
The most popular license is MIT (42 %), followed by Apache (Apache + Apache V2 = 26 %), then BSD (16 %), and then UNKNOWN (3 %).
Adding all licenses with GNU together (13 different names with V2, V3, GPL, LGPL, affero, ect.) is 6% of all licenses.
Python, Mozilla, and ISC licenses are all below 1%, yet still above “other/proprietary licenses.”
Python packages licenses analysis with Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.





