


Enhancing RAG with Neo4j Cypher and Vector Templates Using LangChain Agents

Data Scientist
13 min read

Combining Neo4j knowledge graphs, native vector search, and Cypher LangChain templates using LangChain agents for dynamic query handling and enhanced information retrieval.
In information retrieval, a significant challenge has been the lack of efficient agents capable of intelligently handling and routing queries. Traditional systems often struggle with dynamically processing complex queries, especially when dealing with vast and intricate data stored in the Neo4j vector and graph database. This limitation can lead to suboptimal retrieval results, hindering the full potential of AI applications in synthesizing and generating informed responses.
This solution effectively integrates LangChain templates of Neo4j graph chains, specifically the vector and graph Cypher templates, transforming these chains into tools that enable the agent to make informed decisions.
The Neo4j vector chain template allows you to balance precise embeddings and allows context retention by implementing advanced retrieval strategies.
The Neo4j Cypher chain template transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
This approach enables the agents to intelligently decide which chain or tool to use based on the question. By combining the strengths of Neo4j’s vector and graph capabilities, the system optimizes query processing and enhances the overall quality of information retrieval.
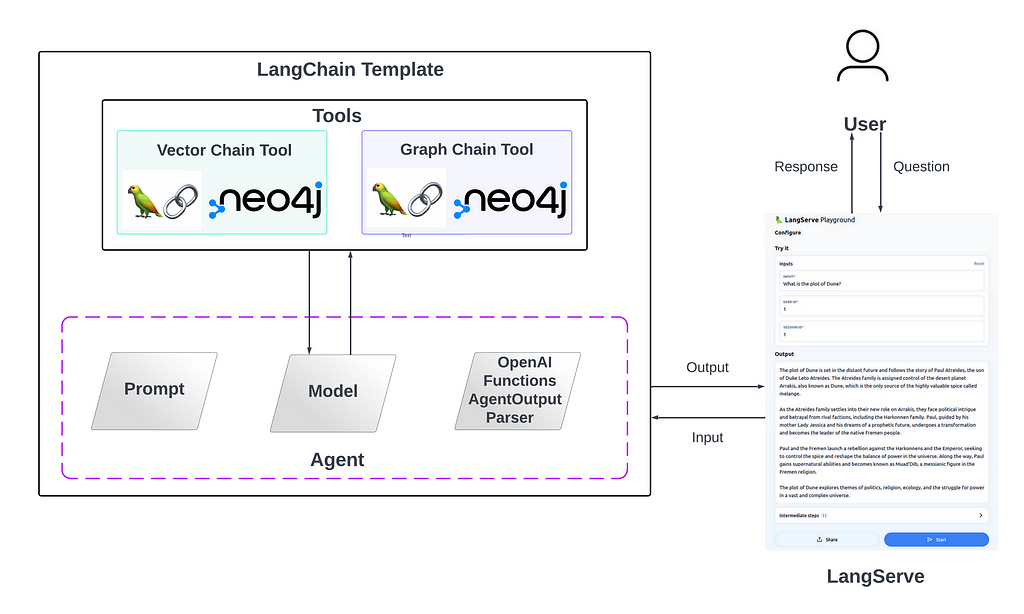
LangChain — Agents & Chains
LangChain agents use large language models to dynamically select and sequence actions, functioning as intelligent decision-makers in AI applications. These agents, powered by sophisticated reasoning, can evaluate inputs and context to determine the most effective course of action, enhancing the capabilities and adaptability of AI-driven processes.
Furthermore, chains are sequences of calls to components, acting as modular, configurable elements in workflows. They enable the integration of large language models with other components, offering versatility and efficiency in complex application scenarios.
In this project, it was an interesting challenge to integrate them both to enhance Retrieval Augmented Generation (RAG) applications. More specifically, agents evaluate user questions and decide on the best course of action. Agents can use chains as tools, conceptualized as a sequence of actions and functions.
Advanced Retrieval Strategies
The primary issue with naive vector similarity searches in traditional RAG approaches is their limited ability to accurately discern context and specific concepts in large documents.
That often leads to the retrieval of generalized or irrelevant information, reducing the effectiveness of responses. The advanced RAG strategies address these challenges by segmenting data into more meaningful units, allowing for targeted retrieval that is both contextually aware and conceptually precise.
1. Typical RAG:
– Traditional method where the exact data indexed is the data retrieved.
2. Parent retriever:
– Instead of indexing entire documents, data is divided into smaller chunks, referred to as Parent and Child documents.
– Child documents are indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
3. Hypothetical Questions:
– Documents are processed to generate potential questions they might answer.
– These questions are then indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
4. Summaries:
– Instead of indexing the entire document, a summary of the document is created and indexed.
– Similarly, the parent document is retrieved in a RAG application.
Learn more about advanced retrieval strategies in this other blog.
These strategies are incorporated in the implementation specifically for the vector RAG chain.
LangChain Templates
LangChain Template provides a collection of deployable reference architectures that simplify the creation and customization of chains and agents.
These templates are designed in a standard format for effortless integration with LangServe, facilitating production-ready APIs’ quick deployment and monitoring (with LangSmith). This framework accelerates the development process and enables a broad range of users to share, maintain, and enhance AI functionalities easily.
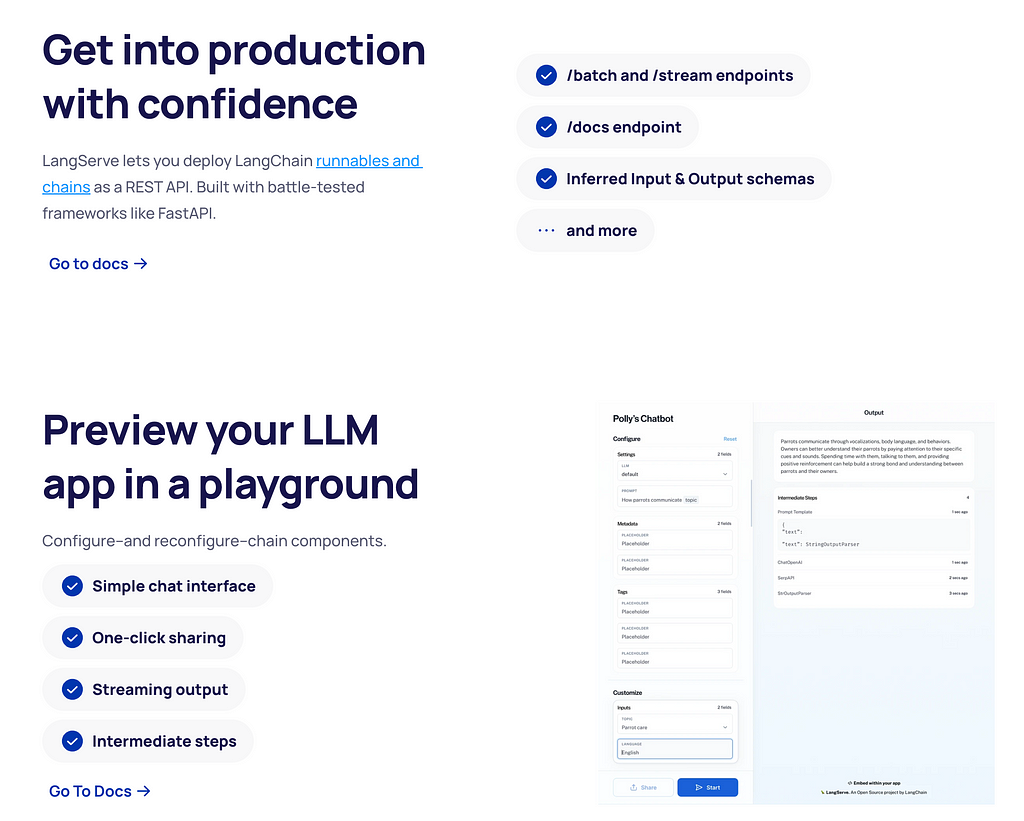
For example, I reused the neo4j-advanced-rag template to build this application, which allows you to balance precise embeddings and context retention by implementing advanced retrieval strategies recently integrated into LangChain by Tomaz Bratanic.
Similarly, you can use my template, specifically my agent, and build upon it or integrate it into your existing application.
Implementation
Here, I will display important code and abstract out unimportant code. Refer to my GitHub repo for the complete code you can deploy to LangServe.
towards-agi/knowledge graphs/neo4j-rag/my-app at main · sauravjoshi23/towards-agi
Retrievers.py
This file contains code for retrieving data from the Neo4j vector index using different retrieval strategies. It is essentially used in a chain — a prompt is passed to the retriever (which contains conversation history and the user question) and, when invoked, retrieves data from a specific retrieval strategy’s index.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Neo4jVector
# Typical RAG retriever
typical_rag = Neo4jVector.from_existing_index(
OpenAIEmbeddings(), index_name="typical_rag"
)
# Parent retriever
parent_query = """
MATCH (node)<-[:HAS_CHILD]-(parent)
WITH parent, max(score) AS score // deduplicate parents
RETURN parent.text AS text, score, {} AS metadata LIMIT 1
"""
parent_vectorstore = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
index_name="parent_document",
retrieval_query=parent_query,
)
# Hypothetic questions retriever
hypothetic_question_query = """
MATCH (node)<-[:HAS_QUESTION]-(parent)
WITH parent, max(score) AS score // deduplicate parents
RETURN parent.text AS text, score, {} AS metadata
"""
hypothetic_question_vectorstore = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
index_name="hypothetical_questions",
retrieval_query=hypothetic_question_query,
)
# Summary retriever
summary_query = """
MATCH (node)<-[:HAS_SUMMARY]-(parent)
WITH parent, max(score) AS score // deduplicate parents
RETURN parent.text AS text, score, {} AS metadata
"""
summary_vectorstore = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
index_name="summary",
retrieval_query=summary_query,
)
History.py
This file features a conversational memory module that stores the dialogue history in the Neo4j graph database. The conversation memory is uniquely maintained for each user session, ensuring personalized interactions. I tried to merge these functions into one, but some intricate details were involved in the input to these functions, maybe due to the difference in the index.
from typing import Any, Dict, List, Union
from langchain.graphs import Neo4jGraph
from langchain.memory import ChatMessageHistory
from langchain.schema import AIMessage, HumanMessage
graph = Neo4jGraph()
def convert_messages(input: List[Dict[str, Any]]) -> ChatMessageHistory:
history = ChatMessageHistory()
for item in input:
history.add_user_message(item["result"]["question"])
history.add_ai_message(item["result"]["answer"])
return history
def get_vector_history(input: Dict[str, Any]) -> List[Union[HumanMessage, AIMessage]]:
# Lookback conversation window
window = 3
data = graph.query(
"""
MATCH (u:User {id:$user_id})-[:HAS_SESSION]->(s:Session {id:$session_id}),
(s)-[:LAST_MESSAGE]->(last_message)
MATCH p=(last_message)<-[:NEXT*0.."""
+ str(window)
+ """]-()
WITH p, length(p) AS length
ORDER BY length DESC LIMIT 1
UNWIND reverse(nodes(p)) AS node
MATCH (node)-[:HAS_ANSWER]->(answer)
RETURN {question:node.text, answer:answer.text} AS result
""",
params=input,
)
history = convert_messages(data)
return history.messages
def save_vector_history(input: Dict[str, Any]) -> str:
input["context"] = [el.page_content for el in input["context"]]
# print(input)
has_history = bool(input.pop("chat_history"))
# store history to database
if has_history:
graph.query(
"""
MATCH (u:User {id: $user_id})-[:HAS_SESSION]->(s:Session{id: $session_id}),
(s)-[l:LAST_MESSAGE]->(last_message)
CREATE (last_message)-[:NEXT]->(q:Question
{text:$question, rephrased:$rephrased_question, date:datetime()}),
(q)-[:HAS_ANSWER]->(:Answer {text:$output}),
(s)-[:LAST_MESSAGE]->(q)
DELETE l
WITH q
UNWIND $context AS c
MATCH (n) WHERE elementId(n) = c
MERGE (q)-[:RETRIEVED]->(n)
""",
params=input,
)
else:
graph.query(
"""MERGE (u:User {id: $user_id})
CREATE (u)-[:HAS_SESSION]->(s1:Session {id:$session_id}),
(s1)-[:LAST_MESSAGE]->(q:Question
{text:$question, rephrased:$rephrased_question, date:datetime()}),
(q)-[:HAS_ANSWER]->(:Answer {text:$output})
WITH q
UNWIND $context AS c
MATCH (n) WHERE elementId(n) = c
MERGE (q)-[:RETRIEVED]->(n)
""",
params=input,
)
# Return LLM response to the chain
return input["output"]
def get_graph_history(input: Dict[str, Any]) -> ChatMessageHistory:
input.pop("question")
# Lookback conversation window
window = 3
data = graph.query(
"""
MATCH (u:User {id:$user_id})-[:HAS_SESSION]->(s:Session {id:$session_id}),
(s)-[:LAST_MESSAGE]->(last_message)
MATCH p=(last_message)<-[:NEXT*0.."""
+ str(window)
+ """]-()
WITH p, length(p) AS length
ORDER BY length DESC LIMIT 1
UNWIND reverse(nodes(p)) AS node
MATCH (node)-[:HAS_ANSWER]->(answer)
RETURN {question:node.text, answer:answer.text} AS result
""",
params=input,
)
history = convert_messages(data)
return history.messages
def save_graph_history(input):
input.pop("response")
# store history to database
graph.query(
"""MERGE (u:User {id: $user_id})
WITH u
OPTIONAL MATCH (u)-[:HAS_SESSION]->(s:Session{id: $session_id}),
(s)-[l:LAST_MESSAGE]->(last_message)
FOREACH (_ IN CASE WHEN last_message IS NULL THEN [1] ELSE [] END |
CREATE (u)-[:HAS_SESSION]->(s1:Session {id:$session_id}),
(s1)-[:LAST_MESSAGE]->(q:Question {text:$question, cypher:$query, date:datetime()}),
(q)-[:HAS_ANSWER]->(:Answer {text:$output}))
FOREACH (_ IN CASE WHEN last_message IS NOT NULL THEN [1] ELSE [] END |
CREATE (last_message)-[:NEXT]->(q:Question
{text:$question, cypher:$query, date:datetime()}),
(q)-[:HAS_ANSWER]->(:Answer {text:$output}),
(s)-[:LAST_MESSAGE]->(q)
DELETE l) """,
params=input,
)
# Return LLM response to the chain
return input["output"]
Neo4j_vector.py
This code alone is a standalone template in LangChain, which performs RAG using Neo4j vector index.
For my project, I treat this chain as a tool that is eventually passed to an agent for decision-making. The description for this tool is straightforward — ’Useful Tool for retrieving specific context about Dune.’
- The chain first retrieves data from memory and uses the user question to rephrase the original question using the CONDENSE_QUESTION_PROMPT prompt template.
- Next, it uses the rephrased question to retrieve data from the Neo4j vector index and passes it as context to the ANSWER_PROMPT.
- Finally, we use the ANSWER_PROMPT, which contains the system message instruction, context, conversation history, and user question to output a contextually relevant answer.
from operator import itemgetter
from typing import Optional, Type
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, PromptTemplate, MessagesPlaceholder
from langchain.pydantic_v1 import BaseModel
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import ConfigurableField, RunnablePassthrough
from neo4j_advanced_rag.history import get_vector_history, save_vector_history
from langchain.tools import BaseTool
from pydantic import BaseModel, BaseSettings
from typing import Type, Any
from neo4j_advanced_rag.retrievers import (
hypothetic_question_vectorstore,
parent_vectorstore,
summary_vectorstore,
typical_rag,
)
class Question(BaseModel):
question: str
user_id: str
session_id: str
class VectorTool(BaseTool, BaseSettings):
name = "vector_tool"
description = "Useful Tool for retrieving specific context about Dune"
args_schema: Type[Question] = Question
def _run(self, question, user_id, session_id):
retriever = typical_rag.as_retriever().configurable_alternatives(
ConfigurableField(id="strategy"),
default_key="typical_rag",
parent_strategy=parent_vectorstore.as_retriever(),
hypothetical_questions=hypothetic_question_vectorstore.as_retriever(),
summary_strategy=summary_vectorstore.as_retriever(),
)
# Define LLM
llm = ChatOpenAI()
# Condense a chat history and follow-up question into a standalone question
condense_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
Make sure to include all the relevant information.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:""" # noqa: E501
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(condense_template)
# RAG answer synthesis prompt
answer_template = """Answer the question based only on the following context:
<context>
{context}
</context>"""
ANSWER_PROMPT = ChatPromptTemplate.from_messages(
[
("system", answer_template),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{question}"),
]
)
chain = (
RunnablePassthrough.assign(chat_history=get_vector_history)
| RunnablePassthrough.assign(rephrased_question=CONDENSE_QUESTION_PROMPT | llm | StrOutputParser())
| RunnablePassthrough.assign(context=itemgetter("rephrased_question") | retriever)
| RunnablePassthrough.assign(output=ANSWER_PROMPT | llm | StrOutputParser())
| save_vector_history
).with_types(input_type=Question)
return chain.invoke(
{
"question": question,
"user_id": user_id,
"session_id": session_id,
},
{"configurable": {"strategy": "typical_rag"}} #todo
)
Neo4j_cypher.py
The overall structure of this tool is very similar to that of the vector tool. It transforms a natural language question into a Cypher query (used to fetch data from Neo4j databases), executes the query, and provides a natural language response based on the query results.
The description used for this tool is “Useful Tool for retrieving structural, interconnected and relational knowledge related to Dune.”
However, one component in the chain is exciting — CypherQueryCorrector, which essentially validates and fixes the relationship direction in Cypher statements based on the given schema.
from langchain.chains.graph_qa.cypher_utils import CypherQueryCorrector, Schema
from langchain.chat_models import ChatOpenAI
from langchain.graphs import Neo4jGraph
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.pydantic_v1 import BaseModel
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from typing import Type
from neo4j_advanced_rag.history import get_graph_history, save_graph_history
from langchain.tools import BaseTool
class Question(BaseModel):
question: str
user_id: str
session_id: str
class GraphTool(BaseTool):
name = "graph_tool"
description = "Useful Tool for retrieving structural, interconnected and relational knowledge related to Dune"
args_schema: Type[Question] = Question
def _run(self, question, user_id, session_id):
# Connection to Neo4j
graph = Neo4jGraph()
# Cypher validation tool for relationship directions
corrector_schema = [
Schema(el["start"], el["type"], el["end"])
for el in graph.structured_schema.get("relationships")
]
cypher_validation = CypherQueryCorrector(corrector_schema)
# LLMs
cypher_llm = ChatOpenAI(model_name="gpt-4", temperature=0.0)
qa_llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.0)
# Generate Cypher statement based on natural language input
cypher_template = """This is important for my career.
Based on the Neo4j graph schema below, write a Cypher query that would answer the user's question:
{schema}
Question: {question}
Cypher query:""" # noqa: E501
cypher_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input question, convert it to a Cypher query. No pre-amble.",
),
MessagesPlaceholder(variable_name="history"),
("human", cypher_template),
]
)
cypher_response = (
RunnablePassthrough.assign(schema=lambda _: graph.get_schema, history=get_graph_history)
| cypher_prompt
| cypher_llm.bind(stop=["nCypherResult:"])
| StrOutputParser()
)
# Generate natural language response based on database results
response_template = """Based on the the question, Cypher query, and Cypher response, write a natural language response:
Question: {question}
Cypher query: {query}
Cypher Response: {response}""" # noqa: E501
response_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input question and Cypher response, convert it to a "
"natural language answer. No pre-amble.",
),
("human", response_template),
]
)
chain = (
RunnablePassthrough.assign(query=cypher_response)
| RunnablePassthrough.assign(
response=lambda x: graph.query(cypher_validation(x["query"])),
)
| RunnablePassthrough.assign(
output=response_prompt | qa_llm | StrOutputParser(),
)
| save_graph_history
).with_types(input_type=Question)
return chain.invoke(
{
"question": question,
"user_id": user_id,
"session_id": session_id,
}
)
Agent.py
Now that we have defined the vector and the graph tool, the definition of an agent becomes straightforward.
We convert these tools to OpenAI functions to leverage the efficient function-calling functionality of OpenAI. A function call is an interesting feature as it allows to pass the Pydantic class and returning structured output, which is better for further processing (Imagine if an LLM returned output in a different structure every time; wouldn’t it be challenging to process it).
from pydantic import BaseModel, Field
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.pydantic_v1 import BaseModel
from langchain.chat_models import ChatOpenAI
from langchain.agents import AgentExecutor
from langchain.tools.render import format_tool_to_openai_function
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools import tool
from langchain.agents import AgentExecutor
from neo4j_advanced_rag.neo4j_vector import VectorTool
from neo4j_advanced_rag.neo4j_cypher import GraphTool
from langchain.schema.runnable import ConfigurableField
from neo4j_advanced_rag.retrievers import (
hypothetic_question_vectorstore,
parent_vectorstore,
summary_vectorstore,
typical_rag,
)
class AgentInput(BaseModel):
input: str
user_id: str
session_id: str
llm = ChatOpenAI()
vector_tool = VectorTool()
graph_tool = GraphTool()
tools = [vector_tool, graph_tool]
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
assistant_system_message = """You are a helpful assistant.
Use one of the tools provided to you if necessary."""
prompt = ChatPromptTemplate.from_messages(
[
("system", assistant_system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = (
{
"input": lambda x: x["input"],
"user_id": lambda x: x["user_id"],
"session_id": lambda x: x["session_id"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
)
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools).with_types(input_type=AgentInput)
agent_executor = agent_executor | (lambda x: x["output"])
Result
to run the application and see it running on LangServe, run langchain serve command in the root of your project directory.
This approach can be effective when you have different data stored in vector and graph indexes or have excellent descriptions of tools to invoke by the agent. However, my goal was to get a good understanding of the entire project so that I could quickly relate to it when I worked on a similar project.
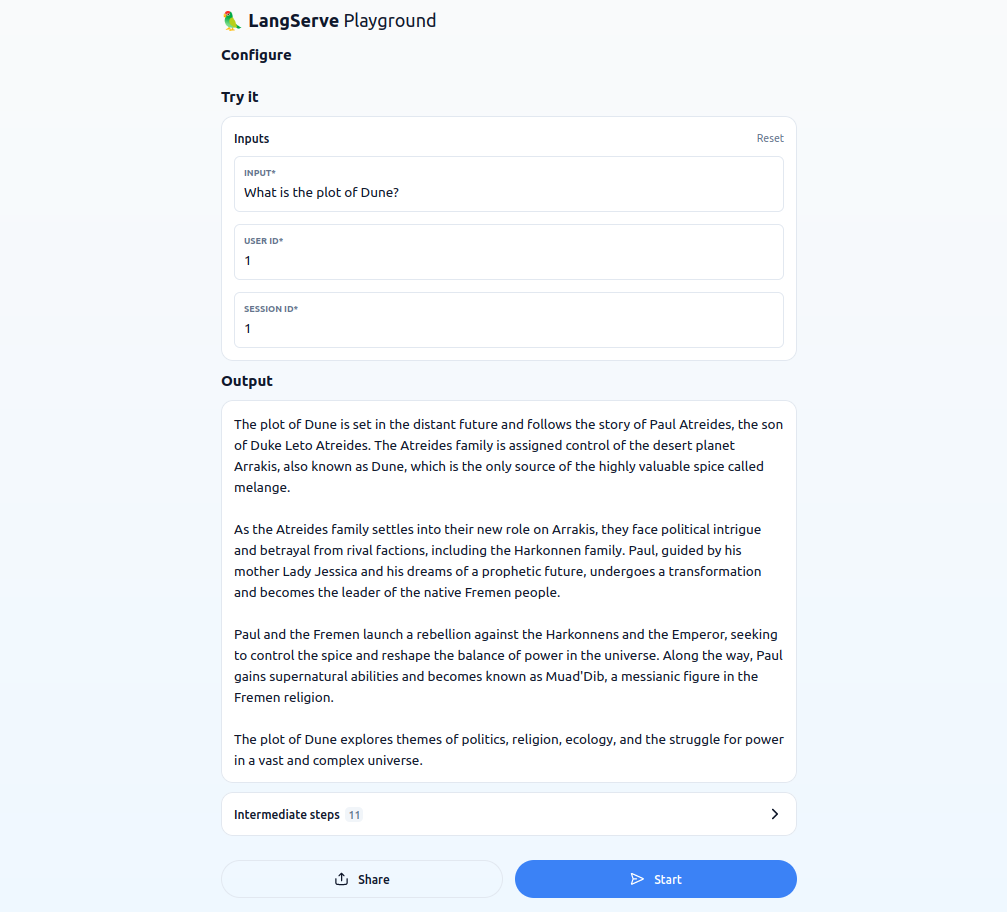
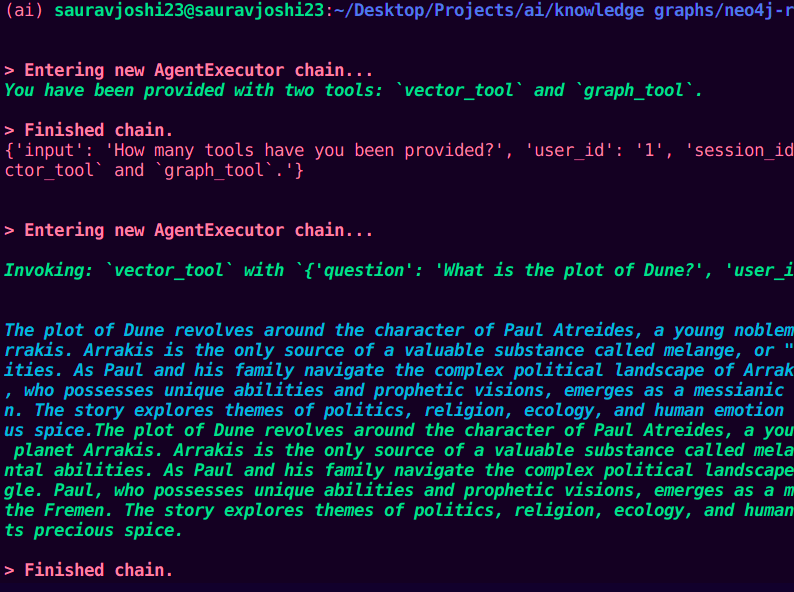
For demonstration purposes, I fed two questions to the agent executor to invoke one of the tools. Here is a sample response.
How many tools have you been provided?
Can you please use this tool and answer what is the plot of Dune?
Future Work
- I worked hard to pass the user_id and session_id as arguments from agents to the chain tools, but I was unsuccessful in doing that.
- The dynamic selection of the retriever for the vector index is here again. I faced the same issue of passing the selected retriever to the Vector tool.
Summary
This project integrates Neo4j graph databases with LangChain agents, using vector and Cypher chains as tools for effective query processing.
The system employs advanced retrieval strategies, enhancing the precision and relevance of information extracted from both vector and graph databases. It features a conversational memory module, ensuring each user interaction is contextually informed.
The agents, equipped with these tools, make informed decisions about which retrieval method to use based on the query. This approach optimizes the balance between retrieving specific data and maintaining overall context.
The implementation is straightforward, focusing on practical utility and adaptability for different data types. The project aims to improve the efficiency and accuracy of AI-driven data retrieval and processing.
References
- Implementing advanced RAG strategies with Neo4j
- LangChain Templates
- Enhanced QA Integrating Unstructured Knowledge GraphUsing Neo4j and LangChain
- Construct Knowledge Graphs From Unstructured Text
- Constructing knowledge graphs from text using OpenAI functions: Leveraging knowledge graphs to power LangChain Applications
Enhancing RAG with Decision-Making Agents and Neo4j Tools Using LangChain Templates and LangServe was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article


Explore
Related Articles
LLM Knowledge Graph Builder Back-End Architecture and API Overview
Build an Intelligent Movie Search With Neo4j and Vertex AI

Neo4j and Google Distributed Cloud: Bringing Graph Technology to Air-Gapped Environments

Google Cloud & Neo4j: Teaming Up at the Intersection of Knowledge Graphs, Agents, MCP, and Natural Language Interfaces

